一、 爬虫流程
发送请求à获得页面à解析页面à下载内容à储存内容
二、 网络爬虫类型
1. 通用网络爬虫
- 含义
爬行对象从一些种子URL扩充到整个Web,主要为门户站点搜索引擎和大型Web服务提供商采集数据。
- 结构
包括页面爬行模块、页面分析模块、链接过滤模块、页面数据库、URL队列、初始URL集合。
- 爬行策略
深度优先策略、广度优先策略
2. 聚焦网络爬虫
- 含义:选择性地爬取那些与预先定义好的主题相关的页面。
- 结构
包括页面爬行模块、页面分析模块、链接过滤模块、页面数据库、URL队列、初始URL集合,增加了链接评价模块以及内容评价模块。
- 爬行策略:评价页面内容和链接的重要性
(1)基于内容评价的爬行策略:
Fish Search算法:运用文本相似度的计算方法,将用户输入的查询词作为主题,包含查询词的页面被视为与主题相关,局限性在于无法评价页面与主题相关度的高低。
Sharksearch算法:利用空间向量模型计算页面与主题的相关度大小。
(2)基于链接结构评价的爬虫策略:
PageRank算法:PageRank值越大的页面,越重要
HITS算法:通过计算每个页面的Authority权重(权威型)和Hub(中心型)权重,来评价链接的重要性
(3)基于增强学习的爬行策略:
将增强学习引入爬虫,利用贝叶斯分类器,根据整个网页文本和链接文本对超链接进行分类,为每个链接计算出重要性。
(4)基于语境图的爬行策略:
通过建立语境图学习网页之间的相关度,训练一个机器学习系统,通过该系统可计算当前页面到相关Web页面的距离,距离越近的页面中的链接优先访问。
该爬虫对主题的定义既不是采用关键词也不是加权矢量,而是一组具有相同主题的网页。
包括两个重要模块:分类器,净化器
分类器:用来计算所爬行页面与主题的相关度,确定是否与主题相关
净化器:用来识别通过较少链接连接到大量相关页面的中心页面
3. 增量式网络爬虫
- 含义:对已下载网页采取增量式更新,即只爬行新产生的或者已经发生变化网页的爬虫。
- 结构
爬行模块,排序模块,更新模块,本地页面集,待爬行URL集以及本地页面URL集。
- 爬行策略:保持本地页面集中存储的页面为最新页面和提高本地页面集中页面的质量
(1) 保持本地页面集中存储的页面为最新页面
a) 统一更新法:爬虫以相同的频率访问网页,不考虑网页的改变频率;
b) 个体更新法:爬虫根据个体网页的改变频率来重新访问各页面;
c) 基于分类的更新法:爬虫根据网页改变频率将其分为更新较快的网页子集和更新较慢的网页子集两类,然后以不同的频率访问这两类网页。
(2) 提高本地页面集中页面的质量:需要对网页的重要性排序,常用的策略有:广度优先策略,PageRank优先策略等。
4. Deep web爬虫
- 含义
Deep web是那些大部分内容不能通过静态链接获取的,隐藏在搜索表单后,只有用户提交一些关键词才能获得的Web页面。比如注册后才可见的页面。
- 结构
六个基本功能模块:爬行控制器,解析器,表单分析器,表单处理器,响应分析器,LVS控制器。
两个爬虫内部数据结构:URL列表和LVS表,LVS表示标签/数值集合,用来表示填充表单的数据源。
- 爬行策略:表单填写
(1)基于领域知识的表单填写:维持一个本体库,通过语义分析来选取合适的关键词填写表单
(2)基于网页结构分析的表单填写:将网页表单表示成DOM树,从中提取表单各字段值
三、已实现框架及算法
1. 通用网络爬虫
- 爬虫框架:Scrapy,pySpider等
2. 聚焦网络爬虫
