学习链接http://stu.ityxb.com/openCourses/detail/238
什么是爬虫:
网络爬虫就是模拟浏览器发送网络请求 接受请求响应 按照一定规则 自动抓取互联网信息的程序
爬虫的用途:
数据采集(百度新闻,今日头条)、12306抢票、网络自动投票、
调试工具:
Fn+ F12

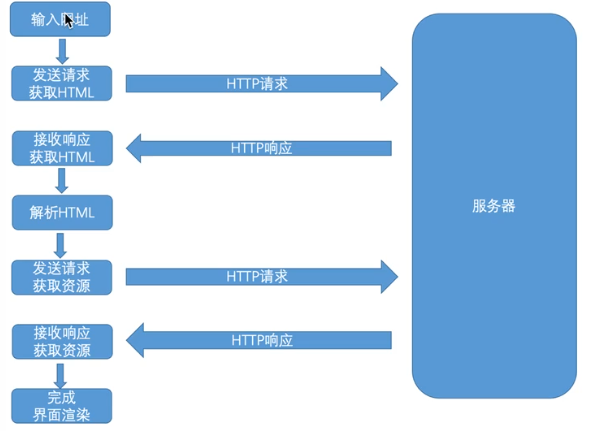
浏览器的请求过程:
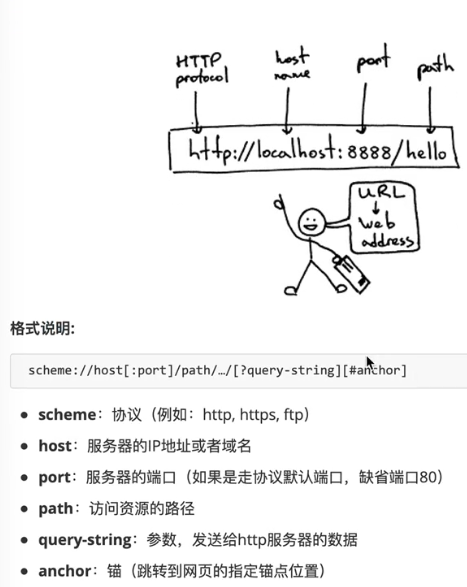
URL规则
 、
、
http请求

