python如何编译py文件生成pyc、pyo、pyd以及如何和C语言结合使用
喜欢这篇文章的话,就去bilibili看看我吧,虽然啥也没有。:https://space.bilibili.com/12921175
python执行py文件的流程
当我们执行一个py文件的时候,直接python xx.py即可,那么这个流程是怎么样的呢。先说明一下,python执行代码实际上是先打开文件然后执行里面的代码,所以文件的扩展名不一定是py的形式,txt形式也是依旧可以成功执行,只要文件里面的代码是符合python规范的。下面我们来看看python是怎么执行py文件的。
先将文件里面的内容读取出来,scanner对其进行扫描,切分成一个个的tokenparser对token进行解析,建立抽象语法树(AST,abstract syntax tree)compiler对ast进行编译,得到python字节码code evaluator执行字节码
我们注意到第三个过程,是一个编译的过程。说明python即便是解释性语言,也依旧存在着编译的过程,这一点和java是一样的。之所以要存在编译的过程,主要是为了优化执行的速度,比如元组,或者函数里面出现了yield,这一点在编译的时候就已经确定了,编译的时候就已经知道这是一个什么样的数据结构,那么在执行的时候可以很快速的分配相应的内存。我们在打开python文件所在的目录的时候,总会看到一个__pycache__的文件夹,这里面存放的就是python编译之后的字节码。当执行python文件的时候,会检测当前的__pycache__目录中是否有对应的字节码,没有就创建,有的话比较字节码的创建时间和当前py文件的修改时间,如果字节码的创建时间要晚一些,说明用户没有修改文件,于是执行字节码,如果字节码的创建时间要早一些,说明用户修改了python源代码,那么就会从新编译得到一个新的字节码。此外编译还有一个重要的特点,就是语法检测。错误分为两种:一种是语法错误,另一种是逻辑错误。
-
语法错误就是源代码没有遵循python的规范,比如if判断使用了一个=,或者for循环后面没有:等等,这些都是属于语法错误,这是一种低级的错误,在编译的时候就会失败。try: > except Exception: pass """ 这个代码是编译不过去的,即便你使用了try···except。 语法错误就是不遵循python规范,编译的时候都编译不过。 """ -
那么另一种错误就是逻辑错误,这是语法没问题,但是执行的时候出错了,比如索引越界、和0相除、变量没有定义等等,这些错误是在运行的时候才会出现的,这是可以被捕获的。try: a except Exception: pass # 这段代码是不会报错的。
python如何编译py文件生成字节码
python中的字节码有两种,pyc和pyo,两者本质上没啥区别,只不过pyo的优化程度更高一些。
编译可以通过py_compile模块进行编译
# test.py
deffoo(name):
print("hello " + name)
我们来对test.py进行编译
import py_compile
"""
参数如下:
file:要编译的py文件
cfile:编译之后的字节码文件,不指定的话默认为源文件目录下的__pycache__目录的下的'源文件名.解释器类型-python版本.字节码类型'文件
dfile:错误消息文件,默认和cfile一样,一般不用管
doraise:是否开启异常处理,默认和False
optimize:优化字节码级别。如果是pyc:可以选-1或0。pyo的话,可以选1或2。都是值越小优化程度越高
"""
py_compile.compile(file="test.py", cfile=r"./test.pyc", optimize=-1)
py_compile.compile(file="test.py", cfile=r"./test.pyo", optimize=1)

可以看到,已经编译成功了,pyc是可以直接当做普通py文件导入的,但是pyo貌似不可以,所以一般我们只编译成pyc形式的字节码。但是如果不导入只是执行的话,那么是可以编译成pyo的。
import test
test.foo("mashiro") # hello mashiro
编译的另一种方式,我们也可以直接使用命令行。
编译成pyc
python -m py_compile 源代码
编译成pyo
python -O -m py_compile 源代码
如果需要编译整个目录内的所有源代码
python compileall
编译成pyd文件
这个pyd实际上就是Windows上的dll文件,但是pyd是由py文件生成的,是可以直接当成python模块导入的。而dll的话一般是c或者c++编写的扩展模块,这个时候我们会使用ctypes进行加载,后面会说。而Windows的pyd在linux上面则是so文件,dll在linux上面也是so文件,这个时候是使用ctypes还是使用普通加载模块的方式,就看具体情况了。
我们下面测试一段python代码,看看会用多长时间,然后将其编译成pyd之后再测试一下。
# test_v.py
deffunc():
for _ in range(10000):
sum = 0
for i in range(100000):
sum += i
可以看到我们将sum依次从0加到100000-1,然后重复这个过程10000次,我们来测试一下用了多长时间。
import time
from test_v import func
start = time.perf_counter()
func()
end = time.perf_counter()
print("总耗时:", end - start) # 总耗时: 45.554086
直接导入py文件,调用函数执行,总共花了45秒钟,下面我们来编译成pyd。
那么如何编译成pyd呢?
