一.多表操作
1.创建模型
实例:我们来假定下面这些概念,字段和关系
作者模型:一个作者有姓名和年龄。
作者详细模型:把作者的详情放到详情表,手机号,家庭住址等信息。作者详情模型和作者模型之间是一对一的关系(one-to-one)
出版商模型:出版商有名称,所在城市以及email。
书籍模型: 书籍有书名和出版日期,一本书可能会有多个作者,一个作者也可以写多本书,所以作者和书籍的关系就是多对多的关联关系(many-to-many);一本书只应该由一个出版商出版,所以出版商和书籍是一对多关联关系(one-to-many)。
(1).模型建立如下:
from django.db import models
# Create your models here.
#书籍
class Book(models.Model):
bid = models.AutoField(primary_key=True)
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=8,decimal_places=2)
pub_date = models.DateField()
publish = models.ForeignKey(to="Publish",on_delete=models.CASCADE)
authors = models.ManyToManyField(to="Author") # 多对多详情请看最下方代码
#出版社
class Publish(models.Model):
pid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
email = models.CharField(max_length=32)
#作者
class Author(models.Model):
aid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
age = models.IntegerField()
email = models.CharField(max_length=32)
authord = models.OneToOneField(to="AuthorDetail",on_delete=models.CASCADE)
#作者详细信息
class AuthorDetail(models.Model):
addr = models.CharField(max_length=32)
tel = models.IntegerField()
# authord = models.OneToOneField(Author,on_delete=models.CASCADE)
# class Author2Book(models.Model):
# id = models.AutoField(primary_key=True)
# book = models.ForeignKey(to="Book",on_delete=models.CASCADE)
# author = models.ForeignKey(to="Author",on_delete=models.CASCADE)
(2).生成如下表:
(3).注意事项:
- 表的名称myapp_modelname,是根据模型中的元数据自动生成的,也可以覆写为别的名称
id字段是自动添加的- 对于外键字段,Django 会在字段名上添加"_id" 来创建数据库中的列名
- 这个例子中的
CREATE TABLESQL 语句使用MySQL 语法格式,要注意的是Django会根据settings 中指定的数据库类型来使用相应的SQL语句。 - 定义好模型之后,你需要告诉Django _使用_这些模型。你要做的就是修改配置文件中的INSTALL_APPSZ中设置,在其中添加
models.py所在应用的名称。 - 外键字段 ForeignKey 有一个 null=True 的设置(它允许外键接受空值 NULL),你可以赋给它空值 None 。
2.添加表记录
操作前先简单的录入一些数据:
publish表:

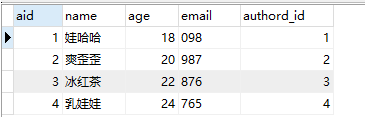
author表:
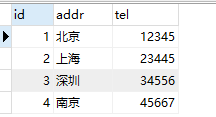
authordetail表:
(1).一对多
# 一对多的添加方式 # 方式一: # pub_obj = Publish.objects.filter(name = "北京大学出版社").first() # print(pub_obj) # book = Book.objects.create( title="python入门",price=120,pub_date="2011-07-9",publish=pub_obj ) # 方式二: # book = Book.objects.create(title="Java入门",price=111,pub_date="2008-8-9",publish_id=3) #推荐 #示例: # author = Author.objects.create(name="冰红茶",age=22,email="876",authord_id=3)
核心:book.publish与book.publish_id是什么?
(2).多对多
#多对多的添加方式 # book = Book.objects.create(title="计算机文化基础",price=50,pub_date="2004-6-2",publish_id=5) # 方式一: # whh = Author.objects.filter(name = "娃哈哈").first() # shuangww = Author.objects.filter(name = "爽歪歪").first() # book.authors.add(whh,shuangww) #方式二: # book.authors.add(3) # 方式三: # book.authors.add(*[2,4])
核心:book.authors是什么?
