通用目标检测

定义:
给定一个任意的图像,确定是否有来自预定义类别的语义目标的实例,如果存在,返回空间位置和范围.相比于目标类检测,更侧重于探测广泛的自然类别的方法
发展历程:
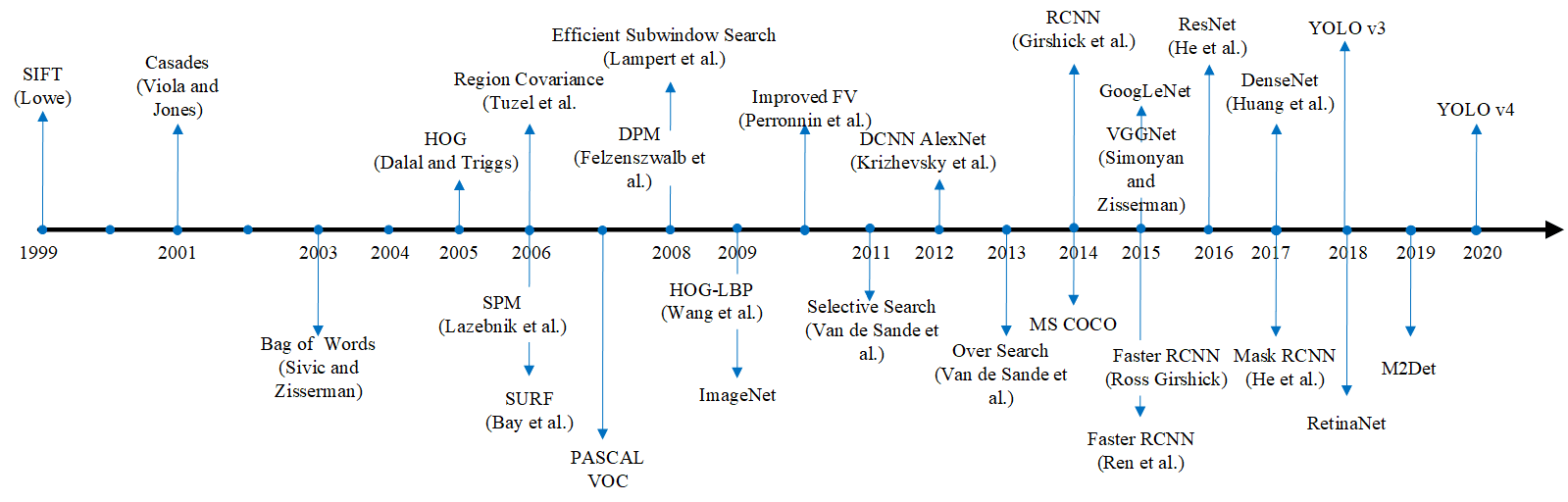
PASCAL VOC数据集, ILSVRC性能逐渐提高.
典型算法
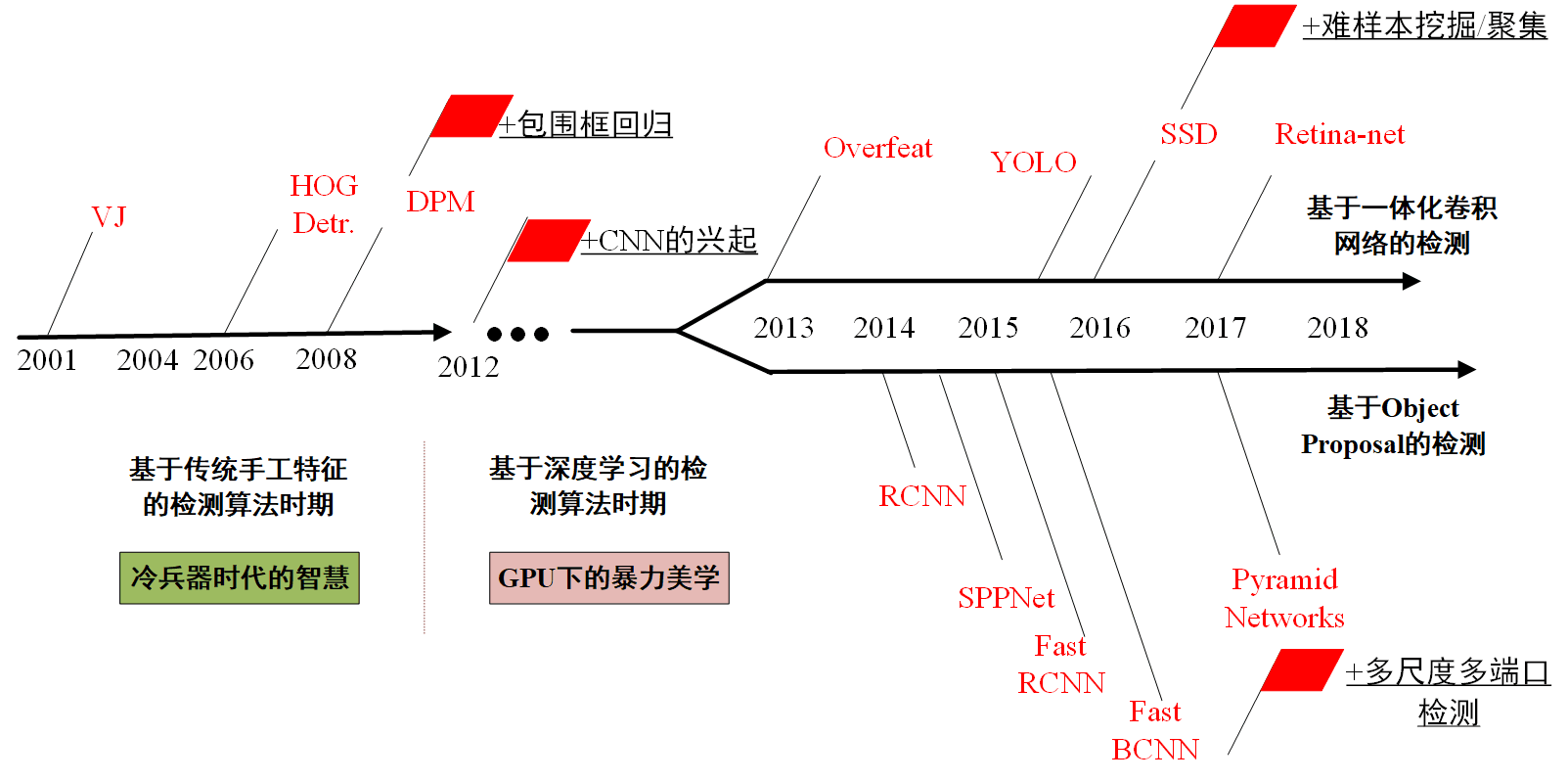
基于卷积的神经网络目标检测方法,根据检测速度可分为两阶段目标检测和一阶段目标检测。
- 两阶段目标检测算法:生成候选区域+分类和边界框回归
- 一阶段目标检测算法:仅一次前向传递一步到位
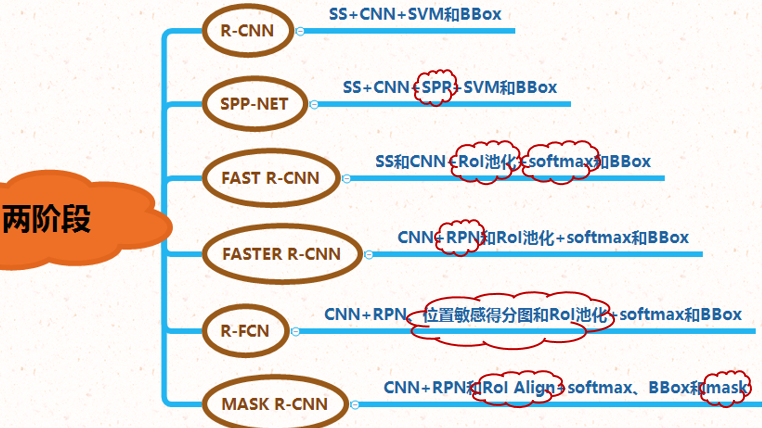
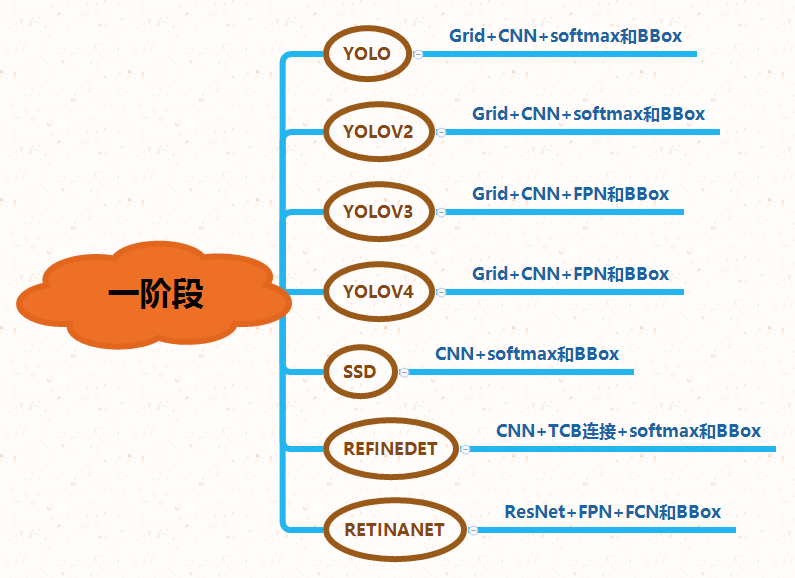
一般两阶段算法速度较慢精度较高,一阶段算法速度较快精度较低。
针对上图中算法,以后分开讲解。
通用问题
对象的空间位置和范围可以使用边界框粗略地定义,边界框被更广泛地用于评估通用目标检测算法.
发展趋势正在走向深入的场景理解(从图像级对象分类到单个对象定位,到通用对象检测,再到像素级对象分割)。
主要涉及的问题如下:
(1)正负样本不均衡问题
(2)定位精度低的问题
(3)目标特征不明显问题
(4)检测速度慢的问题
(5)Anchor—free问题
正负样本不均衡
很多算法都有一个基本假设,那就是数据分布是均匀的。当把这些算法直接应用于实际数据时,大多数情况下都无法取得理想结果。因为实际数据往往分布得不均匀,都会存在“长尾现象”,也就是所谓的“二八原理”。
任何数据集上都有数据不平衡现象,这由问题本身决定,但我们只关注那些分布差别比较悬殊的部分;另外,虽然很多数据集都包含多个类别,但这里着重考虑二分类,因为解决了二分类中的数据不平衡问题后,推而广之就能得到多分类情况下的解决方案。
