饮水思源:https://www.bilibili.com/video/BV1vW411M7zp?spm_id_from=333.337.search-card.all.click
一、JDBC
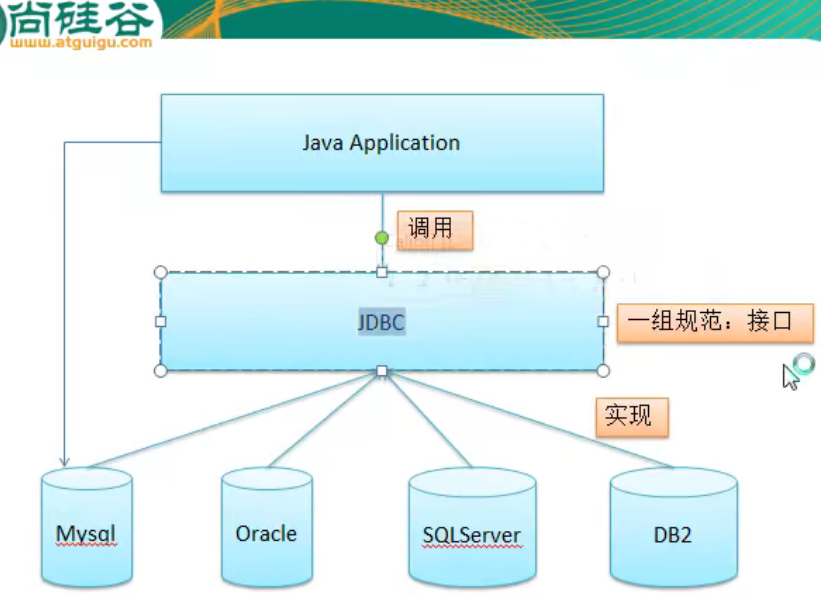
JDBC只是一组规范、接口,具体实现都是由各个数据库厂商提供的。我们只需添加对应厂商提供的“数据库驱动类”(例如:org.gjt.mm.mysql.Driver),就可以通过一组统一的类和接口(JDBC)访问该数据库。除了JDBC的实现类,还需要配合URL和一些凭证,才能顺利创建数据源(DataSource):
jdbc.url=jdbc:mysql://***.**.**.**:3306/profiles?characterEncoding=utf8
jdbc.username=root
jdbc.password=aaaaaaaaaaa
关于JDBC所规定的类和接口,详见API文档中的java.sql包。
应用JDBC的一般步骤:添加依赖、加载驱动(所谓加载驱动,就是确定采用哪个数据库提供的JDBC实现类)、提供URL和凭证、通过java.sql.驱动管理器获取连接(connection)、通过连接进行增删查改、释放包括连接在内的资源,详见https://www.cnblogs.com/xkxf/p/9354968.html
二、连接池
在生产环境中,自己去管理这些连接是低效的,因此我们引入了连接池(https://www.cnblogs.com/xkxf/p/9414499.html),当然,连接池只是帮助我们管理连接,高效利用连接,相应的驱动类,URL以及凭证等仍然是必不可少的,也就是底层还是用JDBC去访问数据库:
private static HikariConfig config = new HikariConfig(); private static HikariDataSource ds; static { config.setJdbcUrl("jdbc:mysql://127.0.0.1:3306/profiles?characterEncoding=utf8"); config.setUsername("root"); config.setPassword("???????"); config.addDataSourceProperty("cachePrepStmts", "true"); config.addDataSourceProperty("prepStmtCacheSize", "250"); config.addDataSourceProperty("prepStmtCacheSqlLimit", "2048"); ds = new HikariDataSource(config); config = new HikariConfig(); } public static Connection getConnection() throws SQLException { return ds.getConnection(); }
在使用连接池的时候有一点需要注意,应该采用对应连接池恰当的办法去获得连接,这样在关闭连接时就不会真的关闭,而是将它重新返还到连接池中。
三、ORM
