Abstract
背景:目前的语法分析技术会遇到以下困难1. 难以嵌入带有副作用的actions 2. 速度慢 3. 有二义性 4. 匹配策略违反直觉
本文:介绍ALL(*)分析技术,对应ANTLR v4
特点:
- 简单,高效,有常规topdown LL(k)parsers的预测能力,也有GLR类型文法的决策能力
- 虽然理论上是O(n4)的,但是实践时常是线性复杂度
- 在解析的时候就做语法分析
适应范围:所有CFG
- 对带左递归的文法,需要改写
- 对不带左递归的文法,可以密切分析
效果:
比GLL和GLR有量级提升
Intro
LL(*)缺点:1. 无法静态确定语法条件 2. 有时无法找到能区分语法规则选项肢的DFA
1.1 Dynamic grammar analysis
P1:
ALLstar用类似GLR的机制来解析。具体来说,LL解析在每个决策点,也就是说,在每个非终端符号上,都会暂停,等到决定出具体走哪条production之后才会接着拓展。
关键点:将语法分析转移到解析阶段,不做静态语法分析
静态分析需要考虑全部可能的序列,但是动态分析只需要考虑见到的那部分有限输入语句集合即可
P2:
ALLstar的主要思路是在每个决策点(每个非终端符号上)为每个选择肢都建立一个subparser,这些subparser以伪并行的方式执行直到只有一个subparser还能接着匹配。如果有多个subparser都能匹配,那么ANTLR4会先报告二义性,再选择优先级最高的production进行拓展。
程序员也可以使用semantic predicates来避免一部分二义性问题
P3:
ALLstar解析器会记住分析结果,动态维护一个DFA的缓存,这样可以加速决策过程。
不在缓存里的陌生输入会激发语法分析机制,在预测选择哪个选择肢的同时,还会用来更新DFA缓存。
DFA很适合用来存储预测结果(Q: despite the fact that the lookahead language at a given decision typically forms a CFG)。
P4:
为了尽量避免nondeterminstic带来的指数级潜在复杂度,本文使用图结构的栈(graph-structured stack, GSS)来做预测,
和GLR的差别:
ALLstar和GLR的策略几乎一致,但是GLR会直接做解析,ALLstar只是预测该走哪条production就截止。
ALLstar不一定会把终端符放进GSS,但是GLR一定会放
P5:
ALLstar的时间复杂度是O(n4),因为检查单个符号最多可以到达O(n2)的时间复杂度,不过,在时间上时间复杂度可以仅为O(n2)
P6:
ALLstar将语法分析移到解析阶段来做的策略导致了语法功能测试(grammar functional testing)的额外负担。
grammar functional testing中,程序员通常试图尽量覆盖尽可能多的grammar position和输入序列组合,以此找到二义性和未处理的情况
P7:
介绍ANTLR4
P8:
文章结构
2 ANTLR4
- 接受不包含间接左递归(A->B, B->A)和隐藏左递归(A->BA, B->episilon)的其他全部CFG作为输入。
- 能够生成多种语言的parser,包括java和C#
- 使用类似yacc语法,支持EBNF的operators
- ANTLR4 grammars can be scannerless and composable because ALLstar languages are closed under union,便于模块化
- 程序员能够嵌套具有副作用的actions(mutators)。当然,在推测阶段,这些mutators不会被激发。
- 支持semantic predicates,即无副作用的返回布尔值的表达式,用来确定某个production是否可行
- 能用来检测parse stack和input context
2.1 sample grammar
ANTLR3和ANTLR4区别

- 允许rule expr左递归
- 对于state: expr '=' 和state: expr ';'两个分支,ANTLR3会检测到recursion,然后启动backtracking
- ANTLR4加入了semantic predicates
2.2 Left-recursion removal
采用语法重写技术。
出于工程考虑,不支持间接左递归和隐藏左递归
2.3 Lexical analysis with ALLstar
ANTLR中分词是直接用了GLR类似的方法,动态分析并且直接开始解析,而不是只用动态分析来决定走哪个production
Q: (没有搞清楚因果关系) The key difference is that ALLstar lexers are predicated context-free grammars not just regular expressions so they can recognize context-free tokens such as nested comments and can gate tokens in and out according to semantic context