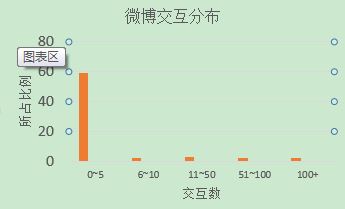
大部分微博的总互动数在0-5之间,交互数多的微博(多于100)非常之少。如果去预测一条微博交互数所在档位,预测器只需要把所有微博预测为第一档(0-5)就能获得非常高的准确率,而这样的预测器没有任何价值.
过抽样通过增加分类中少数类样本的数量来实现样本均衡,最直接的方法是简单复制少数类样本形成多条记录,这种方法的缺点是如果样本特征少而可能导致过拟合的问题;
欠抽样通过减少分类中多数类样本的样本数量来实现样本均衡,最直接的方法是随机地去掉一些多数类样本来减小多数类的规模,缺点是会丢失多数类样本中的一些重要信息。
总体上,过抽样和欠抽样更适合大数据分布不均衡的情况,尤其是过抽样方法应用更加广泛。
通过正负样本的惩罚权重解决样本不均衡的问题,算法中对于分类中不同样本数量的类别分别赋予不同的权重(一般思路分类中的小样本量类别权重高,大样本量类别权重低),然后进行计算和建模。使用这种方法时需要对样本本身做额外处理,需在算法模型的参数中进行相应设置。

很多模型和算法中都有基于类别参数的调整设置,针对不同类别来手动指定不同类别的权重,SVM默认方法会将权重设置为与不同类别样本数量呈反比的权重来做自动均衡处理。
组合/集成方法是在每次生成训练集时使用所有分类中的小样本量,同时从分类中的大样本量中随机抽取数据来与小样本量合并构成训练集,反复多次会得到很多训练集和训练模型,最后使用组合方法(例如投票、加权投票等)产生分类预测结果。
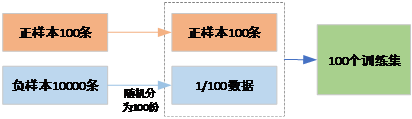
如果计算资源充足,并且对于模型的时效性要求不高的话,这种方法比较合适。
样本不均衡也会导致特征分布不均衡,但小类别样本量具有一定规模,其特征值的分布较为均匀,通过选择具有显著型的特征配合参与解决样本不均衡问题,称为基于列的特征选择方法。