(3).多对多关系其它常用API:
book_obj.authors.remove() # 将某个特定的对象从被关联对象集合中去除。 ====== book_obj.authors.remove(*[]) book_obj.authors.clear() #清空被关联对象集合 book_obj.authors.set() #先清空再设置
# 解除绑定
# whh = Author.objects.filter(name='娃哈哈').first()
# book = Book.objects.filter(pk = 4).first()
# # book.authors.remove(1)
# book.authors.clear()
#解除再绑定
# book = Book.objects.filter(pk = 5).first()
# 方法一:
# book.authors.clear()
# book.authors.add(1)
# 方法二:
# book.authors.set("1")
3.基于对象的跨表查询
正向查询:关联属性所在的表查询相关联表记录 反向查询:得到一个对象,按表名小写
(1).一对多查询(Publish与Book)
"""
正向查询:按字段:book.publish
Book ---------------------------------> Publish
<--------------------------------
反向查询:按表名小写_set.all() 例:pub_obj.book_set.all()
"""
# 1.查询python入门这本书出版社的名字和邮箱
#方式一:分步查询,不用关联键值
# book = Book.objects.filter(title="python入门").first()
# pub_obj = Publish.objects.filter(pk = book.publish_id).first()
# print(pub_obj.name)
# print(pub_obj.email)
#方式二:关联键值查询
# book = Book.objects.filter(title="python入门").first()
# print(book.publish) #与book这本书关联的出版社对象
# print(book.publish.name) #与book这本书关联的出版社对象的可调用方法
# print(book.publish.email) #与book这本书关联的出版社对象的可调用方法
# 2.查询北京大学出版社出版的所有的书籍的名称
# pub_obj = Publish.objects.get(name="北京大学出版社")
# print(pub_obj.book_set.all()) #输出一个QuerySet对象
# print(pub_obj.book_set.all().values("title")) #输出一个QuerySet对象
(2).多对多查询(Author与Book)
"""
正向查询:按字段:book.authors.all()
Book ----------------------------------> Author
<---------------------------------
反向查询:按表名小写_set.all() 例:bgc.book_set.all()
"""
# #1.查询python入门这本书的作者的年龄
# book = Book.objects.filter(title="python入门").first()
# ret = book.authors.all().values("age") #与这本书关联的所有作者的queryset的集合
# print(ret)
# #2.查询冰红茶出版过的所有的书籍名称
# bgc = Author.objects.filter(name="冰红茶").first()
# print(bgc.book_set.all().values("title"))
(3).一对一查询(Author与AuthorDetail)
"""
正向查询:按字段:爽歪歪.authord
Author ------------------------------> AuthorDetail
<-----------------------------
反向查询:按表名小写:authord.author
"""
# #1.查询爽歪歪的手机号
# shuangww = Author.objects.filter(name="爽歪歪").first()
# print(shuangww.authord.tel)
# #2.查询手机号为12345的作者的名字
# authord = AuthorDetail.objects.filter(tel=12345).first()
# print(authord.author.name)
4.基于双下划线的跨表查询
Django 还提供了一种直观而高效的方式在查询(lookups)中表示关联关系,它能自动确认 SQL JOIN 联系。要做跨关系查询,就使用两个下划线来链接模型(model)间关联字段的名称,直到最终链接到你想要的model 为止。
'''
正向查询按字段,反向查询按表名小写用来告诉ORM引擎join哪张表
'''
#####################基于双下划线的跨表查询(基于join实现的)##########################
#KEY: 正向查询:按字段,反向查询:按表名小写
# 1.查询python入门这本书出版社的名字
# ret = Book.objects.filter(title="python入门").values("price")
# 方式一:
# ret = Book.objects.filter(title="python入门").values("publish__name")
# print(ret)
#方式二:
# ret = Publish.objects.filter(book__title="python入门").values("name")
# print(ret)
# 2.查询人民出版社出版的所有书籍的名称
# 方式一:
# ret = Publish.objects.filter(name="人民出版社").values("book__title")
# print(ret)
# 方式二:
# ret = Book.objects.filter(publish__name="人民出版社").values("title")
# print(ret)
# 3.查询Python高阶这本书籍的作者的姓名和年龄
# 方式一:
# ret = Book.objects.filter(title="Python高阶").values("authors__name","authors__age")
# print(ret)
# 方式二:
# ret = Author.objects.filter(book__title="Python高阶").values("name","age")
# print(ret)
# 4.查询冰红茶出版过的所有的书籍名称
# 方式一:
# ret = Book.objects.filter(authors__name="冰红茶").values('title')
# print(ret)
# 方式二:
# ret = Author.objects.filter(name="冰红茶").values("book__title")
# print(ret)
# 5.查询乳娃娃的手机号
# 方式一:
# ret = Author.objects.filter(name="乳娃娃").values("authord__tel")
# print(ret)
# 方式二:
# ret = AuthorDetail.objects.filter(author__name="乳娃娃").values("tel")
# print(ret)
# 6.查询手机号为12345的作者的名字
# 方式一:
# ret = AuthorDetail.objects.filter(tel=12345).values('author__name')
# print(ret)
# 方式二:
# ret = Author.objects.filter(authord__tel=12345).values("name")
# print(ret)
#########连续跨表#############
