什么是Comdb2?
一个基于优化并发控制技术的集群式关系数据库,面向大型数据,主要特色是1. 提供了多种隔离等级,包括快照和序列化隔离,后者使得Comdb2能从任何节点读取当前数据。2. 全面的事务支持 3. 支持Lua方言 4. 提供了关系数据模型 5. 提供了publisher2subscriber消息传递队列,后者能够实现时间一致的日志分发。 6. 使用主动并发控制(Optimistic Concurrency Control, OCC),一种无锁协议,目的是确保在大型数据集面临的低争用工作负载中获得更高的并行度。
Comdb2的历史
开发了12年,有个公司Bloomberg LP,一开始只是为了数据库能够更方便同步,SQL功能是之后加的。现在主要是BLP公司在维护。
BLP公司的主要产品是一种允许客户实时访问财经数据新闻和分析的软件平台。1981年公司的计算机是Perkin-Elmer系统的,所以没有与之匹配的数据库软件,为此,BLP开发了多个版本数据库系统,称为Comdb。2004年,Comdb2启动,目标是更具可拓展性的弹性DBMS,同时要兼顾高可用性,关系和完全事务模型。此时,公司选择不依赖大型机,而是用商用硬件集群,这就要求数据在多台机器间复制,带来了延迟和一致性的问题。常用的最终一致性(Eventual Concurrency,EC,按照事件发生的顺序在一行内显示update,以减少写入延迟)对BLP的应用场景不起作用,因为BLP要求准确和及时,而EC可能要造成两个不同的客户显示两个不同的股价。在BLP中,用作真相来源的数据库必须支持严格的一致性,并在适当时让最终用户降低一致性要求。高可用性也是至关重要的。间断性直接影响金融市场的日常工作。数据库必须在多个数据中心之间进行复制,并且其部署必须具有弹性。集群可以在没有任何架构的情况下增长,缩小甚至从一个架构迁移到另一个架构下线。
NoSQL也不适宜BLP的应用环境,因为NoSQL步支持完整的事务支持,仅仅提供微交易(micro transaction),即仅仅在行或者列级别执行写操作时确保原子性,而BLP要求系统能够经常用事务方式更新多个表中的多行。
OCC
主动并发控制(Optimistic Concurrency Control, OCC),一种无锁协议,目的是确保在大型数据集面临的低争用工作负载中获得更高的并行度。只在Commit的时候锁住Rows,而不是整个transaction都锁,所以能够获得最大的性能提升。这意味着集群中的每台计算机都只需要在提交时才进行一致性验证。OCC保证满足了现代OLTP(Online Transaction Processing,在线交易处理)的需求。而且,在分布式中,因为锁管理器通常很难分布式运行这一难点,OCC运行良好。
并发控制的两种形式
并发控制(Concurrency Control, CC)可以分为主动和被动两种。主动并发控制预测负载(一般在资源争用很少发生时使用),而悲观模型,即对行用安全锁,适用于争用频发的情况,这是为什么大型商业化数据库引擎大多采用悲观方法。具体来说,会发生以下几种情况:
1) 读操作可能把写操作block
2) 写操作block读
3) 多个读共享一个读锁(shared lock Q:和普通的读锁有什么不同?),把写操作都block
在典型的two-phase locking(2PL,二阶段锁)scheme中,被acquired的lock会一直阻碍着直到持有锁的线程终止或者完成。
但是在主动并发控制OCC系统中,事务们是一起并发执行的,不需要等待另一个执行。读操作无法保证数据的完整性,写操作则是在数据行的短期拷贝上执行的。
需要注意的是,尽管有了OCC,我们仍需要一个数据库来保证:
1. 能够在数据中心中同步复制
2. 在任何类型的中断和维护期间都可用。
尽管Schema改变在NoSQL构建中是一个比较大的破坏性问题,但是关系型数据库不会遭受这个问题困扰(?)。
所以,Comdb2能够实时执行各种形式的模式更改,性能的下降也是最小的,在很多情况下,Comdb2能够制性即时模式更改,允许就地更新而无需重建数据库。考虑到可能违反ACID性质,每个事务执行之后都需要再次validate验证。
OCC并发验证