首先确保电脑上安装了64位的MinGW,然后安装cython,pip install cython,新建一个py文件to_pyd.py。
# to_pyd.py
# 导入模块
import Cython.Build
# 传入要编译成pyd的py文件
ext = Cython.Build.cythonize("test_v.py")
# 下面还要导入另一个模块
import distutils.core
# 调用setup方法
distutils.core.setup(
ext_modules=ext, # 将Cython.Build.cythonize返回的结果传进去
)
然后在命令行输入python to_pyd.py build,即可把py文件test_v.py编译成pyd。执行之后,会得到一个对应的test_v.c文件,以及一个build目录。这个生成的c文件我们不需要管,我们看看build目录。
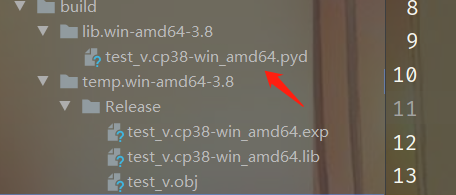
我们看到此时就得到了对应的pyd文件,也叫test_v,后面的则是python的版本号以及操作系统类型、位数等等,我们来测试一下性能吧。只把那个pyd文件拿出来,其他没用的都删掉,
import time
import test_v
# 我们看到导入之后,显示的是pyd
print(test_v) # <module 'test_v' from 'C:\Users\satori\Desktop\love_minami\test_v.cp38-win_amd64.pyd'>
start = time.perf_counter()
test_v.func()
end = time.perf_counter()
print("总耗时:", end - start) # 总耗时: 12.3021872
此时我们惊奇地看到,用了12秒,确实快了不少。主要是cython将python代码进行了优化,另外编译成pyd之后,是很难再反编译成py文件的,如果你的模块必须开源但是又不想被人看到某些细节的话,那么就可以编译成pyd。对于字节码pyc文件的反编译已经有人实现了,可以将pyc转成py文件,但是pyd目前还没有被反编译过。
那为什么编译成pyd的时候速度会提升呢?主要是cython将代码进行了优化,转化成了c一级的代码。另外我们说,test_v.cp38-win_amd64.pyd里面的38就是解释器的版本,我们这里是python3.8。这样的话,也就意味着只有当你的版本是python3.8的时候,才会去导入这个模块,于是我们把中间那一串给删掉只保留test_v.pyd可不可以呢?我们可以试一下
import test_v
print(test_v) # <module 'test_v' from 'C:\Users\satori\Desktop\love_minami\test_v.pyd'>
事实证明确实是可以的,另外这样的话不光是python3.8,其他版本的python也是可以导入的,只要编译成pyd所使用的py文件,符合执行的python解释器的语法规范即可。
python结合c语言
我们说使用cython确实能够加速代码,但肯定还是没有原生的c语言执行的快。我们将上面的代码转换成c的代码来测试一下,进而引入如何将python和c进行结合。
//1.c
longlongfunc(){
int _;
long long sum;
long i;
for (_ = 0;_ < 10000; _ ++)
{
sum = 0;
for (i = 0;i < 100000; i++)
{
sum += i;
}
}
return sum;
}
然后我们将这个1.c编译成dll,在linux中就是so,通过命令gcc -o 编译之后的dll或者so文件名 -shared c源文件编译。
我们这里就编译成mmp.dll吧:所以是gcc -o mmp.dll -shared 1.c

可以看到mmp.dll已经出现了, 下面就来调用它
import time
import ctypes
# 调用ctypes.cdll.LoadLibrary,传入dll的路径
# 这个方法就等价于dll = ctypes.CDLL("xxx.dll"),用哪种都行,但是要求dll或者so的路径是绝对路径
# 另外这两种方式在Windows上加载dll和linux上加载so都是可以的。
dll = ctypes.cdll.LoadLibrary(r"C:UserssatoriDesktoplove_minamimmp.dll")
start = time.perf_counter()
# 此时把dll看成一个模块即可,里面定义了很多函数,比如func
dll.func()
end = time.perf_counter()
print("总耗时:", end - start) # 总耗时: 2.3377831
可以看到用时不到3秒,而我使用原生的python执行需要45秒,使用cython加速也需要12秒。首先我必须指出,当sum依次从0加到100000-1时,long long存不下。但是相同功能的程序,c的速度肯定会比cython编译的pyd快,这一点可以自己测试一下,我这里就不再试了。
ctypes类型和c语言类型
我们直接调用一个函数显然是没有问题的,但如果函数里面需要参数呢?我们还能直接传递python的原生类型吗?
//计算两个数之和
intadd(int a, long b){
int sum;
sum = a + b;
return sum;
}
//查找指定字符在字符串中出现的位置
intfind_pos(char *string, char subchar){
char *p;
int pos = 0;
for (p = string; *p != '�'; p++, pos++){
if (*p == subchar)
{
return pos;
}
}
return -1;
}
import ctypes
dll = ctypes.cdll.LoadLibrary(r"C:UserssatoriDesktoplove_minamimmp.dll")
print(dll.add(100, 200)) # 300
print(dll.find_pos("satori", "a")) # -1
我们看到对于整型来说是没有问题的,但是对于字符串就有问题了,因为c中没有字符串的概念,这时候应该怎么做呢?
import ctypes
from ctypes import c_char_p, c_char
dll = ctypes.cdll.LoadLibrary(r"C:UserssatoriDesktoplove_minamimmp.dll")
# c语言中没有字符串这个概念,c语言中的字符串实际上是字符数组,c的这些概念不再介绍
# 传递一个指向字符数组的指针,同理字符a不能直接传递,需要使用c_char包装一下,并且里面需要传递字节。
print(dll.find_pos(c_char_p(b"satori"), c_char(b"a"))) # 1
所以我们来看看ctypes给我们提供了哪些类型,这些类型又对应c中的哪些类型呢?
