5.5 高可用的数据
保证数据存储高可用的手段主要是数据备份和失效转移机制。
数据备份是保证数据有多个副本,任意副本的失效都不会导致数据的永久丢失,从而实现数据完全的持久化。
而失效转移机制则保证当一个数据副本不可访问时,可以快速切换访问数据的其他副本,保证系统可用。
缓存不是数据存储服务,缓存服务器宕机引起缓存数据丢失导致服务器负载压力过高应通过其他手段解决,而不是提高缓存服务本身的高可用。
对于缓存服务器集群中的单机宕机,如果缓存服务器集群规模较大,那么单机宕机引起的缓存数据丢失比例和数据库负载压力变化都较小,对整个系统影响也较小。
扩大缓存服务器集群规模的一个简单手段就是整个网站共享同一个分布式缓存集群,单独的应用和产品不需要部署自己的缓存服务器,只需要向共享缓存集群申请缓存资源即可。
并且可以通过逻辑或物理分区的方式将每个应用的缓存部署在多台服务器上,任何一台服务器宕机引起的缓存失效都只影响应用缓存数据的一小部分,不会对应用性能和数据库负载造成太大影响。
5.5.1 CAP原理
高可用数据的几层含义
数据持久性
保证数据可持久存储,在各种情况下都不会出现数据丢失。数据要冗余备份
数据可访问性
数据存储设备损坏时,需要很快切换到另一个存储设备上,终端用户几乎没有感知。
数据一致性
在数据有多份副本的情况下,如果网络、服务器或者软件出现故障,会导致部分副本写入成功,部分副本写入失败。
这就会造成各个副本之间的数据不一致,数据内容冲突。
比如,数据更新返回操作失败,事实上数据在存储服务器已经更新成功。
CAP原理认为,一个提供数据服务的存储系统无法同时满足数据一致性(Consistency)、数据可用性(Availibility)、分区忍耐性/分区容错性(Patition Tolerance,系统具有跨网络分区的伸缩性)这三个条件
在大型网站应用中,数据规模总是快速扩张的,因此可伸缩性即分区忍耐性必不可少,规模变大以后,机器数量也会变得庞大,这时网络和服务器故障会频繁出现,要想保证应用可用,就必须保证分布式处理系统的高可用性。
所以大型网站中,通常会选择强化分布式存储系统的可用性(A)和伸缩性(P),而在某种程度上放弃一致性(C)。
一般来说,数据不一致通常出现在系统高并发写操作或者集群状态不稳(故障恢复、集群扩容。。。)的情况下,应用系统需要对分布式数据处理系统的数据不一致有所了解并进行某种意义上的补偿和纠错,以避免出现应用系统数据不正确。