# 1.查询南京大学出版社出版过的所有书籍的名字以及作者的姓名
# 方式一:
# ret = Publish.objects.filter(name="南京大学出版社").values("book__title","book__authors__name")
# print(ret)
# 方式二:
# ret = Book.objects.filter(publish__name="南京大学出版社").values("title","authors__name")
# print(ret)
# 2.手机号以345开头的作者出版过的所有书籍名称以及出版社名称
# 方式一:
# ret = Author.objects.filter(authord__tel__startswith=345).values("book__title","book__publish__name")
# print(ret)
# 方式二:
# ret = AuthorDetail.objects.filter(tel__startswith = 345).values("author__book__title","author__book__publish__name")
# print(ret)
#方式三:
# ret = Book.objects.filter(authors__authord__tel__startswith=345).values("title","publish__name")
# print(ret)
5.聚合查询与分组查询
(1).添加一个新的员工表
class Emp(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField(default=20)
dep = models.CharField(max_length=32)
pro = models.CharField(max_length=32)
salary = models.DecimalField(max_digits=8,decimal_places=2)
bonus = models.DecimalField(max_digits=8,decimal_places=2)

(2).聚合
aggregate(*args, **kwargs)
from django.db.models import Avg, Max, Min, Sum, Count
#聚合
# 1.查询所有书籍的平均价格
# ret = Book.objects.all().aggregate(priceAvg = Avg("price"))
# print(ret)
# 2.查询所有书籍的个数
# ret = Book.objects.all().aggregate(c = Count(1))
# print(ret)
aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。如果你想要为聚合值指定一个名称,可以向聚合子句提供它。
如果你希望生成不止一个聚合,你可以向aggregate()子句中添加另一个参数。所以,如果你也想知道所有图书价格的最大值和最小值,可以这样查询:
# 1.查询所有书籍的平均价格
# ret = Book.objects.all().aggregate(priceAvg = Avg("price"), price_max = Max("price"), price_min = Min("price"))
# print(ret)
(3).分组
#分组
#单表分组查询
# KEY:annotate()前values哪一个字段就按哪一个字段 group by
# 1.查询书籍表每一个出版社id以及对应的书籍个数
# ret = Book.objects.all().values("publish_id").annotate(c = Count(1)) # .all()可以省略
# print(ret)
# 2.查询每一个部门的名称以及对应的员工的平均薪水
# ret = Emp.objects.values("dep").annotate(avg_salary = Avg("salary"))
# print(ret)
# 3.查询每个省份的名称以及对应的员工的最大年龄
# ret = Emp.objects.values("pro").annotate(max_age = Max('age'))
# print(ret)
#单表按主键查询无意义
# Emp.objects.values("pk").annotate()
#跨表分组查询
# 1.查询每一个出版社的名称以及对应的书籍平均价格
# ret = Publish.objects.values("name").annotate(avg_price=Avg("book__price"))
# print(ret)
# 2.查询每一个作者的名字以及出版的书籍的最高价格
# ret = Author.objects.values("pk","name").annotate(max_price=Max("book__price"))
# print(ret)
# 3.查询每一个书籍的名称以及对应的作者的个数
# ret = Book.objects.values("title").annotate(c = Count("authors"))
# print(ret)
#########补充############
# 拿上面3题来说
# ret = Book.objects.annotate(c = Count("authors")).values("title","c") # 省略了.all()和.values()默认以book表中每条记录作为分组对象,返回分组后的book表,但其中包含c字段
# print(ret)
# 1.查询作者数不止一个的书籍名称以及作者个数
# ret = Book.objects.annotate(c = Count("authors")).filter(c__gt = 1).values("title","c")
# print(ret)
# 2.根据一本图书作者数量的多少查询集,QuerySet进行排序
# ret = Book.objects.annotate(c = Count("authors")).values("title").order_by("c")
# print(ret)
# 3.统计每一本以py开头的书籍的名称以及作者个数
# ret = Book.objects.filter(title__istartswith="py").annotate(c = Count("authors")).values("title")
# print(ret)
annotate()为调用的QuerySet中每一个对象都生成一个独立的统计值(统计方法用聚合函数)
总结 :跨表分组查询本质就是将关联表join成一张表,再按单表的思路进行分组查询。
6.F查询与Q查询
F:将两个字段的做比较
Q:或,与,非
###############################F 与 Q###############################
from django.db.models import F,Q
# 1.查询价格大于100的所有书籍的名称
# ret = Book.objects.filter(price__gt=100).values("title")
# print(ret)
# 2.查询奖金大于等于2倍工资的所有的员工名称
# ret = Emp.objects.filter(bonus__gte=F("salary")*2).values("name")
# print(ret)
# 3.给每个员工加1000块工资
# ret = Emp.objects.update(salary=1000+F("salary"))
# print(ret)
# 与:& 或:| 非:~
# 4.查询工资大于5000或者奖金大于5000的员工
#错误:
# ret = Emp.objects.filter(salary__gt=5000,bonus__gt=5000) #这是"且"查不到值
# print(ret) #<QuerySet []>
#正确:
# ret = Emp.objects.filter(Q(salary__gt=5000)|Q(bonus__gt=5000)).values("name")
# print(ret)
# 5.Q的示例用法:
# ret = Emp.objects.filter(Q(Q(salary__gt=5000)|~Q(bonus__gt=5000))&Q(age__gt=30)).values("name")
# print(ret)
# ret = Emp.objects.filter(Q(Q(salary__gt=5000)|~Q(bonus__gt=5000)),age__gt=30).values("name")
# print(ret)
# ret = Emp.objects.filter(age__gt=30,Q(Q(salary__gt=5000) | ~Q(bonus__gt=5000))).values("name") #错误
# print(ret)