可以使用以下3种方式构建模型:使用Sequential按层顺序构建模型,使用函数式API构建任意结构模型,继承Model基类构建自定义模型。
对于顺序结构的模型,优先使用Sequential方法构建。
如果模型有多输入或者多输出,或者模型需要共享权重,或者模型具有残差连接等非顺序结构,推荐使用函数式API进行创建。
如果无特定必要,尽可能避免使用Model子类化的方式构建模型,这种方式提供了极大的灵活性,但也有更大的概率出错。
下面以IMDB电影评论的分类问题为例,演示3种创建模型的方法。
import numpy as np import pandas as pd import tensorflow as tf from tqdm import tqdm from tensorflow.keras import * train_token_path = "./data/imdb/train_token.csv" test_token_path = "./data/imdb/test_token.csv" MAX_WORDS = 10000 # We will only consider the top 10,000 words in the dataset MAX_LEN = 200 # We will cut reviews after 200 words BATCH_SIZE = 20 # 构建管道 def parse_line(line): t = tf.strings.split(line," ") label = tf.reshape(tf.cast(tf.strings.to_number(t[0]),tf.int32),(-1,)) features = tf.cast(tf.strings.to_number(tf.strings.split(t[1]," ")),tf.int32) return (features,label) ds_train= tf.data.TextLineDataset(filenames = [train_token_path]) .map(parse_line,num_parallel_calls = tf.data.experimental.AUTOTUNE) .shuffle(buffer_size = 1000).batch(BATCH_SIZE) .prefetch(tf.data.experimental.AUTOTUNE) ds_test= tf.data.TextLineDataset(filenames = [test_token_path]) .map(parse_line,num_parallel_calls = tf.data.experimental.AUTOTUNE) .shuffle(buffer_size = 1000).batch(BATCH_SIZE) .prefetch(tf.data.experimental.AUTOTUNE)
一,Sequential按层顺序创建模型
f.keras.backend.clear_session() model = models.Sequential() model.add(layers.Embedding(MAX_WORDS,7,input_length=MAX_LEN)) model.add(layers.Conv1D(filters = 64,kernel_size = 5,activation = "relu")) model.add(layers.MaxPool1D(2)) model.add(layers.Conv1D(filters = 32,kernel_size = 3,activation = "relu")) model.add(layers.MaxPool1D(2)) model.add(layers.Flatten()) model.add(layers.Dense(1,activation = "sigmoid")) model.compile(optimizer='Nadam', loss='binary_crossentropy', metrics=['accuracy',"AUC"]) model.summary()
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding (Embedding) (None, 200, 7) 70000 _________________________________________________________________ conv1d (Conv1D) (None, 196, 64) 2304 _________________________________________________________________ max_pooling1d (MaxPooling1D) (None, 98, 64) 0 _________________________________________________________________ conv1d_1 (Conv1D) (None, 96, 32) 6176 _________________________________________________________________ max_pooling1d_1 (MaxPooling1 (None, 48, 32) 0 _________________________________________________________________ flatten (Flatten) (None, 1536) 0 _________________________________________________________________ dense (Dense) (None, 1) 1537 ================================================================= Total params: 80,017 Trainable params: 80,017 Non-trainable params: 0 _________________________________________________________________
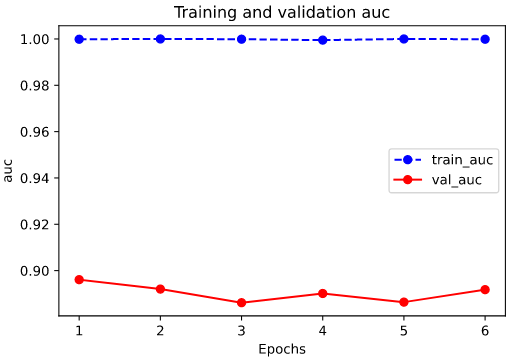
import datetime baselogger = callbacks.BaseLogger(stateful_metrics=["auc"]) logdir = "./data/keras_model/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S") tensorboard_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1) history = model.fit(ds_train,validation_data = ds_test, epochs = 6,callbacks=[baselogger,tensorboard_callback]) %matplotlib inline %config InlineBackend.figure_format = 'svg' import matplotlib.pyplot as plt def plot_metric(history, metric): train_metrics = history.history[metric] val_metrics = history.history['val_'+metric] epochs = range(1, len(train_metrics) + 1) plt.plot(epochs, train_metrics, 'bo--') plt.plot(epochs, val_metrics, 'ro-') plt.title('Training and validation '+ metric) plt.xlabel("Epochs") plt.ylabel(metric) plt.legend(["train_"+metric, 'val_'+metric]) plt.show() plot_metric(history,"auc")
这里不能成功运行。。。,错误如下:
