支持多种存储引擎是众所周知的MySQL特性,也是MySQL架构的关键优势之一。如果能够理解MySQL Server与存储引擎之间是怎样通过API交互的,将大大有利于理解MySQL的核心基础架构。本文将首先介绍MySQL的整体逻辑架构,然后分析MySQL的存储引擎API并介绍如何编写自己的MySQL存储引擎。
MySQL逻辑架构
MySQL作为一个大型的网络程序、数据管理系统,架构非常复杂。下图大致画出了其逻辑架构。
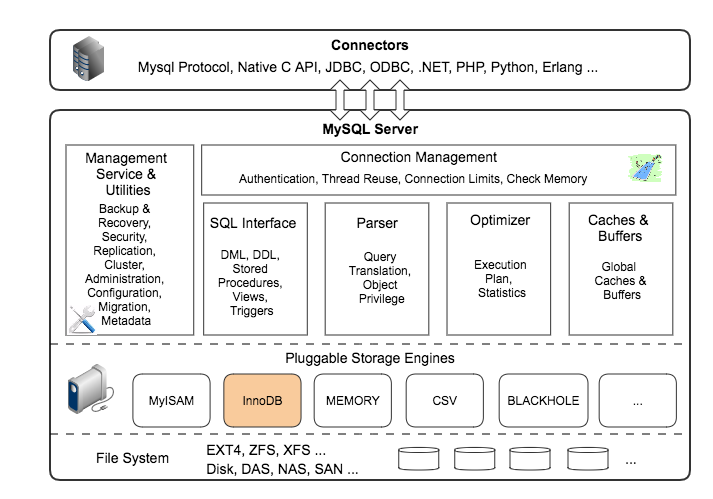
Connectors
MySQL首先是一个网络程序,其在TCP之上定义了自己的应用层协议。所以要使用MySQL,我们可以编写代码,跟MySQL Server建立TCP连接,之后按照其定义好的协议进行交互。当然这样比较麻烦,比较方便的办法是调用SDK,比如Native C API、JDBC、PHP等各语言MySQL Connector,或者通过ODBC。但通过SDK来访问MySQL,本质上还是在TCP连接上通过MySQL协议跟MySQL进行交互。
Connection Management
每一个基于TCP的网络服务都需要管理客户端链接,MySQL也不例外。MySQL会为每一个连接绑定一个线程,之后这个连接上的所有查询都在这个线程中执行。为了避免频繁创建和销毁线程带来开销,MySQL通常会缓存线程或者使用线程池,从而避免频繁的创建和销毁线程。
客户端连接到MySQL后,在使用MySQL的功能之前,需要进行认证,认证基于用户名、主机名、密码。如果用了SSL或者TLS的方式进行连接,还会进行证书认证。
SQL Interface
MySQL支持DML(数据操作语言)、DDL(数据定义语言)、存储过程、视图、触发器、自定义函数等多种SQL语言接口。
Parser
MySQL会解析SQL查询,并为其创建语法树,并根据数据字典丰富查询语法树,会验证该客户端是否具有执行该查询的权限。创建好语法树后,MySQL还会对SQl查询进行语法上的优化,进行查询重写。
Optimizer
语法解析和查询重写之后,MySQL会根据语法树和数据的统计信息对SQL进行优化,包括决定表的读取顺序、选择合适的索引等,最终生成SQL的具体执行步骤。这些具体的执行步骤里真正的数据操作都是通过预先定义好的存储引擎API来进行的,与具体的存储引擎实现无关。
Caches & Buffers
MySQL内部维持着一些Cache和Buffer,比如Query Cache用来缓存一条Select语句的执行结果,如果能够在其中找到对应的查询结果,那么就不必再进行查询解析、优化和执行的整个过程了。
Pluggable Storage Engine
存储引擎的具体实现,这些存储引擎都实现了MySQl定义好的存储引擎API的部分或者全部。MySQL可以动态安装或移除存储引擎,可以有多种存储引擎同时存在,可以为每个Table设置不同的存储引擎。存储引擎负责在文件系统之上,管理表的数据、索引的实际内容,同时也会管理运行时的Cache、Buffer、事务、Log等数据和功能。
MySQL 5.7.11默认支持的存储引擎如下:
mysql> show engines;
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
File System
所有的数据,数据库、表的定义,表的每一行的内容,索引,都是存在文件系统上,以文件的方式存在的。当然有些存储引擎比如InnoDB,也支持不使用文件系统直接管理裸设备,但现代文件系统的实现使得这样做没有必要了。
在文件系统之下,可以使用本地磁盘,可以使用DAS、NAS、SAN等各种存储系统。
存储引擎API
MySQL定义了一系列存储引擎API,以支持插件式存储引擎架构。API以Handler类的虚函数的方式存在,可在代码库下的./sql/handler.h中查看详细信息,可在handler类的注释中看到描述:
/**
The handler class is the interface for dynamically loadable
storage engines. Do not add ifdefs and take care when adding or
changing virtual functions to avoid vtable confusion
Functions in this class accept and return table columns data. Two data
representation formats are used:
1. TableRecordFormat - Used to pass [partial] table records to/from
storage engine
2. KeyTupleFormat - used to pass index search tuples (aka "keys") to
storage engine. See opt_range.cc for description of this format.
TableRecordFormat
=================
[Warning: this description is work in progress and may be incomplete]
The table record is stored in a fixed-size buffer:
record: null_bytes, column1_data, column2_data, ...
//篇幅原因,略去部分内容。
*/
class handler :public Sql_alloc
{
//篇幅原因,不列出具体代码。读者可直接在源码文件./sql/handler.h中找到具体内容。
}
下面我将分类描述部分存储引擎API。
创建、打开和关闭表
通过函数create来创建一个table:
/**
*name:要创建的表的名字
*from:一个TABLE类型的结构,要创建的表的定义,跟MySQL Server已经创建好的tablename.frm文件内容是匹配的
*info:一个HA_CREATE_INFO类型的结构,包含了客户端输入的CREATE TABLE语句的信息
*/
int create(const char *name, TABLE *form, HA_CREATE_INFO *info);
通过函数open来打开一个table:
/**
mode包含以下两种
O_RDONLY - Open read only
O_RDWR - Open read/write
*/
int open(const char *name, int mode, int test_if_locked);
通过函数close来关闭一个table:
int close(void);
对表加锁
当客户端调用LOCK TABLE时,通过external_lock函数加锁:
int ha_example::external_lock(THD *thd, int lock_type)
全表扫描
//初始化全表扫描
virtual int rnd_init (bool scan);
//从表中读取下一行
virtual int rnd_next (byte* buf);
通过索引访问table内容
//使用索引前调用该方法
int ha_foo::index_init(uint keynr, bool sorted)
//使用索引后调用该方法
int ha_foo::index_end(uint keynr, bool sorted)
//读取索引第一条内容
int ha_index_first(uchar * buf);
//读取索引下一条内容
int ha_index_next(uchar * buf);
//读取索引前一条内容
int ha_index_prev(uchar * buf);
//读取索引最后一条内容
int ha_index_last(uchar * buf);
//给定一个key基于索引读取内容
int index_read(uchar * buf, const uchar * key, uint key_len,
enum ha_rkey_function find_flag)
事务处理
//开始一个事务
int my_handler::start_stmt(THD *thd, thr_lock_type lock_type)
//回滚一个事务
int (*rollback)(THD *thd, bool all);
//提交一个事务
int (*commit)(THD *thd, bool all);
如何编写自己的存储引擎
在MySQL的官方文档上,有对于编写自己的存储引擎的指导文档,链接如下。
作为编写自己存储引擎的开始,你可以查看MySQL源码库中的一个EXAMPLE存储引擎,它实现了必须要实现的存储引擎API,可以通过复制它们作为编写我们自己存储引擎的开始:
sed -e s/EXAMPLE/FOO/g -e s/example/foo/g ha_example.h > ha_foo.h
sed -e s/EXAMPLE/FOO/g -e s/example/foo/g ha_example.cc > ha_foo.cc