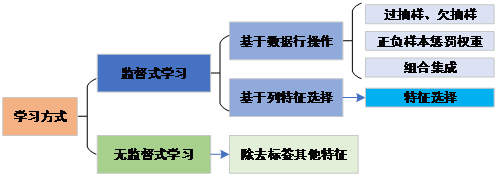
分类是监督式方法,前期是基于带有标签的数据进行分类预测;无监督式方法,则是使用除标签以外的其他特征进行模型拟合。上述四种方法的思路都是基于分类问题解决的。从大规模数据中寻找罕见数据,也可以使用非监督式的学习方法。
定位精度低的问题
定位和分类是目标检测的两大任务。在目标检测评价指标中,定位精度是一个重要测量指标,提高定位精度可以显著提高检测性能。
(1)设计一种新的损失函数来测量预测箱的精度是提高定位精度的有效途径。
(2)建立合理的目标检测评价指标,例如IoU。
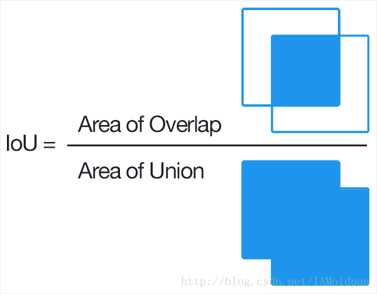
IoU是最常用的目标检测评价指标,对于两个边界框,IoU可以计算为交集面积除以并集面积。该损失函数对不同形状和尺度的物体具有较强的鲁棒性,能在较短的时间内很好地收敛。
目标特征不明显问题
从输入图像中提取有效特征是进一步精确分类和定位的前提,要充分利用连续的输出特征图谱骨干层。
FPN的目标是提取更丰富的特性,通过将这些产品分为不同级别大小不同的检测目标。
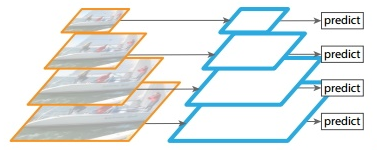
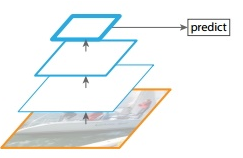
左侧整个过程是先对原始图像构造图像金字塔,然后在图像金字塔的每一层提出不同的特征,然后进行相应的预测,可以获得较好的检测精度。
右侧利用卷积网络本身的特性,对原始图像进行卷积和池化操作,获得不同尺寸的feature map.
图像中不同目标或区域之间的语义关系可以帮助检测遮挡和小目标。图像特征增强的方法有许多:
(1)利用组合的高级语义特征对目标进行分类定位,逐步将多区域特征结合起来;
(2)利用语义分割分支和全局激活模块,丰富典型深度检测器中目标检测特征的语义;