在开发过程中,发现在代码里面写SQL也很烦,而且有很多不方便。于是有人写了一些代码对JDBC进一步封装,抽象,简化,例如Apache Commons DbUtils 但是实际上也没有多大改善。我们进一步追求代码的可读性,方便性,SQL和代码分离等,并且,希望可以更好地服务于面向对象编程(面向对象是一种很实用的编程思想。。。),于是就出现了一堆的ORM框架(Object Relational Mapping)。大概就是指MyBatis、Hibernate之类的框架(网络上,有种说法,MyBatis严格来说不能列入ORM框架),它们本质上仍是对JDBC的封装。摘抄一些网上的介绍:
ORM的作用是在编程中,把面向对象的概念跟数据库中表的概念对应起来。举例来说就是,我定义一个对象,那就对应着一张表,这个对象的实例,就对应着表中的一条记录。
ORM主要作用是把数据库领域的东西映射到面向对象领域
不用对象也就没必要用到ORM
当然ORM框架其实没有连接池必要。只是作用于“开发时”。
到后面,我们发现自己写SQL也很烦,干脆直接根据代码生成,然后就出现了类似MyBatis Generator的工具。到了JPA时代,甚至不需要懂SQL,只要理解面向对象就可以轻松操控数据库(一种理想情况。。。现实并非如此。。)。一切都是对象。
最后,ORM框架以及代码生成工具只是为了方便我们开发,说到底,底层还是用JDBC。因此,相应的驱动类,URL及凭证依旧是创建数据源的前提:
mybatis.mapper-locations=classpath:mapping/*.xml spring.datasource.name=jee_ex9_datasource spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.url=jdbc:mysql://127.0.0.1:3306/jee_ex9?useUnicode=true&characterEncoding=utf8&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=Asia/Shanghai spring.datasource.username=root spring.datasource.password=********* spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
四、JPA
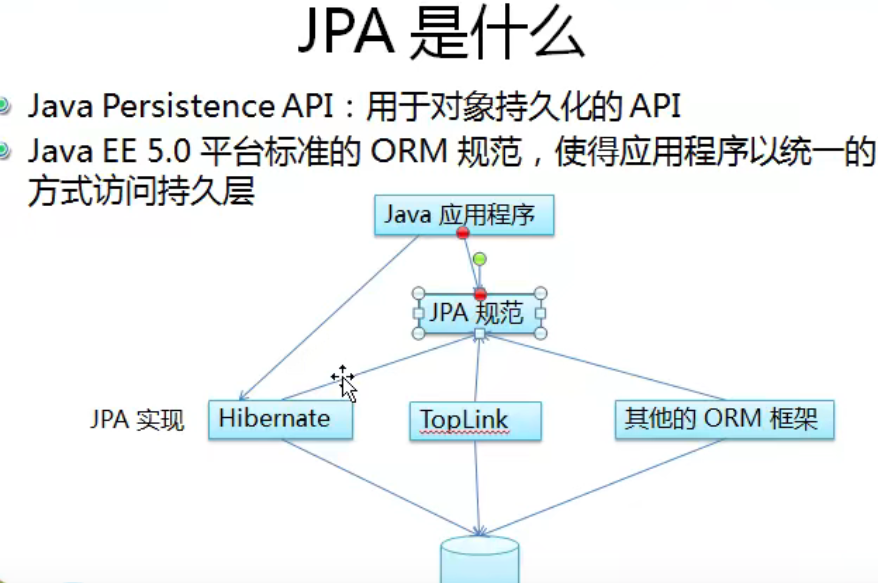
JDBC的实现类可能来自Oracle、MySQL或者其它数据库,
同样的,我们应用的ORM框架也可能是Hibernate或者其它,实践过程中,我们发现学习一种ORM框架是需要时间成本的(因为每个ORM框架都长得不太一样),最好弄成和JDBC一样,这样只需要学习一套API,我们就可以去使用任何ORM框架。
所以就出现了一个叫JPA(Java Persistence API)的东西,它本质上是一种规范,而不是一种框架。以下内容来自百度百科:
Sun引入新的JPA ORM规范出于两个原因:其一,简化现有Java EE和Java SE应用开发工作;其二,Sun希望整合ORM技术,实现天下归一。
JPA可以说是JDBC的升华版,升级版。应用JPA需要依赖JPA的实现类,而JPA的实现类归根结底还是需要依赖JDBC以及它的实现类。
补充说明:Spring Data JPA的默认实现是Hibernate,不管是Spring还是Hibernate都对原始的JPA做了补充,可以说原始JPA是他们两个的子集。应用JPA就好像把和数据库打交道的工作托管给了另一个人,虽然你不直接去和数据库打交道了,但也还是需要时不时检查那个人有没履行好职责。因此还是必须有sql和db的知识。
PS. 本人知识有限,以上内容只是现阶段对资料、知识的整合。不可避免存在一定误差。如有问题,欢迎指出!