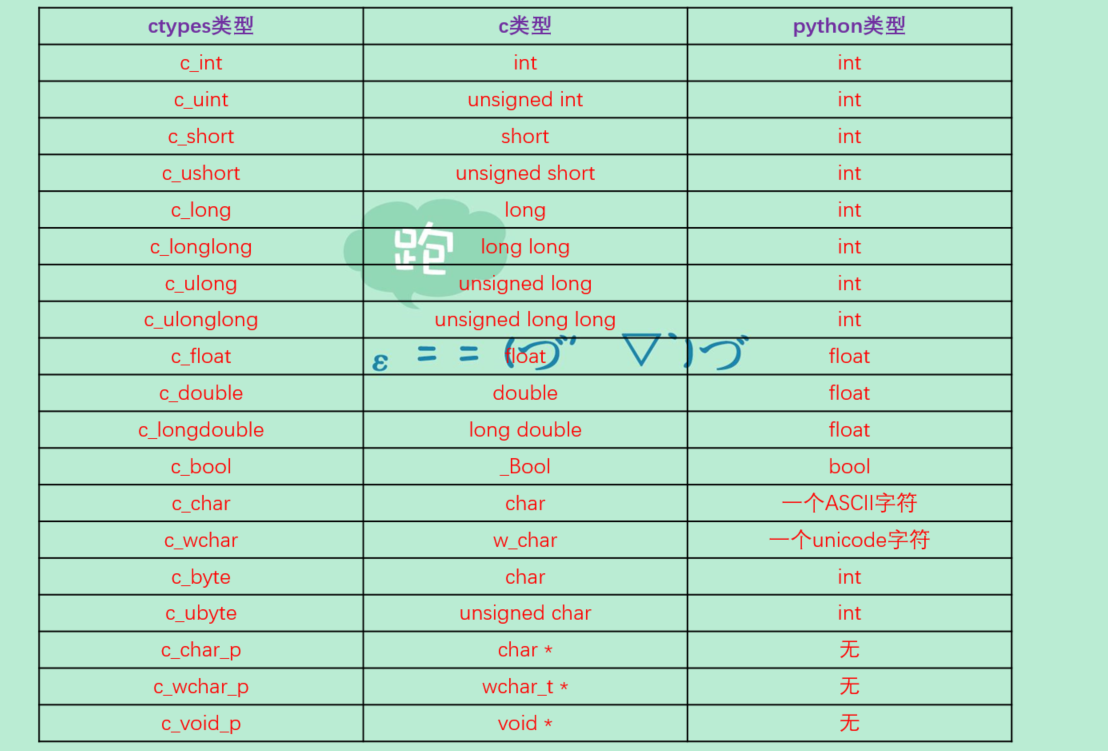
from ctypes import *
print(c_int(1)) # c_long(1)
print(c_uint(1)) # c_ulong(1)
print(c_short(1)) # c_short(1)
print(c_ushort(1)) # c_ushort(1)
print(c_long(1)) # c_long(1)
print(c_ulong(1)) # c_ulong(1)
print(c_longlong(1)) # c_longlong(1)
print(c_ulonglong(1)) # c_ulonglong(1)
print(c_float(1.1)) # c_float(1.100000023841858)
print(c_double(1.1)) # c_double(1.1)
# 在64位机器上,c_longdouble等于c_double
print(c_longdouble(1.1)) # c_double(1.1)
print(c_bool(True)) # c_bool(True)
# 必须传递一个字节或者只有一个元素的字符数组,或者一个int
# 代表c里面的字符
print(c_char(b"a"), c_char(bytearray(b"x"))) # c_char(b'a') c_char(b'x')
# 传递一个unicode字符
print(c_wchar("憨")) # c_wchar('憨')
# 和c_char类似,但是要求传递一个整型
print(c_byte(97)) # c_byte(97)
print(c_ubyte(97)) # c_ubyte(97)
# c_char_p就是c里面字符数组指针了
# char *s = "hello world";
# 那么这里面也要传递一个字符数组,字符是bytes类型,返回一个地址
print(c_char_p(b"hello world")) # c_char_p(2082736374464)
# 直接传递一个unicode,同样返回一个地址
print(c_wchar_p("憨八嘎~")) # c_wchar_p(2884583039392)
# 并且还有一个c_size_t和c_ssize_t
# 相当于c_ulonglong和c_longlong,这个和机器有关
print(c_size_t(10)) # c_ulonglong(10)
print(c_ssize_t(10)) # c_longlong(10)
当然c中各种类型,在ctypes都有对应。比如我们没有介绍的结构体等等,更复杂的用法可以参考官网。