岭回归与多项式回归的最大区别就是损失函数上的区别。岭回归的代价函数如下:

为了方便计算导数,通常也会写成以下形式:

上述式子中w为长度为n的向量,不包括偏置项的系数 θ0,θ是长度为n+1的向量,包括偏置项系数θ0;m为样本数,n为特征数。
岭回归的代价函数仍然是凸函数,因此可以利用梯度等于0的方式求得全局最优解:
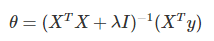
上述方程与一般线性回归方程相比多了一项λI,其中I表示单位矩阵,加入XTX是一个奇异矩阵(不满秩),添加这一项之后可以保证该项可逆,由于单位矩阵上的对角元素均为1,其余元素都为0,看起来像是一条山岭,因此而得名。
还可以使用随机梯度下降算法来求解:
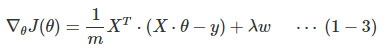
参数更新就可以如下表示:
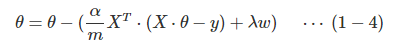
上述解释摘自:https://www.cnblogs.com/Belter/p/8536939.html
接下来是实现代码,代码来源: https://github.com/eriklindernoren/ML-From-Scratch
首先还是定义一个基类,各种线性回归都需要继承该基类:
class Regression(object): """ Base regression model. Models the relationship between a scalar dependent variable y and the independent variables X. Parameters: ----------- n_iterations: float The number of training iterations the algorithm will tune the weights for. learning_rate: float The step length that will be used when updating the weights. """ def __init__(self, n_iterations, learning_rate): self.n_iterations = n_iterations self.learning_rate = learning_rate def initialize_weights(self, n_features): """ Initialize weights randomly [-1/N, 1/N] """ limit = 1 / math.sqrt(n_features) self.w = np.random.uniform(-limit, limit, (n_features, )) def fit(self, X, y): # Insert constant ones for bias weights X = np.insert(X, 0, 1, axis=1) self.training_errors = [] self.initialize_weights(n_features=X.shape[1]) # Do gradient descent for n_iterations for i in range(self.n_iterations): y_pred = X.dot(self.w) # Calculate l2 loss mse = np.mean(0.5 * (y - y_pred)**2 + self.regularization(self.w)) self.training_errors.append(mse) # Gradient of l2 loss w.r.t w grad_w = -(y - y_pred).dot(X) + self.regularization.grad(self.w) # Update the weights self.w -= self.learning_rate * grad_w def predict(self, X): # Insert constant ones for bias weights X = np.insert(X, 0, 1, axis=1) y_pred = X.dot(self.w) return y_pred
岭回归的核心就是l2正则化项:
class l2_regularization(): """ Regularization for Ridge Regression """ def __init__(self, alpha): self.alpha = alpha def __call__(self, w): return self.alpha * 0.5 * w.T.dot(w) def grad(self, w): return self.alpha * w
然后是岭回归的核心代码:
class PolynomialRidgeRegression(Regression): """Similar to regular ridge regression except that the data is transformed to allow for polynomial regression. Parameters: ----------- degree: int The degree of the polynomial that the independent variable X will be transformed to. reg_factor: float The factor that will determine the amount of regularization and feature shrinkage. n_iterations: float The number of training iterations the algorithm will tune the weights for. learning_rate: float The step length that will be used when updating the weights. """ def __init__(self, degree, reg_factor, n_iterations=3000, learning_rate=0.01, gradient_descent=True): self.degree = degree self.regularization = l2_regularization(alpha=reg_factor) super(PolynomialRidgeRegression, self).__init__(n_iterations, learning_rate) def fit(self, X, y): X = normalize(polynomial_features(X, degree=self.degree)) super(PolynomialRidgeRegression, self).fit(X, y) def predict(self, X): X = normalize(polynomial_features(X, degree=self.degree)) return super(PolynomialRidgeRegression, self).predict(X)
其中的一些具体函数的用法可参考:https://www.cnblogs.com/xiximayou/p/12802868.html