CAP原理对于可伸缩的分布式系统设计具有重要意义,在系统设计开发过程中,不恰当地迎合各种需求,企图打造一个完美的产品,可能会使设计进入两难境地,难以为继。
具体说来,数据一致性又可分为如下几点:
数据强一致
各个副本的数据在物理存储中总是一致的;
数据更新操作的结果和操作响应总是一致的,即操作响应通知更新失败,那么数据一定没有被更新,而不是处于不确定状态。
数据用户一致
即数据在物理存储中的各个副本的数据可能不一致,但是终端用户访问时,通过纠错和校验机制,可以确定一个一致的且正确的数据返回给用户。
数据最终一致
这是数据一致性中较弱的一种,即物理存储的数据可能是不一致的,终端用户访问到的数据可能也是不一致的(同一用户连续访问,结果不同;或者不同用户同时访问,结果不同 ),但系统经过一段时间(通常是一个比较短的时间段)的自我恢复和修正,数据最终会达到一致。
因为难以满足数据强一致性,网站通常会综合成本、技术、业务场景等条件,结合应用服务和其他的数据监控与纠错功能,使存储系统达到用户一致,保证最终用户访问数据的正确性。
5.5.2 数据备份
数据冷备:
定期将数据复制到某种存储介质上并物理存档保存,如果系统存储损坏,那么就从冷备的存储设备中恢复数据。
冷备不能保证数据最终一致,因为是定期备份,如果系统数据丢失,那么从上个备份点开始后更新的数据就会永久丢失,不能从备份中恢复。
同时也不能保证数据可用性,从冷备存储中恢复数据需要较长的时间,而这段时间无法访问数据,系统也不可用。
冷备一般在日常运维中使用,而在网站实时在线业务中,还需要进行数据热备,以提供更好的数据可用性。
数据热备分为两种:
异步热备方式和同步热备方式。
异步方式是指多份数据副本的写入操作异步完成,应用程序收到数据服务系统的写操作成功响应时,只写成功了一份,存储系统将会异步地写其他副本(这个过程有可能会失败)。
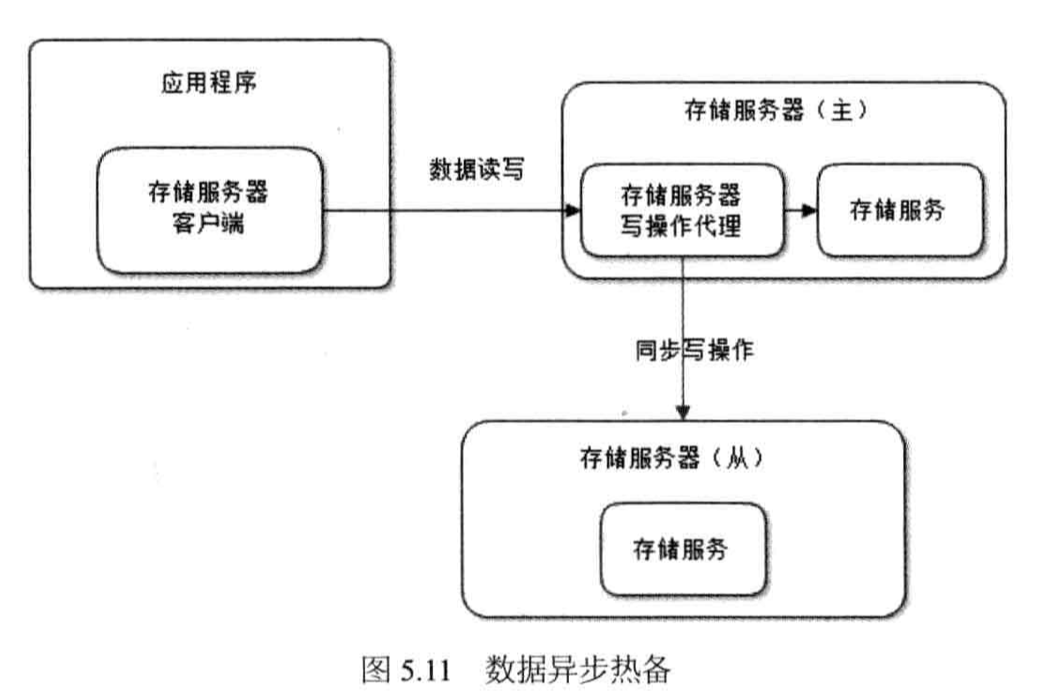
在异步写入方式下,存储服务器分为主存储服务器(Master)和从存储服务器(Slave),应用程序正常情况下只连接主存储服务器,数据写入时,由主存储服务器的写操作代理模块将数据写入本机存储系统后立即返回写操作成功响应,然后通过异步线程将写操作数据同步到从存储服务器。
同步方式是指多份数据副本的写入操作同步完成,即应用程序收到数据服务系统的写成功响应时,多份数据都已经写操作成功。
