Angora
Abstract
背景: 符号执行能够产生效果不错的测试样例,但是速度太慢了
工具: Angora
特点: 不用符号执行就解决路径约束
目的:增加branch coverage
技术:
- 规模化byte层级的污点分析
- 上下文敏感的分支计数
- 基于梯度下降的搜索
- 探索输入长度
实验:
A: LAVA-M数据集: - 找到了几乎所有注入的bugs
- 比其他竞品软件找到的bugs数目都多
- 找到了103个之前没能激发的bug
B: 八个成熟的开源项目 - 在file, jhead, nm, objdump和size中分别找6,52,29,40,48个bugs
1. Intro
P1: 叙述背景:符号执行过重,简单变异大多执行无效
Angora对策:避免符号执行,不用重量级的程序分析,coverage-guided
P2: 介绍AFL
- Context-sensitive branch coverage: 效果-能够更快地探索更多种程序状态
- Scalable byte-level taint tracking: 方式-只mutate和某个分支相关的byte
- Search based on gradient descent: 效果-更快的找到满足某个path constaint的结果
- Type and shape inference: 方式-多个被视作同个变量值的bytes将会被视作一个group并且推测类型
- Input length exploration: 背景-符号执行和梯度下降做不到增长input length; 方式-检测后增加input length
P3: 实验
2. Background
P1: 介绍AFL: 轻量级插桩,遗传算法,coverage-guided
2.1 Branch Coverage
P1: path trace table: 编译时插桩,该表对每个run记录一次,具体来说对每个branch计算h(lprev, lcur),然后在对应的hashtable中记录hitcnt
P2: global branch coverage table: 该表对全部run都记录,这里将hitcnt用8-bit vector表示,分别对应hitcnt是否出现在某个区间内: [1], [2], [3], [4,7], [8,15], [16,31], [32, 127], [128, +无穷)
P3: AFL认为找到了程序的新状态:
- 发现了新的branch
- 某个branch的hitcnt不同于global branch coverage table中记录的
2.2 Mutation Strategies
AFL变异策略
- bit or byte flips
- 设置interesing bytes
- 在bytes, words, dwords上加/减一个小值
- 为单个byte放入随机数
- 删/重复/置零一块block
- 将两个种子随机组合
3. Design
3.1 Overview
P1: 背景: AFL没有考虑call context->无法充分探索程序状态:本文context-sensitive branch coverage
P2: Angora's fuzzing loop介绍

关键技术:
- Section 3.3: 只变异某个条件分支对应的关键bytes
- Section 3.4: 确定关键bytes之后,用梯度下降来快速找到满足条件的值
- Section 3.5: 推测哪些bytes是一组,然后推测这组bytes到底是什么类型
- Section 3.6: 大部分fuzzers使用ad hoc方法来改输入长度,但是Angora用插桩来直接检测何时input长度不足。
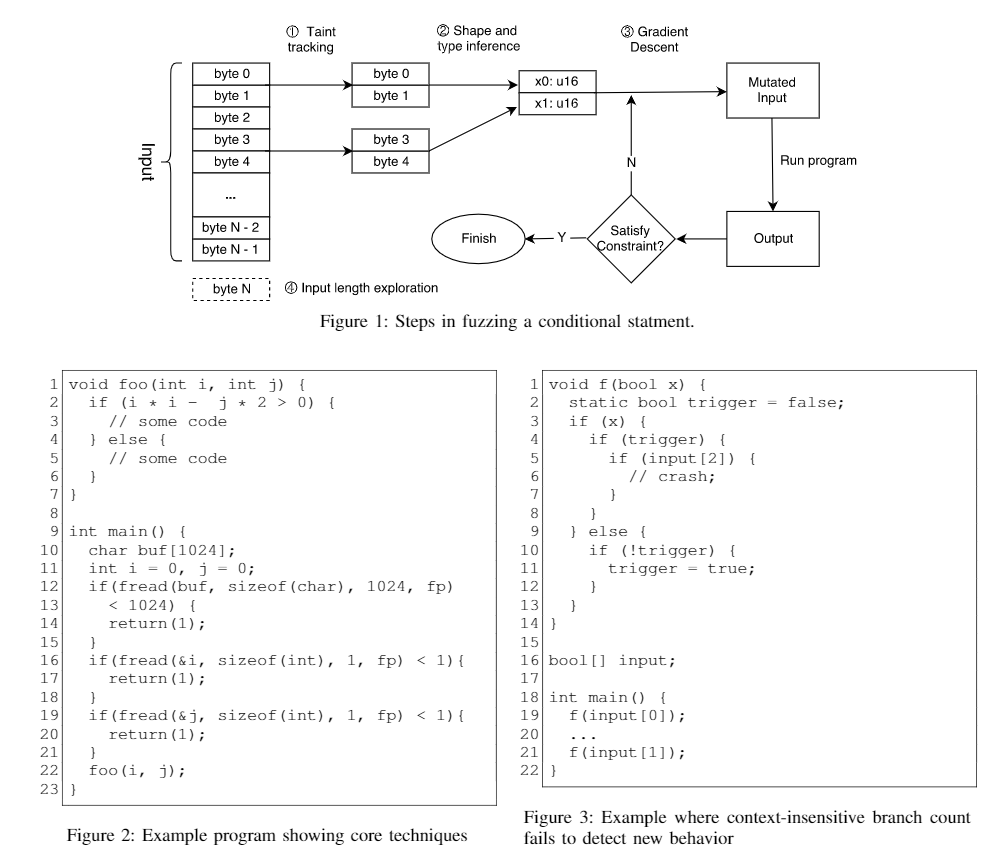
P3: 引入Fig1和Fig2,Fig1中有关键步骤,用Fig2中的程序作为关键步骤的示例。注意这里提到了为了计算偏导数必须要推测bytes的可能类型
3.2 Context-sensitive branch count
P1: 介绍AFL的global branch coverage table的好处:节约空间,此外不同区间也进行了行为细分
P2: 用例子介绍该方法的限制-没法区分calling context
P3: Angora考虑了calling context,通过将h(lprev, lcur)拓展为h(lprev, lcur, stack),这里stack是调用栈,比如[f19,f21],代表第21个call site调用了第19个call site进而到达目前所在的branch。考虑到深度回调法神的时候,stack会很深,这里计算stack的hash方式是异或以此控制hash值总数目。table7显示在LAVA-M上只增长了7倍branch数目。
3.3 Byte-level taint tracking
P1: 为了探索unexplored branches,angora需要实现byte-level taint tracking。本文认为,并不需要在全部runs上面都做taint analysis,为此,Angora只对种子(不是变异后的测试样例)上面跑一次taint analysis,以此来节约时间
P2: Angora taint label的数据结构是经过特殊设计的;简单的想法可能是将taint label设计为bit vector,每个bit代表输入中的一个位置,但是这样实现是无法支持很大的test case的。
P3: Angora将taint label信息存在一个table中,这个table要能支持INSERT(b), FIND(t)和UNION(tx, ty)操作,