(3)采用场景上下文信息进一步提高准确性,构建目标之间的建模关系;
(4)充分利用目标有效区域,网络权值和采样位置共同决定有效支撑区域。
(5)脑激发机制是进一步提高检测性能的有力途径。
检测速度慢的问题
对于有限的计算能力和内存资源,如移动设备、实时设备、网络摄像头和自动驾驶鼓励等研究有效的检测架构设计。轻量化的目标检测算法,基于FPGA的硬件加速芯片是加快检测速度的重要方向。
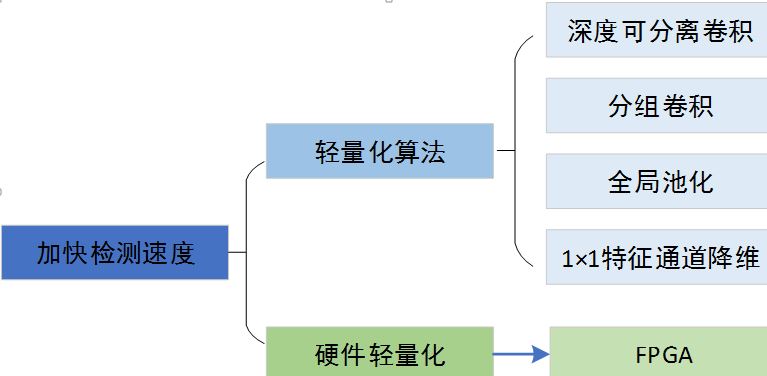
针对轻量化算法,从模型设计时就采用一些轻量化的思想,例如采用深度可分离卷积、分组卷积等轻量卷积方式,减少卷积过程的计算量。此外,利用全局池化来取代全连接层,利用1×1卷积实现特征的通道降维,也可以降低模型的计算量。
对于轻量化的网络设计,目前较为流行的有SqueezeNet、MobileNet及ShuffleNet等结构。SqueezeNet采用精心设计的压缩再扩展的结构,MobileNet使用了效率更高的深度可分离卷积,而ShuffleNet提出了通道混洗的操作,进一步降低了模型的计算量。
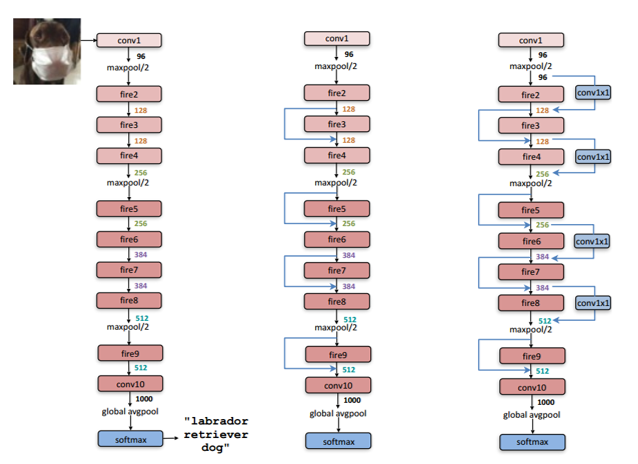
以卷积层(conv1)开始,接着使用8个Fire modules (fire2-9),最后以卷积层(conv10)结束。每个两个fire module中的filter数量逐渐增加,并且在conv1, fire4, fire8, 和 conv10这几层之后使用步长为2的最大池化,即将池化层放在网络相对靠后的层
Anchor—free问题
目前主流目标检测算法包括多阶段的各种RCNN和单阶段的SSD、RetinaNet上都是基于Anchor来做的。Anchor的本质是候选框,在设计不同尺度和比例的候选框后,学习如何将这些候选框进行分类:是否包含目标和包含什么类别的目标,对于positive的anchor会学习如何将其回归到正确的位置。但是,这种设计思路有很多问题:
(1)大部分目标形状不规则,边界框涵盖了大量非目标区域,引入较多干扰;
(2)Anchor的设置需要手动去设计,不同数据集要不同设计;
(3)Anchor的匹配机制使极端尺度被匹配到的频率相对于大小适中的目标被匹配到的频率更低;
(4)Anchor的庞大数量存在严重的不平衡问题。
Anchor-Based存在上述的问题,提出了Anchor Free的方法。
anchor-free方法主要有两种方法解决检测问题:
(1)基于密集检测的方法:这种方法将目标检测分为两个子问题,即确定物体中心和对四条边框的预测,遵循区域分类回归的思想。这两个子问题是通过密集预测的方法解决的,因此与Segmentation相通,代表作有FCOS,Foveabox和FSAF等;
(2)基于关键点的方法:这种方法跳出了区域分类回归的思想,通过解决关键点定位组合问题来检测物体,代表的有CornerNet,CenterNet和ExtremeNet等。

anchor-free模型是改变了GT的定义,Cornernet定义为角点,Extremenet定义为极值点和中心点,FSAF、FoveaBox定义为矩形框的中间区域,FCOS虽然是矩形框,但是经过center-ness抑制掉低质量的框,也是一种将GT定义为矩形框中心区域。重新定义之后,需要检测的目标语义变得更加明确,有利于分类和回归。因此,anchor-free本质上是将anchor-based转换成了keypoint-based /region-based。

红色、蓝色和其他颜色分别表示1、0和它们之间的值。计算中心度,当位置偏离物体中心时,中心度从1衰减到0。在测试时,网络预测的中心度与分类得分相乘,从而可以降低由远离对象中心的位置预测的低质量边界框的权重。
趋势
见下一节