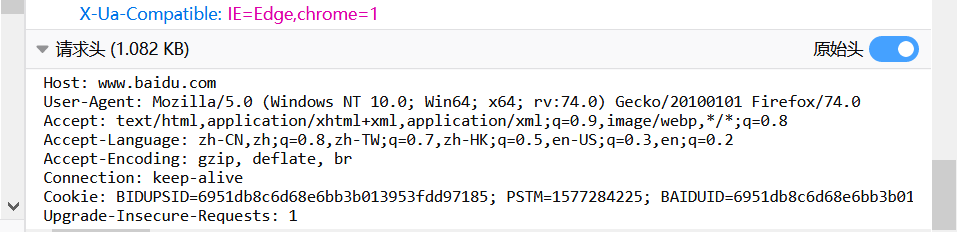

http请求重要组成部分
请求URL、请求方式 (post、GET)、请求头 、请求体
http响应格式
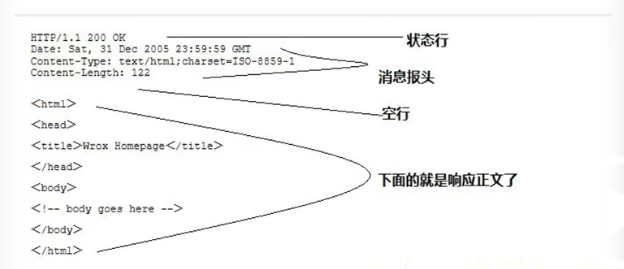
http响应重要组成部分
响应状态码:404、500 、200(成功)
响应头 、
响应体(html内容)
Ruquests模块
是一个python模块,可以模拟浏览器发送请求获取响应
学习资料:
http://cn.python-requests.org/zh_CN/latest/
安装
pip install requests
爬取网站步骤:
步骤一:分析
请求url、请求方式、请求头、请求参数
''' url https://www.baidu.com/baidu?wd=%E7%9F%B3%E5%AE%B6%E5%BA%84%E5%AD%A6%E9%99%A2 请求方式 get 请求头 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0 请求参数 ?wd=%E7%9F%B3%E5%AE%B6%E5%BA%84%E5%AD%A6%E9%99%A2 '''
步骤二:模拟浏览器发送请求获取响应
''' url https://www.baidu.com/baidu?wd=%E7%9F%B3%E5%AE%B6%E5%BA%84%E5%AD%A6%E9%99%A2 请求方式 get 请求头 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0 请求参数 ?wd=%E7%9F%B3%E5%AE%B6%E5%BA%84%E5%AD%A6%E9%99%A2 ''' # 1.导入模块 import requests #2. 模拟发送请求获取响应 response = requests.get( url = " https://www.baidu.com/baidu/s", headers={ "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0", } ) #3. 对响应内容结果进行处理 with open ('获取响应内容.html' , 'w',encoding='utf8') as f: f.write(response.text)
实现自定义请求参数
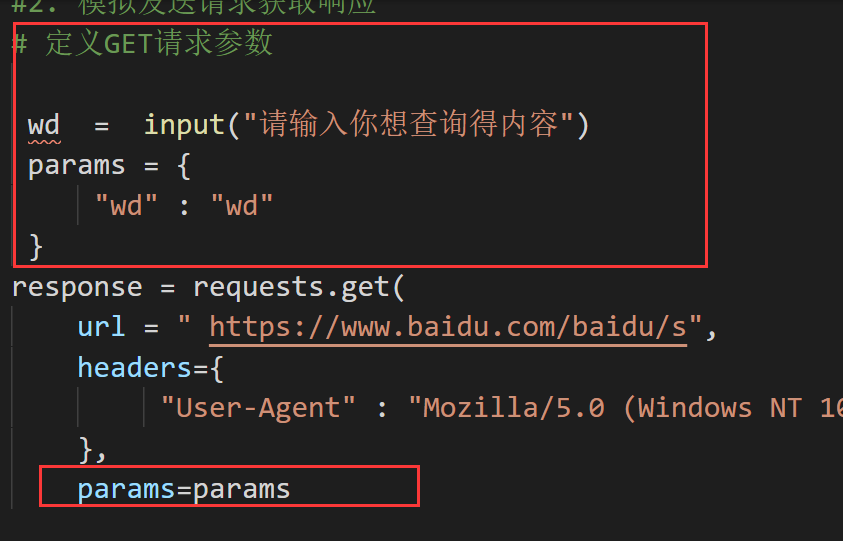
# 1.导入模块 import requests #2. 模拟发送请求获取响应 # 定义GET请求参数 wd = input("请输入你想查询得内容") params = { "wd" : "wd" } response = requests.get( url = " https://www.baidu.com/baidu/s", headers={ "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0", }, params=params ) #3. 对响应内容结果进行处理 with open ('获取响应内容.html' , 'w',encoding='utf8') as f: f.write(response.text)
response 常用属性

#获取响应状态码.响应头 响应内容 print(response.status_code) print(response.headers) print(response.text) print(response.content)
# 1.导入模块 import requests #2. 模拟发送请求获取响应 # 定义GET请求参数 wd = input("请输入你想查询得内容") params = { "wd" : "wd" } response = requests.get( url = " https://www.baidu.com/baidu/s", headers={ "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0", }, params=params ) # response 常用属性 # 获取响应状态码.响应头 响应内容 print(response.status_code) print(response.headers) print(response.text) print(response.content)
模拟浏览器获取讲师页面内容
''' url http://www.itheima.com/teacher.html 请求方式 get 请求头 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0 请求参数 ''' #1.导入模块 import requests # 2.发送请求响应 response = requests.get ( url = " http://www.itheima.com/teacher.html", headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0"} ) # 3.处理响应 print(response.text)
XPath介绍 :
通过一定语法规则从html/xml文件中获取数据
XPath语法学习搭建
-XPath基本语法
XPath高级语法使用
使用lxml对html数据进行提取演练
-利用XPath提取教师数据
总结