1. 简介
Guava Cache是指在JVM的内存中缓存数据,相比较于传统的数据库或redis存储,访问内存中的数据会更加高效,无网络开销。
根据Guava官网介绍,下面的这几种情况可以考虑使用Guava Cache:
1. 愿意消耗一些内存空间来提升速度。
2. 预料到某些键会被多次查询。
3. 缓存中存放的数据总量不会超出内存容量。
因此,Guava Cache特别适合存储那些访问量大、不经常变化、数据量不是很大的数据,以改善程序性能。
2. 类图

Guava Cache的类图中,主要涉及了5个类:CacheBuilder、LocalCache、Segment、EntryFactory和ReferenceEntry,大部分业务逻辑都在前面三个类,依次介绍如下:
2.1 CacheBuilder
CacheBuilder是一个用于构建Cache的类,是建造者模式的一个例子,主要的方法有:
- maximumSize(long maximumSize): 设置缓存存储的所有元素的最大个数。
- maximumWeight(long maximumWeight): 设置缓存存储的所有元素的最大权重。
- expireAfterAccess(long duration, TimeUnit unit): 设置元素在最后一次访问多久后过期。
- expireAfterWrite(long duration, TimeUnit unit): 设置元素在写入缓存后多久过期。
- concurrencyLevel(int concurrencyLevel): 设置并发水平,即允许多少线程无冲突的访问Cache,默认值是4,该值越大,LocalCache中的segment数组也会越大,访问效率越高,当然空间占用也大一些。
- removalListener(RemovalListener<? super K1, ? super V1> listener): 设置元素删除通知器,在任意元素无论何种原因被删除时会调用该通知器。
- setKeyStrength(Strength strength): 设置元素的key是强引用,还是弱引用,默认强引用,并且该属性也指定了EntryFactory使用是强引用还是弱引用。
- setValueStrength(Strength strength) : 设置元素的value是强引用,还是弱引用,默认强引用。
2.2 LocalCache
LocalCache是一个支持并发访问的Hash Map,它实现了ConcurrentMap,其内部会持有一个segment数组,元素的增删改查都是通过调用segment的对应方法来实现的,
其主要的方法有:
- get(Object key): 查询一个key,内部实现是调用了Segment的get方法。
- public V put(K key, V value): 添加一个对象到cache中,内部实现是调用了Segment的put方法。
- remove(Object key) : 删除一个key,内部实现是调用了Segment的remove方法。
- replace(K key, V value):更新一个key,内部实现是调用了Segment的update方法。
2.3 Segment
segment是实际元素的持有者,它内部持有一个table数组,数组的每个元素又对应一个链表,链表上则保存了实际的元素,它的主要方法对应LocalCache提供的增删改查的接口,这里就不再啰嗦了。
2.4 EntryFactory
EntryFactory是entry的创建工厂,可支持创建强引用、弱引用、强读引用、强写引用、强读写引用、弱读引用、弱写引用、弱读写引用等类型的元素。
强引用和弱引用就是java四种引用类型里面的强弱引用,默认是强引用,而读引用是指创建的元素会记录最后一次的访问时间,如果用户在CahceBuilder中调用了expireAfterAccess或者maximumWeight则会使用读引用类型的工厂,写引用类型也是同样的逻辑。
2.5 ReferenceEntry
ReferenceEntry是元素的接口定义,它的实现类就是EntryFactory中创建的元素,包含了8种类型的元素,元素中至少包含了key、value和hash三个字段,其中hash是当前元素的hash值,如果是读引用则会多一个accessTime字段,以强引用的构造方法为例:
static class StrongEntry<K, V> extends AbstractReferenceEntry<K, V> { final K key; StrongEntry(K key, int hash, @Nullable ReferenceEntry<K, V> next) { this.key = key; this.hash = hash; this.next = next; } @Override public K getKey() { return this.key; } // The code below is exactly the same for each entry type. final int hash; final @Nullable ReferenceEntry<K, V> next; volatile ValueReference<K, V> valueReference = unset();
强读引用的代码如下:
StrongAccessEntry(K key, int hash, @Nullable ReferenceEntry<K, V> next) { super(key, hash, next); // 继承了StrongEntry,并多了accessTime } // The code below is exactly the same for each access entry type. volatile long accessTime = Long.MAX_VALUE;
2.6 LocalCache示例
上面对LoacheCache所涉及的主要的类都做了介绍,下面画一张示例图给个直观感受,该例子中的Cache中包含的segment数组大小为4(默认值是4),第二个segment的table数组大小为4,其中第二个table中的链表中有3个元素(简便起见,其他segment和table中的元素就不画了),

