Replication
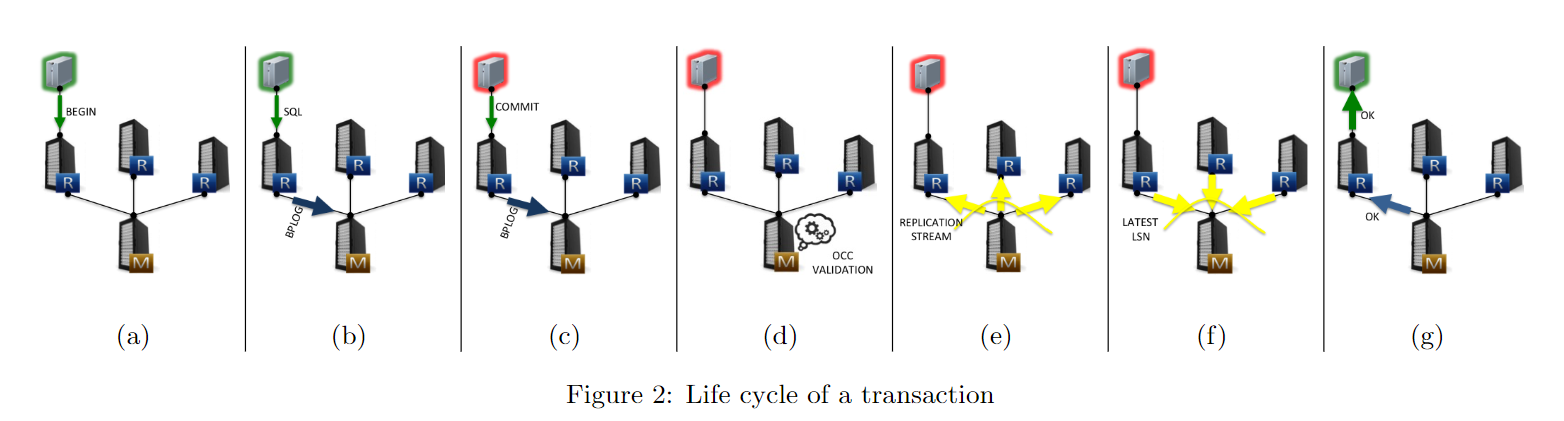
Comdb2上的每个事务都要经过如下过程:
a. 客户端连接地理最近的replicant(一般来说会在一个数据中心里)
b. 在这个replicant中,做全部transaction交互阶段的工作,包括SELECT,INSERT,UPDATE,DELETE操作。这时不需要lock。在这个阶段,写操作会被记录到bplog上,以供之后执行和验证。bplog将不断被运送到主机并且被缓存起来。
c. 客户端commit。
d. master开始2PL。首先执行写操作,并且检查读写冲突和写写冲突。
e. master生成描述改变的物理日志记录,然后保存到本地日志和网络
f. 处理结束,bplog中的事务释放锁。master同步等待所有Replicate返回确认后,回复最初的db node的被阻塞的session。
g. master回复后,该节点响应原始应用程序。
分布式SQL
Comdb2能允许任何远程数据库实例像访问本地数据表一样访问Comdb2 cloud。planner会把生成的SQL推送到远程节点执行,同时结果流也会返回,供本地处理之用。系统无需任何预先设置,可以动态地从远程服务器中获取schema和索引统计信息。远程信息被记下版本,缓存到本地,并且会在远程服务器更新时更新这些信息。planner会通过缓存下来的远程信息,本地信息以及相关的索引统计信息来决定最优的执行计划。在单个Comdb2的部署的所有实例中的所有表都能像在一个数据库中一样操作。这些表格都以<databasename>.<tablename>的形式被存到一个全局的命名空间中。系统允许数据管理员通过预定义的方式,将某个表格起个别名,映射到本地数据库的命名空间中。
存储过程,Trigger和Queue
Comdb2的存储过程语言是一种经过自定义的Lua方言。
该方言的拓展有如下几点:
1. 支持所有其他数据库提供的基本数据类型
2. 加强了typong system
3. 支持pthread风格的线程
4. 支持JSON parser
存储过程在服务器上进行。Lua引擎能够像客户端操作SQL一样操作数据关系库。可以自定义trigger(触发器)来处理数据库的各类事件。比如Update event。而Update event也可以设置filters。比如可以设置当修改了b的时候才触发Update event。这些事件被触发后就会写到一个内部队列中,会不断调用Stored procedure来消耗这些事件。数据库保证对每个事件来说,最多会调用一次procedure。
Triggers也能显式返还给调用SQL的应用程序。通过这样做,系统能够允许在同样条件下的多个客户端机器同时消耗SQL语句,而且仅仅用一次交付。这种使用方式适合更注重交互逻辑而不是注重数据稳定性的应用程序。通过结合Trigger,Stored Procedure和Queue,能够创建异步的满足最终一致的Replicate。逻辑日志会记录对行的所有更改,当事务一旦持久化,逻辑日志就会广播这些更改。任何感兴趣的以放都能选择这个多播流创建一个实际数据库的缓存。
Comdb2的实现
Comdb2存储层实现