Epoch 1/6 1000/Unknown - 17s 17ms/step - loss: 0.1133 - accuracy: 0.9588 - auc: 0.9918 --------------------------------------------------------------------------- KeyError Traceback (most recent call last) <ipython-input-17-8cd49fdfb6d8> in <module>() 4 tensorboard_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1) 5 history = model.fit(ds_train,validation_data = ds_test, ----> 6 epochs = 6,callbacks=[baselogger,tensorboard_callback]) 7 """ 8 %matplotlib inline 3 frames /usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/callbacks.py in on_epoch_end(self, epoch, logs) 795 def on_epoch_end(self, epoch, logs=None): 796 if logs is not None: --> 797 for k in self.params['metrics']: 798 if k in self.totals: 799 # Make value available to next callbacks. KeyError: 'metrics'
只好先换成这样的:
import datetime logdir = "./data/keras_model/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S") tensorboard_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1) history = model.fit(ds_train,validation_data = ds_test,epochs = 6,callbacks=[tensorboard_callback])
然后是结果:
Epoch 1/6 1000/1000 [==============================] - 44s 44ms/step - loss: 0.0058 - accuracy: 0.9980 - auc: 0.9999 - val_loss: 1.5239 - val_accuracy: 0.8598 - val_auc: 0.8961 Epoch 2/6 1000/1000 [==============================] - 44s 44ms/step - loss: 0.0011 - accuracy: 0.9996 - auc: 1.0000 - val_loss: 1.7804 - val_accuracy: 0.8610 - val_auc: 0.8920 Epoch 3/6 1000/1000 [==============================] - 44s 44ms/step - loss: 0.0034 - accuracy: 0.9990 - auc: 0.9999 - val_loss: 1.8452 - val_accuracy: 0.8524 - val_auc: 0.8861 Epoch 4/6 1000/1000 [==============================] - 43s 43ms/step - loss: 0.0107 - accuracy: 0.9969 - auc: 0.9995 - val_loss: 1.6515 - val_accuracy: 0.8582 - val_auc: 0.8901 Epoch 5/6 1000/1000 [==============================] - 44s 44ms/step - loss: 0.0022 - accuracy: 0.9994 - auc: 1.0000 - val_loss: 1.7680 - val_accuracy: 0.8522 - val_auc: 0.8864 Epoch 6/6 1000/1000 [==============================] - 44s 44ms/step - loss: 0.0052 - accuracy: 0.9979 - auc: 0.9999 - val_loss: 1.7506 - val_accuracy: 0.8554 - val_auc: 0.8918
二,函数式API创建任意结构模型
tf.keras.backend.clear_session() inputs = layers.Input(shape=[MAX_LEN]) x = layers.Embedding(MAX_WORDS,7)(inputs) branch1 = layers.SeparableConv1D(64,3,activation="relu")(x) branch1 = layers.MaxPool1D(3)(branch1) branch1 = layers.SeparableConv1D(32,3,activation="relu")(branch1) branch1 = layers.GlobalMaxPool1D()(branch1) branch2 = layers.SeparableConv1D(64,5,activation="relu")(x) branch2 = layers.MaxPool1D(5)(branch2) branch2 = layers.SeparableConv1D(32,5,activation="relu")(branch2) branch2 = layers.GlobalMaxPool1D()(branch2) branch3 = layers.SeparableConv1D(64,7,activation="relu")(x) branch3 = layers.MaxPool1D(7)(branch3) branch3 = layers.SeparableConv1D(32,7,activation="relu")(branch3) branch3 = layers.GlobalMaxPool1D()(branch3) concat = layers.Concatenate()([branch1,branch2,branch3]) outputs = layers.Dense(1,activation = "sigmoid")(concat) model = models.Model(inputs = inputs,outputs = outputs) model.compile(optimizer='Nadam', loss='binary_crossentropy', metrics=['accuracy',"AUC"]) model.summary()
Model: "model" __________________________________________________________________________________________________ Layer (type) Output Shape Param # Connected to ================================================================================================== input_1 (InputLayer) [(None, 200)] 0 __________________________________________________________________________________________________ embedding (Embedding) (None, 200, 7) 70000 input_1[0][0] __________________________________________________________________________________________________ separable_conv1d (SeparableConv (None, 198, 64) 533 embedding[0][0] __________________________________________________________________________________________________ separable_conv1d_2 (SeparableCo (None, 196, 64) 547 