3. 主要方法
上面介绍了几个主要的类,下面从使用者的角度来把这几个类串联起来,主要包含了:创建Cache、添加对象、访问对象和删除对象。
3.1 创建Cache
创建一个Cache的实现代码如下:
LoadingCache<Key, Graph> graphs = CacheBuilder.newBuilder() .maximumSize(10000) // 最大元素个数 .expireAfterWrite(Duration.ofMinutes(10)) // 元素写入10分钟后期 .removalListener(MY_LISTENER) // 自定义的一个监听器 .build( new CacheLoader<Key, Graph>() { // 元素加载器,当查询元素不存在时,会自动调用该方法进行加载,然后再返回元素 public Graph load(Key key) throws AnyException { return createExpensiveGraph(key); } }); }
3.2 添加元素
添加元素访问的是LocalCache的put方法(注意这个方法是没有锁的),代码如下:
@Override public V put(K key, V value) { checkNotNull(key); checkNotNull(value); int hash = hash(key); // 首先计算key的hash值,并根据hash选定segment,再调用segment的put方法 return segmentFor(hash).put(key, hash, value, false); } /** * Returns the segment that should be used for a key with the given hash. * * @param hash the hash code for the key * @return the segment */ Segment<K, V> segmentFor(int hash) { // return segments[(hash >>> segmentShift) & segmentMask]; }
再看下segment中的put方法(注意这个方法是有锁的):
@Nullable V put(K key, int hash, V value, boolean onlyIfAbsent) { lock(); // 一开始先加锁 try { long now = map.ticker.read(); // 当前时间,单位纳秒 preWriteCleanup(now); // 删除过期元素 int newCount = this.count + 1; if (newCount > this.threshold) { // 必要时先扩容 expand(); newCount = this.count + 1; } // 根据hash再定位在table中的位置 AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table; int index = hash & (table.length() - 1); // 取得table中对应位置的链表的首个元素 ReferenceEntry<K, V> first = table.get(index); // 遍历该链表,如果已在链表中则更新值. for (ReferenceEntry<K, V> e = first; e != null; e = e.getNext()) { K entryKey = e.getKey(); if (e.getHash() == hash && entryKey != null && map.keyEquivalence.equivalent(key, entryKey)) { // We found an existing entry. ValueReference<K, V> valueReference = e.getValueReference(); V entryValue = valueReference.get(); if (entryValue == null) { ++modCount; if (valueReference.isActive()) { enqueueNotification( key, hash, entryValue, valueReference.getWeight(), RemovalCause.COLLECTED); setValue(e, key, value, now); newCount = this.count; // count remains unchanged } else { setValue(e, key, value, now); newCount = this.count + 1; } this.count = newCount; // write-volatile evictEntries(e); return null; } else if (onlyIfAbsent) { // Mimic // "if (!map.containsKey(key)) ... // else return map.get(key); recordLockedRead(e, now); return entryValue; } else { // clobber existing entry, count remains unchanged ++modCount; enqueueNotification( key, hash, entryValue, valueReference.getWeight(), RemovalCause.REPLACED); setValue(e, key, value, now); evictEntries(e); return entryValue; } } } // 在链表中未找到,则创建一个新的元素,并添加在链表的头部,即2.6章节示例中的table[1]和entry1之间. ++modCount;// 链表更新操作次数加1 ReferenceEntry<K, V> newEntry = newEntry(key, hash, first); setValue(newEntry, key, value, now); table.set(index, newEntry);// 添加到链表头部 newCount = this.count + 1; this.count = newCount; // segment内的元素个数加1 evictEntries(newEntry); return null; } finally { unlock(); postWriteCleanup(); // 前面删除元素时,会把删除通知加入到队列中,在这里遍历删除通知队列并发出通知 } }