最后是主函数:
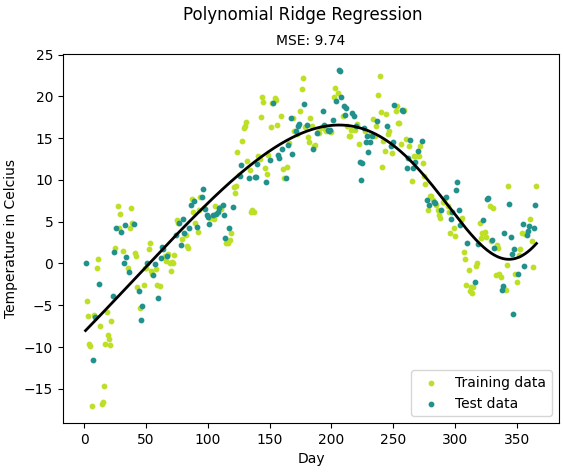
from __future__ import print_function import matplotlib.pyplot as plt import sys sys.path.append("/content/drive/My Drive/learn/ML-From-Scratch/") import numpy as np import pandas as pd # Import helper functions from mlfromscratch.supervised_learning import PolynomialRidgeRegression from mlfromscratch.utils import k_fold_cross_validation_sets, normalize, Plot from mlfromscratch.utils import train_test_split, polynomial_features, mean_squared_error def main(): # Load temperature data data = pd.read_csv('mlfromscratch/data/TempLinkoping2016.txt', sep=" ") time = np.atleast_2d(data["time"].values).T temp = data["temp"].values X = time # fraction of the year [0, 1] y = temp X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4) poly_degree = 15 # Finding regularization constant using cross validation lowest_error = float("inf") best_reg_factor = None print ("Finding regularization constant using cross validation:") k = 10 for reg_factor in np.arange(0, 0.1, 0.01): cross_validation_sets = k_fold_cross_validation_sets( X_train, y_train, k=k) mse = 0 for _X_train, _X_test, _y_train, _y_test in cross_validation_sets: model = PolynomialRidgeRegression(degree=poly_degree, reg_factor=reg_factor, learning_rate=0.001, n_iterations=10000) model.fit(_X_train, _y_train) y_pred = model.predict(_X_test) _mse = mean_squared_error(_y_test, y_pred) mse += _mse mse /= k # Print the mean squared error print (" Mean Squared Error: %s (regularization: %s)" % (mse, reg_factor)) # Save reg. constant that gave lowest error if mse < lowest_error: best_reg_factor = reg_factor lowest_error = mse # Make final prediction model = PolynomialRidgeRegression(degree=poly_degree, reg_factor=reg_factor, learning_rate=0.001, n_iterations=10000) model.fit(X_train, y_train) y_pred = model.predict(X_test) mse = mean_squared_error(y_test, y_pred) print ("Mean squared error: %s (given by reg. factor: %s)" % (mse, reg_factor)) y_pred_line = model.predict(X) # Color map cmap = plt.get_cmap('viridis') # Plot the results m1 = plt.scatter(366 * X_train, y_train, color=cmap(0.9), s=10) m2 = plt.scatter(366 * X_test, y_test, color=cmap(0.5), s=10) plt.plot(366 * X, y_pred_line, color='black', linewidth=2, label="Prediction") plt.suptitle("Polynomial Ridge Regression") plt.title("MSE: %.2f" % mse, fontsize=10) plt.xlabel('Day') plt.ylabel('Temperature in Celcius') plt.legend((m1, m2), ("Training data", "Test data"), loc='lower right') plt.savefig("test1.png") plt.show() if __name__ == "__main__": main()
结果:
Finding regularization constant using cross validation: Mean Squared Error: 13.812293192023807 (regularization: 0.0) Mean Squared Error: 13.743127176668661 (regularization: 0.01) Mean Squared Error: 13.897319799448272 (regularization: 0.02) Mean Squared Error: 13.755294291853932 (regularization: 0.03) Mean Squared Error: 13.864603077117456 (regularization: 0.04) Mean Squared Error: 14.13017742349847 (regularization: 0.05) Mean Squared Error: 14.031692893193021 (regularization: 0.06) Mean Squared Error: 14.12160512870597 (regularization: 0.07) Mean Squared Error: 14.462275871359097 (regularization: 0.08) Mean Squared Error: 14.155492625301093 (regularization: 0.09) Mean squared error: 9.743831581107068 (given by reg. factor: 0.09)