embedding[0][0] __________________________________________________________________________________________________ separable_conv1d_4 (SeparableCo (None, 194, 64) 561 embedding[0][0] __________________________________________________________________________________________________ max_pooling1d (MaxPooling1D) (None, 66, 64) 0 separable_conv1d[0][0] __________________________________________________________________________________________________ max_pooling1d_1 (MaxPooling1D) (None, 39, 64) 0 separable_conv1d_2[0][0] __________________________________________________________________________________________________ max_pooling1d_2 (MaxPooling1D) (None, 27, 64) 0 separable_conv1d_4[0][0] __________________________________________________________________________________________________ separable_conv1d_1 (SeparableCo (None, 64, 32) 2272 max_pooling1d[0][0] __________________________________________________________________________________________________ separable_conv1d_3 (SeparableCo (None, 35, 32) 2400 max_pooling1d_1[0][0] __________________________________________________________________________________________________ separable_conv1d_5 (SeparableCo (None, 21, 32) 2528 max_pooling1d_2[0][0] __________________________________________________________________________________________________ global_max_pooling1d (GlobalMax (None, 32) 0 separable_conv1d_1[0][0] __________________________________________________________________________________________________ global_max_pooling1d_1 (GlobalM (None, 32) 0 separable_conv1d_3[0][0] __________________________________________________________________________________________________ global_max_pooling1d_2 (GlobalM (None, 32) 0 separable_conv1d_5[0][0] __________________________________________________________________________________________________ concatenate (Concatenate) (None, 96) 0 global_max_pooling1d[0][0] global_max_pooling1d_1[0][0] global_max_pooling1d_2[0][0] __________________________________________________________________________________________________ dense (Dense) (None, 1) 97 concatenate[0][0] ================================================================================================== Total params: 78,938 Trainable params: 78,938 Non-trainable params: 0 __________________________________________________________________________________________________
import datetime logdir = "./data/keras_model/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S") tensorboard_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1) history = model.fit(ds_train,validation_data = ds_test,epochs = 6,callbacks=[tensorboard_callback])
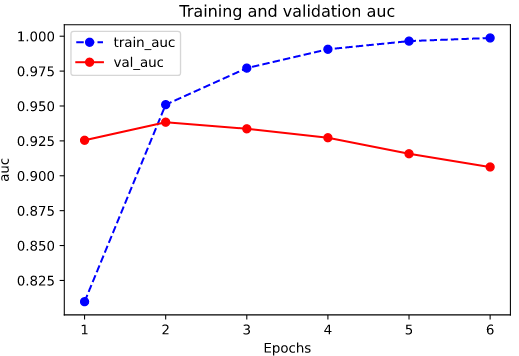
Epoch 1/6 1000/1000 [==============================] - 28s 28ms/step - loss: 0.5210 - accuracy: 0.7120 - auc: 0.8098 - val_loss: 0.3512 - val_accuracy: 0.8482 - val_auc: 0.9254 Epoch 2/6 1000/1000 [==============================] - 27s 27ms/step - loss: 0.2842 - accuracy: 0.8805 - auc: 0.9510 - val_loss: 0.3302 - val_accuracy: 0.8588 - val_auc: 0.9384 Epoch 3/6 1000/1000 [==============================] - 27s 27ms/step - loss: 0.1931 - accuracy: 0.9265 - auc: 0.9772 - val_loss: 0.3955 - val_accuracy: 0.8512 - val_auc: 0.9336 Epoch 4/6 1000/1000 [==============================] - 27s 27ms/step - loss: 0.1203 - accuracy: 0.9594 - auc: 0.9906 - val_loss: 0.4669 - val_accuracy: 0.8494 - val_auc: 0.9273 Epoch 5/6 1000/1000 [==============================] - 27s 27ms/step - loss: 0.0664 - accuracy: 0.9798 - auc: 0.9965 - val_loss: 0.5963 - val_accuracy: 0.8476 - val_auc: 0.9158 Epoch 6/6 1000/1000 [==============================] - 27s 27ms/step - loss: 0.0305 - accuracy: 0.9934 - auc: 0.9987 - val_loss: 0.7246 - val_accuracy: 0.8440 - val_auc: 0.9063
plot_metric(history,"auc")
三,Model子类化创建自定义模型
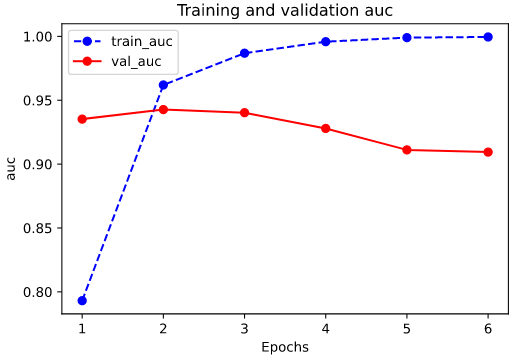