添加方法的代码如上所示,重点有两个地方:
1. LocalCache的put方法中是不加锁的,而Segment中的put方法是加锁的,因此在访问量很大的时候,可以通过提高concurrencyLevel的值来提高segment数组大小,减少锁冲突。
2. 在执行put方法时,会“顺便”执行清理操作,删除过期的元素,因为Guava Cache没有后台线程,因此删除操作是在每次的put操作和一定次数的read操作时执行的,且清理的是当前segment的过期元素,这也告诉我们过期的元素并不是立即被删除的,即内存不是立即释放的,会随着我们的读写操作来释放的,当然如果Guava Cache本身访问量不大,导致累积了大量过期元素后,再来访问可能会有较大的访问耗时。
3.3 访问元素
访问元素访问的是LocalCache的get方法(注意这个方法是没有锁的),代码如下:
public @Nullable V getIfPresent(Object key) {
// 和put一样,先对key做hash,再定位segment,然后调用get访问 int hash = hash(checkNotNull(key)); V value = segmentFor(hash).get(key, hash); if (value == null) { globalStatsCounter.recordMisses(1); } else { globalStatsCounter.recordHits(1); } return value; }
继续看segment的get方法(注意这个方法是没有锁的):
@Nullable V get(Object key, int hash) { try { if (count != 0) { // read-volatile long now = map.ticker.read(); // 查询存活的元素 ReferenceEntry<K, V> e = getLiveEntry(key, hash, now); if (e == null) { return null; } V value = e.getValueReference().get(); if (value != null) { recordRead(e, now); // 检查是否需要刷新元素 return scheduleRefresh(e, e.getKey(), hash, value, now, map.defaultLoader); } // 删除非强引用的队列,包含key队列和value队列 tryDrainReferenceQueues(); } return null; } finally { postReadCleanup();// 检查是否有过期元素待删除 } }
下面再看下getLiveEntry和postReadCleanup方法:
@Nullable ReferenceEntry<K, V> getLiveEntry(Object key, int hash, long now) { ReferenceEntry<K, V> e = getEntry(key, hash); if (e == null) { return null; } else if (map.isExpired(e, now)) { // 检查元素是否过期 tryExpireEntries(now); return null; } return e; } @Nullable ReferenceEntry<K, V> getEntry(Object key, int hash) { // 根据hash定位table中位置的链表,并进行遍历,检查hash是否相等 for (ReferenceEntry<K, V> e = getFirst(hash); e != null; e = e.getNext()) { if (e.getHash() != hash) { continue; } K entryKey = e.getKey(); if (entryKey == null) { // 被垃圾回收期回收,清理引用队列 tryDrainReferenceQueues(); continue; } if (map.keyEquivalence.equivalent(key, entryKey)) { return e; } } return null; }
/** Returns first entry of bin for given hash. */
ReferenceEntry<K, V> getFirst(int hash) {
// read this volatile field only once
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
return table.get(hash & (table.length() - 1));
}
void postReadCleanup() { // DRAIN_THRESHOLD=63,即每读64次会执行一次清理操作 if ((readCount.incrementAndGet() & DRAIN_THRESHOLD) == 0) { cleanUp(); } }
读方法相对要简单一些,重点有两个地方:
1. 查找到元素后检查是否过期,过期则删除,否则返回。