ANTLR也很适合Scannerless Parsing,用于处理上下文敏感的分词问题,比如混合C和SQL语法
3. Intro to ALLstar Parsing
P1:
ALLstar和LLk以及LLstar文法不同,会尽量选择第一个可以解析的production。
P2:
解析器会动态增量为每个非终端符号都创建一个lookahead DFA,来预测当前输入应当匹配哪一条production。实验证明大多数解析都能够利用到这个cache DFA
P3:

ALLstar和传统的topdown LL文法解析的过程基本一致,只是多了一个函数调用 adaptivePredict,用于构筑lookahead DFA,而不是仅仅把lookahead tokens和候选tokens做静态对照
adaptivePredict输入参数: 1. 当前非终端符 2. parser call stack 返回: 可用的production编号,如果没有可用production,会抛出异常
P4:
与NFA-DFA subset construction进行类比
ALLstar DFA state是匹配完毕到达这个状态的输入之后的parser configurations

这里,ALLstar用augmented recursive transition network(ATN)来模拟语法结构
P5:
ATN configuration代表子解析器的执行状态,用来追踪ATN的状态。
ATN configuration=(p, i, γ),这里p是ATN state, i是预测中production编号,γ是ATN subparser call stack。
与静态LLstar分析不同,ALLstar只用已经出现的lookahead sequence来建立DFA
P6-P7:
AdaptivePredict步骤
- 创建初始状态D0
- (以Fig3为例) 添加ATN configuration (p, 1, []), (q, 2, []),分别对应编号为1和2的两个选项肢
- 为每个匹配了lookahead symbol之后能够到达的状态建个新状态,再建对应的边
- 消耗ATN configuration,直到走到(-,i,-)为止(或者只有一个production可用)
这里,如果是已经走过的路,就直接用而无需模拟,如果是没有走过的,就启用ATN模拟并且记录
Q: 这里是否记录没有接受当前input sequence但是ATN模拟走过的路?
- 猜测: 不会接受
Q: Targeting existing states is how cycles can appear in the DFA
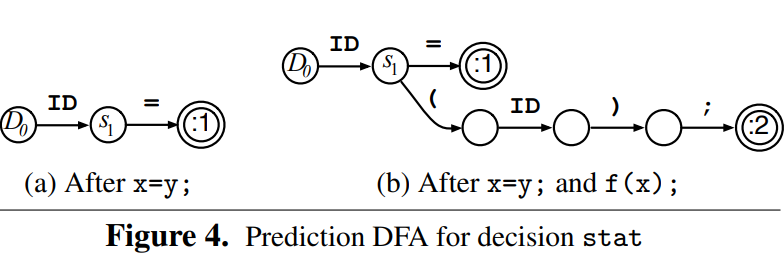
3.1 Predictions sensitive to the call stack
P1:
为了支持几乎所有CFG文法,ALLstar必须要考虑stack-sensitive prediction
例如,java method就需要根据自己是否在interface或者method中决定不同的行为。
例2:
S → xB | yC, B → Aa, C → Aba, A → b | epsilon
这里对于lookahead序列ba来说,到底是走A->b还是A->epsilon与S->xB还是x->yC有关
P2:
无需parser call stack的解析器被称为Strong LL parsers。LL常常被默认地限制为SLL文法。
P3:
为每种callstack都建立一个DFA不现实,ANTLR利用大部分解析都对应SLL文法production的特点,无视callstack来建立DFA。
如果找到了prediction conflict,为了进一步确认DFA找到的到底是二义性还是无视parser call stack导致的,adaptivePredict会重新检查一遍lookahead,这个时候会考虑parser stack,本文称为Two-stage ALLstar parsing,能加速解析8倍。
3.2 Two-stage ALLstar parsing
先用SLLmode进行parse,然后再试LL mode
4 Predicated grammars, ATNs and DFA