# 先自定义一个残差模块,为自定义Layer class ResBlock(layers.Layer): def __init__(self, kernel_size, **kwargs): super(ResBlock, self).__init__(**kwargs) self.kernel_size = kernel_size def build(self,input_shape): self.conv1 = layers.Conv1D(filters=64,kernel_size=self.kernel_size, activation = "relu",padding="same") self.conv2 = layers.Conv1D(filters=32,kernel_size=self.kernel_size, activation = "relu",padding="same") self.conv3 = layers.Conv1D(filters=input_shape[-1], kernel_size=self.kernel_size,activation = "relu",padding="same") self.maxpool = layers.MaxPool1D(2) super(ResBlock,self).build(input_shape) # 相当于设置self.built = True def call(self, inputs): x = self.conv1(inputs) x = self.conv2(x) x = self.conv3(x) x = layers.Add()([inputs,x]) x = self.maxpool(x) return x #如果要让自定义的Layer通过Functional API 组合成模型时可以序列化,需要自定义get_config方法。 def get_config(self): config = super(ResBlock, self).get_config() config.update({'kernel_size': self.kernel_size}) return config # 测试ResBlock resblock = ResBlock(kernel_size = 3) resblock.build(input_shape = (None,200,7)) resblock.compute_output_shape(input_shape=(None,200,7)) # 自定义模型,实际上也可以使用Sequential或者FunctionalAPI class ImdbModel(models.Model): def __init__(self): super(ImdbModel, self).__init__() def build(self,input_shape): self.embedding = layers.Embedding(MAX_WORDS,7) self.block1 = ResBlock(7) self.block2 = ResBlock(5) self.dense = layers.Dense(1,activation = "sigmoid") super(ImdbModel,self).build(input_shape) def call(self, x): x = self.embedding(x) x = self.block1(x) x = self.block2(x) x = layers.Flatten()(x) x = self.dense(x) return(x) tf.keras.backend.clear_session() model = ImdbModel() model.build(input_shape =(None,200)) model.summary() model.compile(optimizer='Nadam', loss='binary_crossentropy', metrics=['accuracy',"AUC"]) import datetime logdir = "./tflogs/keras_model/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S") tensorboard_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1) history = model.fit(ds_train,validation_data = ds_test, epochs = 6,callbacks=[tensorboard_callback]) plot_metric(history,"auc")
odel: "imdb_model" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding (Embedding) multiple 70000 _________________________________________________________________ res_block (ResBlock) multiple 19143 _________________________________________________________________ res_block_1 (ResBlock) multiple 13703 _________________________________________________________________ dense (Dense) multiple 351 ================================================================= Total params: 103,197 Trainable params: 103,197 Non-trainable params: 0 _________________________________________________________________ Epoch 1/6 1000/1000 [==============================] - 44s 44ms/step - loss: 0.5311 - accuracy: 0.6953 - auc: 0.7931 - val_loss: 0.3333 - val_accuracy: 0.8522 - val_auc: 0.9352 Epoch 2/6 1000/1000 [==============================] - 43s 43ms/step - loss: 0.2507 - accuracy: 0.8985 - auc: 0.9619 - val_loss: 0.3906 - val_accuracy: 0.8404 - val_auc: 0.9427 Epoch 3/6 1000/1000 [==============================] - 43s 43ms/step - loss: 0.1448 - accuracy: 0.9465 - auc: 0.9868 - val_loss: 0.3965 - val_accuracy: 0.8742 - val_auc: 0.9403 Epoch 4/6 1000/1000 [==============================] - 43s 43ms/step - loss: 0.0758 - accuracy: 0.9745 - auc: 0.9958 - val_loss: 0.5496 - val_accuracy: 0.8648 - val_auc: 0.9279 Epoch 5/6 1000/1000 [==============================] - 43s 43ms/step - loss: 0.0296 - accuracy: 0.9898 - auc: 0.9990 - val_loss: 0.8675 - val_accuracy: 0.8592 - val_auc: 0.9111 Epoch 6/6 1000/1000 [==============================] - 43s 43ms/step - loss: 0.0208 - accuracy: 0.9927 - auc: 0.9995 - val_loss: 0.9153 - val_accuracy: 0.8578 - val_auc: 0.9094
参考:
开源电子书地址:https://lyhue1991.github.io/eat_tensorflow2_in_30_days/
GitHub 项目地址:https://github.com/lyhue1991/eat_tensorflow2_in_30_days