2. put方法每次调用都执行清理方法,get方法每调用64次get方法,才会执行一次清理。
注意,前面示例中的CacheBuilder创建LocalCache时,添加了元素加载器,当get方法中发现元素不存在时
3.4 删除元素
删掉元素是invalidate()接口,该接口最终调用了segment的remove方法实现,如下:
V remove(Object key, int hash) { lock(); // 和put有些类似,先加锁,再搜索,然后从链表删除 try { long now = map.ticker.read(); preWriteCleanup(now); int newCount = this.count - 1; AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table; int index = hash & (table.length() - 1); ReferenceEntry<K, V> first = table.get(index); for (ReferenceEntry<K, V> e = first; e != null; e = e.getNext()) { K entryKey = e.getKey(); if (e.getHash() == hash && entryKey != null && map.keyEquivalence.equivalent(key, entryKey)) { ValueReference<K, V> valueReference = e.getValueReference(); V entryValue = valueReference.get(); RemovalCause cause; if (entryValue != null) { cause = RemovalCause.EXPLICIT; } else if (valueReference.isActive()) { cause = RemovalCause.COLLECTED; } else { // currently loading return null; } ++modCount; // 删除方法有些特别,看下面分析 ReferenceEntry<K, V> newFirst = removeValueFromChain(first, e, entryKey, hash, entryValue, valueReference, cause); newCount = this.count - 1; table.set(index, newFirst); this.count = newCount; // write-volatile return entryValue; } } return null; } finally { unlock(); postWriteCleanup(); } } // removeValueFromChain调用了removeEntryFromChain @GuardedBy("this") @Nullable ReferenceEntry<K, V> removeEntryFromChain( ReferenceEntry<K, V> first, ReferenceEntry<K, V> entry) { int newCount = count; ReferenceEntry<K, V> newFirst = entry.getNext(); // 删除元素时,没有直接从链表上面摘除,而是遍历first和entry之间的元素,并拷贝新建新的元素构建链表 for (ReferenceEntry<K, V> e = first; e != entry; e = e.getNext()) { ReferenceEntry<K, V> next = copyEntry(e, newFirst); if (next != null) { newFirst = next; } else { removeCollectedEntry(e); newCount--; } } this.count = newCount; return newFirst; }
注意删除的时候,并没有直接从链表摘除,而是做了一次遍历新建了一个链表,举个例子:
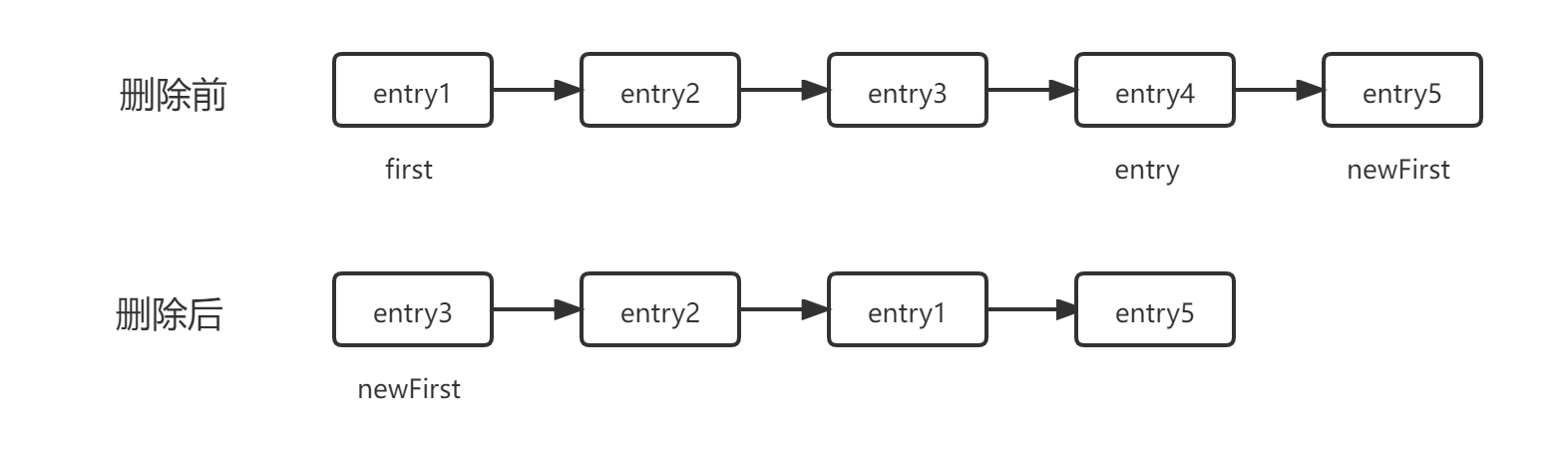
为什么要做一次遍历呢?先看一下StrongEntry的定义:
static class StrongEntry<K, V> extends AbstractReferenceEntry<K, V> { final K key; final int hash; final @Nullable ReferenceEntry<K, V> next; volatile ValueReference<K, V> valueReference = unset(); }
key,hash和next都是final的,通过这种新建链表的方式,可以保证当前的并发读线程是能读到数据的(读方法无锁),即使是过期的,这其实就是CopyOnWrite的思想。
4. 小结
从上面分析可以看出,guava cache是一款非常优秀的本地缓存组件,为了得到更好的效率,减少写操作锁冲突(读操作无锁),可以将concurrencyLevel设置为当前CPU核数的2两倍。
初始化代码如下:
Cache<String, Integer> lcache = CacheBuilder.newBuilder() .maximumSize(100) .concurrencyLevel(Runtime.getRuntime().availableProcessors()*2) // 当前CPU核数*2
.expireAfterWrite(30, TimeUnit.SECONDS) .build();
之后就可以通过put和getIfPresent来进行元素访问了,例如:
// 赋值
for(int i=0; i<10000; i++) { lcache.put(String.valueOf(i), i); } // 查询 Integer value = lcache.getIfPresent("10");