本文首发于:行者AI
在接口自动化测试过程中不仅仅有单接口的测试,场景测试也必不可少,这就造成接口与接口之间存在传值问题,下面介绍一下在 pytest 框架下怎样进行接口传值处理。
接口数据总体可分为前置处理和后置处理:
前置处理:一些固定值或固定方法的调用
后置处理:需要前几个请求中的body(参数)、response(响应)
1. 数据准备
前置处理:
前置处理用<>和[]来标记(标记符可按自己需求进行更改)
正则匹配数据中包含这两种标记时,读取调用methlib.py或config.py中的方法,具体调用哪个固定值或方法,根据标记里面写入的参数调用,并对数据进行替换。其中<>用于标记固定值,[]用于标记固定方法;

后置处理:
后置处理用&&、{}、==、##来标记(标记符可按自己需求进行更改)
正则匹配数据中包含这几种标记时,读取requestmsg.txt中数据,具体读取哪一行数据,根据关联列的数据进行判断,并对数据进行替换。其中&&用于标记取上一步的body、{}用于标记取上一步的response、==用于标记取前几步的body、##用于标记前上几步的response;

注:
① excel表中的用例传参数据需要以字典形式写入。
② 表格数据中加入关联列,用于判断读取第几个请求的参数或响应。
③ 对于部分接口需要加密的接口,在表格数据中加入是否加密列,用于判断该接口的参数是否加密。
2. 测试流程
前置处理:
读取到的excel表格数据是一个模块的数据,经过pytest的处理,会将模块中的多个接口数据(列表)进行单个接口的传输,是不用经过任何请求得到的数据,所以将其放在单独的数据处理中。下面是仅经过前置处理的流程;

后置处理:
需要经过前面几个接口的请求或响应而得到的数据,所以必须将其放在request请求之前,并且每发送一个接口请求,都需要在request.txt中写入该请求的body和response,以便给后面的接口使用。下面是仅经过后置处理的流程;
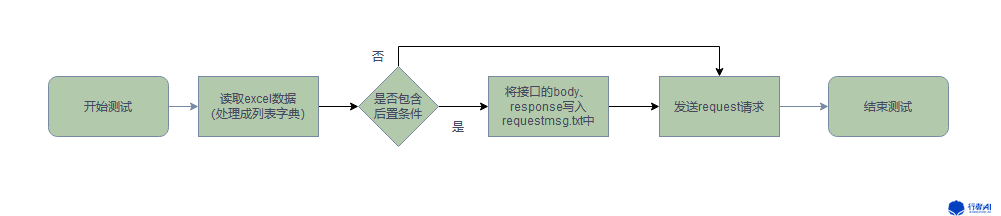
下面是经过前置和后置处理的接口测试流程;

3. 代码实现
前置处理的实现:前置处理与其他请求的参数、响应无关,所以可以整个模块进行处理。
def param_method(dic_param):
"""
固定值、取方法(不需要上一步的body和response)
:param dic_param: 必须是个字典(data里面的参数)
:return:
"""
temp_mobile_ = []
temp_email_ = []
temp_pid_ = []
for j in dic_param.keys():
value__ = dic_param[j]
_ = re.findall(r'<(.*?)>', str(value__)) # 固定值
__ = re.findall(r'[(.*?)]', str(value__)) # 取方法
if _: # 判断是否存在apk固定传值
dic_param[j] = param[f'{_[0]}']
if __:
if j == 'mobile' or 'phone' or 'phoneNum':
dic_param[j] = mobile()
temp_mobile_.append(dic_param[j])
if j == 'email':
dic_param[j] = email()
temp_email_.append(dic_param[j])
if j == 'pid':
dic_param[j] = pid()
temp_pid_.append(dic_param[j])
if j == 'app_order_id':
dic_param[j] = get_random_str(30)
return dic_param
后置处理的实现:后置处理与其他请求的参数、响应相关,所以必须在每个请求之前进行处理,下面展示的是后置处理的方法,由于代码过长,只展示了部分后置处理代码。
def prev_body_res(dic_param, relevance=None):
'''
取上步body、取上步response,当relevance不为空时取上几步body、response
:param dic_param: 必须是字典格式
:return:
'''
request_file = r'./requestsmsg.txt'
for j in dic_param.keys():
value__ = dic_param[j]
___ = re.findall(r'&(.*?)&', str(value__)) # 取上步body
____ = re.findall(r'{(.*?)}', str(value__)) # 取上步response
_____ = re.findall(r'#(.*?)#', str(value__)) # 取前几步的response
______ = re.findall(r'=(.*?)=', str(value__)) # 取前几步的body
if ___:
request_res = readtxt(request_file)
request_body = request_res[1]
key = ___[0]
res_data = request_body[f'{key}']
dic_param[j] = str(res_data)
if ____:
request_response = readtxt(request_file)
request_response = request_response[0]
key = ____[0]
res_data = request_response['data']
if res_data:
if isinstance(res_data, list):
temp_value = get_dict_value(request_response['data'][0], key)
dic_param[j] = temp_value[0]
temp_value.clear()
else:
temp_value = request_response['data'][f'{key}']
dic_param[j] = str(temp_value)
后置处理具体应用:由于后置处理需要前面的请求完成之后才能得到想要的数据,所以具体后置处理放在每个请求处理之前,下面展示的是具体请求的应用。
else: # 传值
line_data = prev_body_res(line_data, relevance_no)
if i['encryption'] == '0': # 不加密
if header['Content-Type'] == 'application/json':
response = requests.request(f'{request_type}', url=url, headers=header, data=json.dumps(line_data))
write_request(response.json(), no, line_data)
logger.info(f'response:{response.json()},no:{no},body:{line_data}')
基于pytest实现的模块传值处理:以数据准备中的邮箱登录模块为例:parametrize这个装饰器可以将整个模块的数据进行逐一发送给下面定义的方法。
@allure.story('邮箱登录')
@pytest.mark.qa
@pytest.mark.formal
@pytest.mark.parametrize('excel_data', change_data(module_data('邮箱登录'), len(module_data('邮箱登录'))))
def test_login_email(self, excel_data):
response = decide_value_relevance(excel_data)
judge_result(response, '邮箱登录')
title = excel_data['title']
allure.dynamic.title(f'邮箱登录:{title}')
4. 总结
基于pytest我们可以将我们需要测试的场景以模块形式组装起来,再利用传值,就可构建出多个不同的正常、异常场景,增加关联性;利用表格来构建数据,也增加了构建脚本的灵活性;后期还有许多优化的地方,希望和大家一起来探讨。
PS:更多技术干货,快关注【公众号 | xingzhe_ai】,与行者一起讨论吧!