进入spark/bin目录下输入spark-shell启动spark
(1)该系共有多少学生;

(2)该系共开设来多少门课程;
(3)Tom 同学的总成绩平均分是多少;
val lines = sc.textFile("file:///usr/local/sparkdata/Data01.txt")
lines.filter(row=>row.split(",")(0)=="Tom")
.map(row=>(row.split(",")(0),row.split(",")(2).toInt))
.mapValues(x=>(x,1)).
reduceByKey((x,y) => (x._1+y._1,x._2 + y._2))
.mapValues(x => (x._1 / x._2))
.collect()

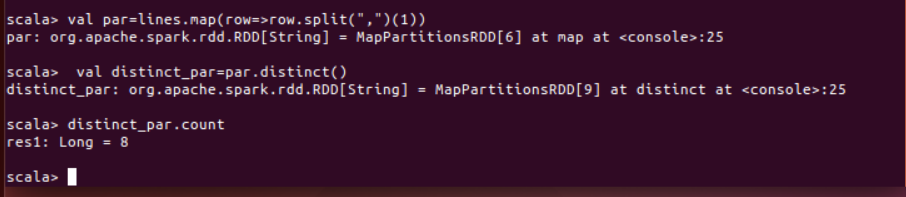
(4)求每名同学的选修的课程门数;
val lines =sc.textFile("file:///home/hadoop/桌面/data.txt")
line.map(row=>(row.split(",")(0),row.split(",")(1))).
mapValues(x=>(1)).
reduceByKey((x,y)=>(x+y)).
collect()
(5)该系 DataBase 课程共有多少人选修;
val lines =sc.textFile("file:///home/hadoop/桌面/data.txt")
line.filter(row=>row.split(",")(1)=="DataBase").
count()

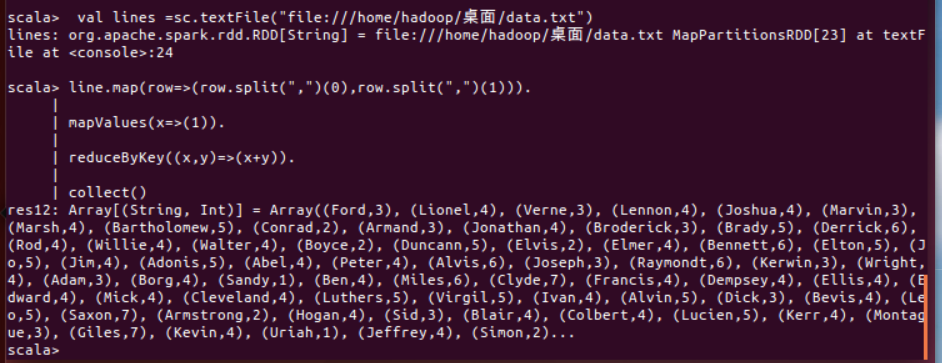
(6)各门课程的平均分是多少;
val lines =sc.textFile("file:///home/hadoop/桌面/data.txt")
line.map(row=>(row.split(",")(1),row.split(",")(2).toInt)).
mapValues(x=>(x,1)).
reduceByKey((x,y)=>(x._1+y._1,x._2+y._2)).
mapValues(x=>(x._1/x._2)).
collect()

(7)使用累加器计算共有多少人选了 DataBase 这门课。
val lines =sc.textFile("file:///home/hadoop/桌面/data.txt")
val pare = lines.filter(row=>row.split(",")(1)=="DataBase").
map(row=>(row.split(",")(1),1))
val accum =sc.accumulator(0)
pare.values.foreach(x => accum.add(x))
accum.value