Ache框架,Fish Search算法,Sharksearch算法,PageRank算法,HITS算法,将增强学习引入爬虫,基于语境图。
3. 增量式网络爬虫
- IBM的WebFountain:采用一种自适应的方法根据先前爬行周期里爬行结果和网页实际变化速度对页面更新频率进行调整。
- 北京大学的天网增量爬行系统:旨在爬行国内Web,将网页分为变化网页和新网页分类,分别采用不同爬行策略。
它根据网页变化时间局部性规律,在短时期内直接爬行多次变化的网页,为尽快获取新网页,它利用索引型网页跟踪新出现网页。
4. Deep web爬虫
- Desouky 等人提出一种 LEHW 方法
- Raghavan 等人提出的 HIWE 系统
四、网页搜索策略和网页分析算法
1. 网页搜索策略
- 广度优先搜索
- 最佳优先搜索
- 深度优先搜索
2. 网页分析算法
- 基于网络拓扑
- 基于网页内容
- 基于用户访问
五、 爬虫学习路线-
适用于:python+通用网络爬虫
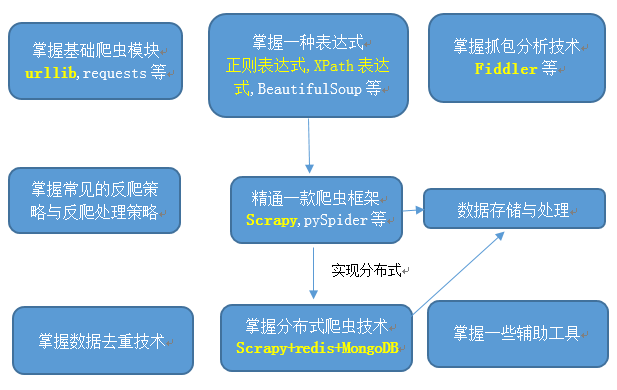
表1 反爬策略与反爬处理策略
|
反爬策略 |
反爬处理策略 |
|
IP限制 |
IP代理池技术 |
|
UA限制 |
用户代理池技术 |
|
Cookie限制 |
Cookie保存与处理 |
|
资源随机化存储 |
自动触发技术 |
|
动态加载技术 |
抓包分析技术(Fiddler)+自动触发技术 |
|
Opencv(图像颠倒) |
??? |
|
打码平台 动态网页 |
??? Selenium模拟浏览器加载 |
|
……. |
……. |
数据去重技术:
- 数据量少:运用数据库的数据约束
- 数据量很大:布隆过滤器 Bloom Filter
数据存储:本地文档,mysql,mongodb(方便存储非结构化数据),sqllite,PyMongo
数据处理:
- Numpy,pandas
- TB级别的数据:???
辅助工具:
- bs4(BeautifulSoup):把网页变成结构化数据,方便爬取,
- PhantomJS:不显示网页的Selenium,
- Selenium/ghost:动态页面,
- Scrapyjs:scrapy官方推荐处理动态页面的方式
- F12:看源代码浏览器快捷键,
- 火狐:可方便查看网站收包发包的信息,
- XPATH CHECKER:火狐插件(xpath测试工具)
- XPathOnClick:chrome插件,支持点击页面元素,获取XPATH路径,用于编辑配置模版
- Django、flask:Web开发框架,系统监控反馈
- Dagobah:可视化调度架构
- Docker:爬虫的部署容器
- Hbase:可提高存储数据的速度
- 八爪鱼:爬虫软件http://www.bazhuayu.com/
- Opencv:批量格式化图片
组合组件:
- request+urllib+Beautifulsoup/scrapy:实现简单的单机爬虫
- scrapy+redis+mongodb:分布式爬虫系统
scrapy:爬取网页内容
redis:存储要爬取的网页队列,即任务队列
mongodb:存储爬取的内容结果
六、困难与建议
1. 相关的知识太多,不知道从哪处开始
对新手来说,用什么无关紧要,选择一个组合组件,根据一个具体项目的具体需求,开始学着做着
2. 相关的知识太多,感觉学习完需要太多的精力
没必要全部学会,会运用一个组合组件后,再根据接触到的项目的具体需要,需要什么学习什么。