但是当应用程序收到数据写操作失败的响应时,可能有部分副本或者全部副本都已经写成功了(因为网络或者系统故障,无法返回操作成功的响应)
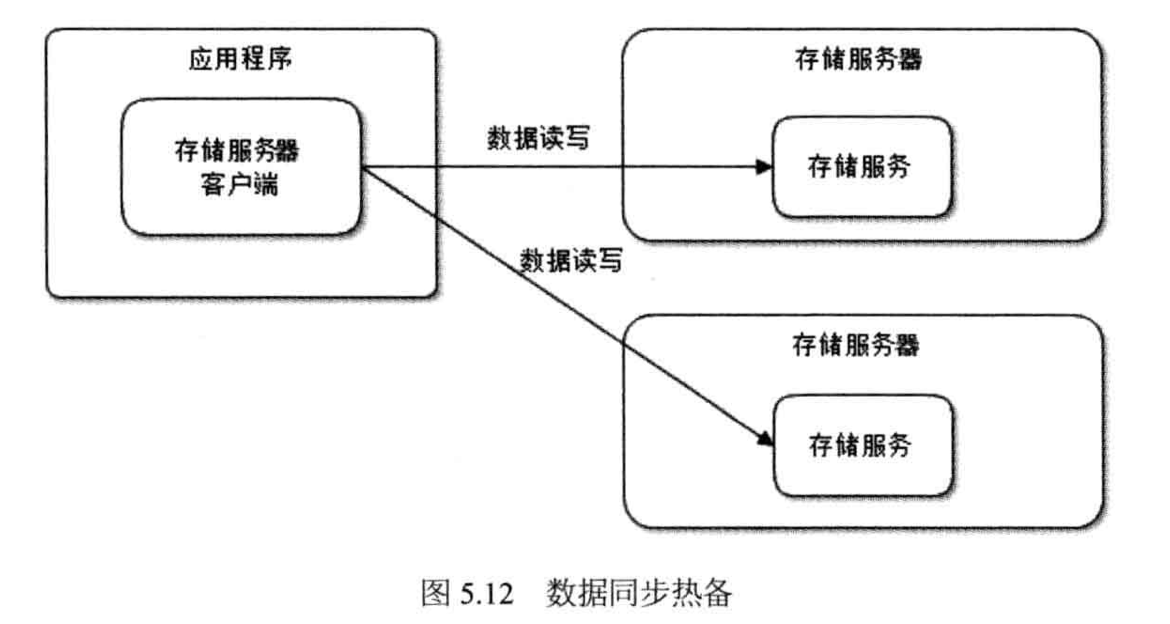
同步热备具体实现的时候,为了提高性能,在应用程序客户端并发向多个存储服务器同时写入数据,然后等待所有存储服务器都返回操作成功的响应后,再通知应用程序写操作成功。
这种情况下,存储服务器没有主从之分,完全对等,更便于管理和维护。存储服务客户端在写多份数据的时候,并发操作,这意味着多份数据的总写操作延迟是响应最慢的那台存储服务器的响应延迟,而不是多台存储服务器响应延迟之和。其性能和异步热备方式差不多。
关系数据库热备机制就是通常所说的Master-Slave同步机制。Master-Slave机制不但解决了数据备份问题,还改善了数据库系统的性能,实践中,通常使用读写分离的方法访问Slave和Master数据库,写操作只访问Master数据库,读操作只访问Slave数据库。
5.5.3 失效转移
若数据服务器集群中任何一台服务器宕机,那么应用程序针对这台服务器的所有读写操作都需要重新路由到其他服务器,保证数据访问不会失败,这个过程叫作失效转移。
失效转移操作由三部分组成:失效确认、访问转移、数据恢复。
1、失效确认
判断服务器宕机是系统进行失效转移的第一步,系统确认一台服务器是否宕机的手段有两种:心跳检测和应用程序访问失败报告。
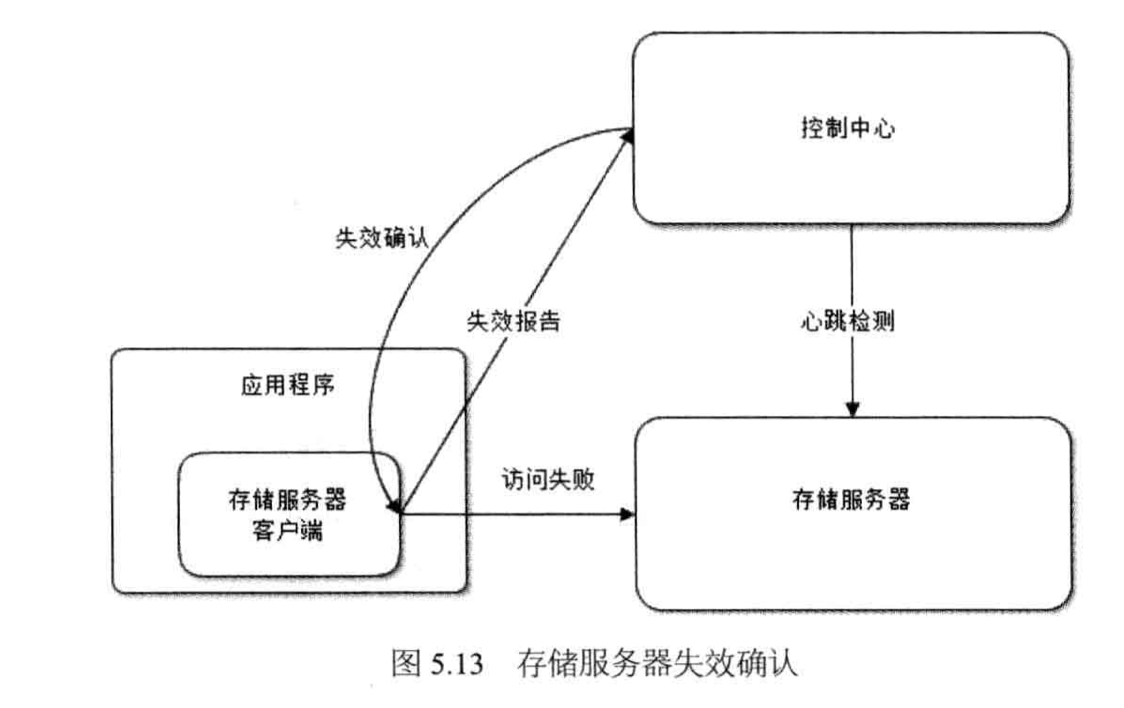
对于应用程序的访问失败报告,控制中心还需要再发一下心跳检测进行确认,以免错误判断服务器宕机,因为一旦进行数据访问的失效转移,就意味着数据存储多份副本不一致,需要进行后续一系列复杂的操作。
2、访问转移
确认某台数据存储服务器宕机后,就需要将数据读写访问重新路由到其他服务器上。
对于完全对等存储的服务器,当其中一台宕机后,应用程序跟进配置直接切换到对等服务器上。
如果存储是不对等的,那么就需要重新计算路由,选择存储服务器。
3、数据恢复
因为某台服务器宕机,所以数据存储的副本数目会减少,必须将副本的数目恢复到系统设定的值,否则,再有服务器宕机时,就可能出现无法访问转移,数据永久丢失的情况。
因此系统需要从健康的服务器复制数据,将数据副本数目恢复到设定值。具体设计可参考第11章。