Comdb2使用Backwards Optimistic Concurrency Control(BOCC) + 并发验证。Comdb2使用两个不同的验证阶段来防止出现异常,比如overwritting uncommitted data, 无法重复的读取和write skew。实际上,comdb2真正用的是hybrid system,也会在一些函数上使用锁。
为了检测Write-Write conflicts,Comdb2使用deferred 2PL(延迟的二阶段commit)。这项技术的关键在于genid(Generation Identifier)。genid与每行都有关:每次有一行发生变化,它对应的genid就会改变,而genid不能重新使用。在事务执行的时候会记录genid,然后在commit的时候验证。记录这些genid改变的结构是Block Processor Log(bplog,块处理器日志)。验证的时候,genid本身已经足够验证是否有异常发生。Comdb2使用的Write-Ahead Log(WAL)协议要求提前记录相互重叠的写操作集合,在验证的时候不会产生额外开销。
解决Read-Write Conflict的方法则是通过非永久性的记录事务的读操作集合,在验证的时候,重叠的写操作集合会从WAL中被提取,然后检测与read set的冲突。此时验证在一些阶段上会是逆向的。
在commit的时候,首先会执行pre-validation以节约时间,接着,在每个节点上并发执行validation直到计数达对应节点上的LSN,然后,master节点再反复周期性验证直到计数接近目前的LSN,接近(具体参数可以调整)LSN后,事务在临界区段(critical section)中执行最后的validation和最终的commit。
主要设计
设计要点
选用OOC以确保低开销
选择同步复制(Synchronous Replication)以使整个集群像单机模式一样方便使用。
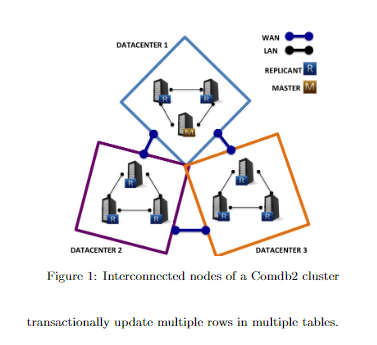
集群结构
Comdb2的集群包括一个master节点和多个相互连接的复制节点(replicant node)。每个集群代表一个地理分布上的复制。集群中的节点被分为room,多个空间,映射到多个数据中心。上游应用程序和数据库的交流在同一个数据中心里,只有在事务commit的时候才会发生数据中心间的交流。
高可用性SQL
标准API提供了Service Discovery,抽象化物理地址,使得应用程序能够重新链接不同的地址。HASQL架构允许对进行中的事务无缝地掩盖掉故障。事务开始地时候,服务端会给客户端发送一个时间点令牌point-in-time token,对应该会话开始时的Log Sequence Number(LSN)。当事务失败时,新配的节点会构建一个与这个时间点相同的快照,然后执行失败时正在执行的SELECT语句。数据库会跟踪已经返回的行数,这样就能返回下一行,不至于出错。而在事务中做写操作将会在客户端API中做缓冲,并且在失败+重连后透明地传送给新的节点(transparent failure masking of INSERT, UPDATE, DELETE)。在提交事务之前OCC都不会做任何实际更新,因此可以在提交之前重试。此外,从客户端到服务器使用的是全局排序(??这样是否符合分布式,会不会影响性能),因此允许重播。此外,单个节点错误时,系统不会返回错误,而是试图用透明的重复尝试掩盖。
隔离等级(Isolation Degree)
1. Block: 这是最弱也是non-SQL客户端唯一允许的隔离等级。只有已经committed的数据能被看到。因此在同个事务中的读是看不到写的变化的。
2. Read Committed: 和block级别相似,但是同个事务中的读能看到写所带来的uncommitted变化。
3. Snapshot Isolation: 如果存在start LSN之后的读请求,那么就把被修改的行的私有拷贝们合并。
4. Seriablize: 线性的,序列化的系统。如果存在事务在commit时违反现有的历史序列,那么就会直接报错。这些事务既不会阻塞,当然更不会思索。此外,这一级对读写冲突有格外的检验。