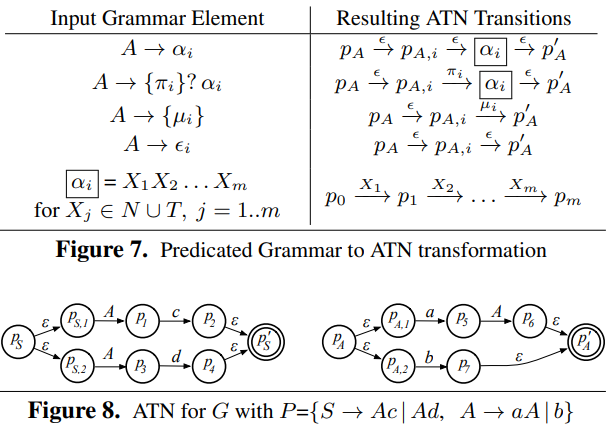

5 ALLstar parsing algo
5.1 Graph-structured call stacks
对于两个在state p的子解析器来说,qγ1和qγ2的行动在q出栈之前都是一致的,所以可以利用这个性质,将configuration(p, i, γ1)和(p, i, γ2)合并为新的(p,i,Tao)
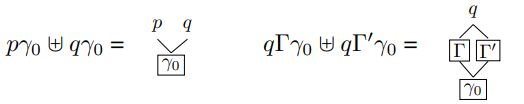
5.2 ALLstar parsing functions





5.3 Conflict and ambiguity detection


6 Theoretical results
Theorem 6.1. (Correctness). The ALLstar parser for non-leftrecursive G recognizes sentence w iff w ∈ L(G).
Theorem 6.2. ALLstar languages are closed under union.
Theorem 6.3. ALLstar parsing of n symbols has O(n4) time.
Theorem 6.4. A GSS has O(n) nodes for n input symbols.
Theorem 6.5. Two-stage parsing for non-left-recursive G recognizes sentence w iff w ∈ L(G).
7 Empirical results
7.1 Comparing ALL star's speed to other parsers
竞品:
hand-tuned recursive-descent with precedence parsing, LL(k), LL(*), PEG, LALR(1), ALL(*), GLR, and GLL
实验数据: 12920 Java6源文件

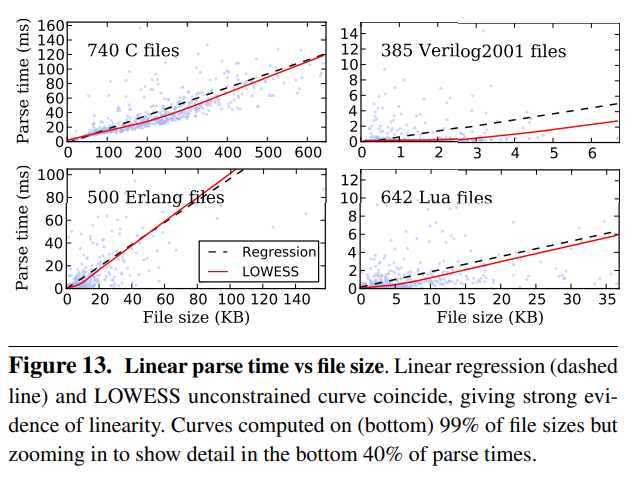
7.2 ALLstar performance across languages
实验数据: 8种语言,C,Java, Verilog2001, JSON, DOT, Lua, XML, Erlang
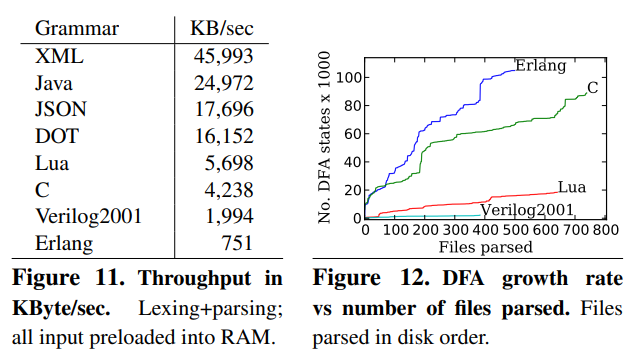
7.3 Effect of lookahead DFA on performance
7.4 Empirical parse-time complexity