前面了解过机器翻译的一些内容,对于文本的信息挖掘应该有了一定的了解,今天再来扫盲一下情感分析吧~
更多内容参考:
引言
情感分析在很多点上领域有很多的应用场景:
- 比如,酒店网站需要提取用户对酒店的评价,然后策略性的进行显示,比如把负面的评价排的稍微往后面一点,总不能上来满屏都是脏乱差吧!
- 比如,一些电商类的网站根据情感分析提取正负面的评价关键词,形成商品的标签。基于这些标签,用户可以快速知道大众对这个商品的看法
- 比如,一些新闻类的网站,根据新闻的评论可以知道这个新闻的热点情况,是积极导向,还是消极导向,从而进行舆论新闻的有效控制。
首先我们先来看看大厂们的效果:
携程旅游
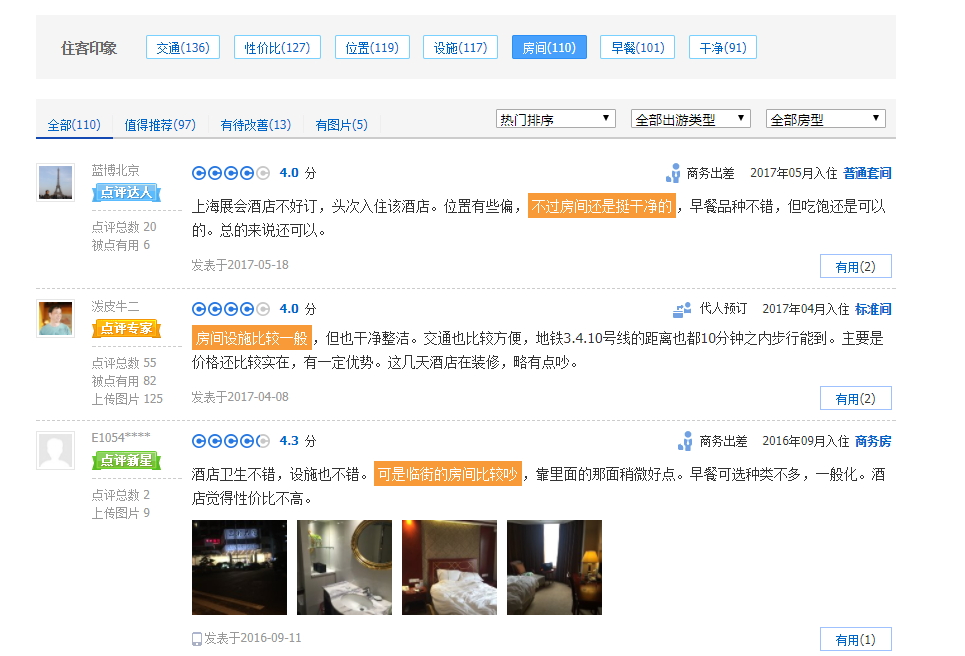
这里把各种评价进行了归类,然后通过类别标签可以索引到目标评论。
京东

虽然有提取一些情感主题,但是不支持跳转
天猫
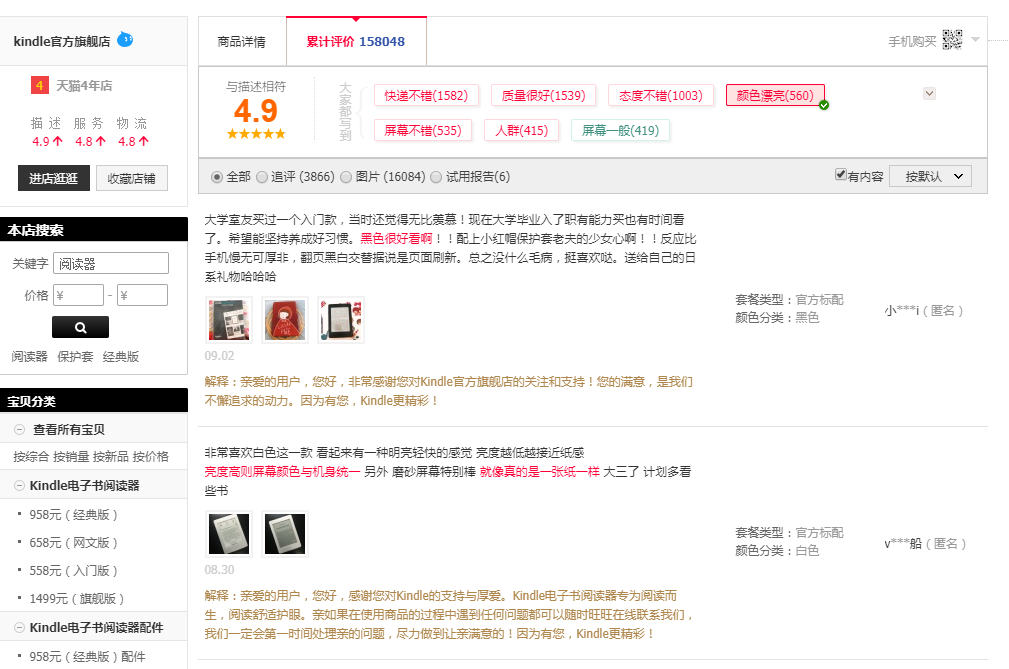
天猫做的就不错了,主题提取出来了,还支持跳转。
有人对情感分析并不看好,首先是因为机器做情感分析毕竟没有一些主观的因素,难以还原用户当时的心情;其次是再好的情感分析也不如打星星来的精准,直接废话不多说,5颗星好评,1颗星差评...简单粗暴。
不过我还是比较看好这个方向的,因为星星毕竟只是一个简单粗暴的情感分析,直接划分粒度太粗。
所以回归正题,还是继续说说情感分析的一些实现方法吧!基本上情感分析有两种套路,一种是基于情感词的;另一种是基于机器学习的,我们下面就仔细的来看看每一种的实现方法。
基于情感词典的情感分析
这种分析方法简单粗暴,并不需要有太多复杂的知识,但是要求有尽量庞大完备的词库,而且这种词库必须是某一个领域背景下的。至于为什么不能通用稍后再说....
首先需要这样几个词典:
停顿词词典
的 和 得 之间 ....
正面评价词
价格便宜 干净 美丽 物美价廉...
负面评价词
埋汰 脏 差 坏 ...
程度词
还行 0.8
非常好 3.0
凑合 0.5
一般 0.5
特别 2.0
否定词
不 难道 非 ...
这些词典基本每个领域都不一样,比如声音大这个词,在音响的领域里面表示正面评价;但是在空调的领域里面就是负面评价了。因此每个领域最好有自己专业的词库,这个词库可以基于爬虫也可以基于人工搜集整理。网上有很多可以下载到的词库,不过都是比较通用的。
然后就可以按照下面的步骤计算情感取向了:
- 获取全部的用户评价内容
- 先进行分词
- 根据每个词计算总体的情感分值,公式如:
-1^(否定词的个数)*程度词的分值*评价词的分值 - 然后根据正负判断情感走向。
比如,难道非得让我说差么?中,难道和非都算否定词,这样分值就是(-1)^2*1*-1 = -1,结论是负面评价
再比如,难道这样不好吗?中,难道和不都是否定词,分值为(-1)^2*1*1=1,结论是正面评价
虽然说有上面这些规则,在一些特定语境里面情感分析还是会出现误差。而且词语的位置也是一个很重要的因素,在词典这种机制里面,是忽略掉位置的。下面我们再看看基于机器学习的分析方法吧!
基于机器学习的情感分析方法
定义问题
在情感分析中应用机器学习,首先第一步是定义问题,即先要判断情感分析是一个回归问题还是分类问题,还是聚类问题。由于用户基本上就是正面评价和负面评价,因此我们可以把它定义成二分类的问题。问题定义完,就可以考虑使用什么分类器的方法,比如逻辑回归、支持向量机、神经网络...都可以尝试。
准备数据
有机器学习背景的同学都应该知道,分类的问题属于有监督的学习问题,因此是需要提前准备一些标注数据的(标注的意思就是我们想要知道的结果)。比如现在有这样一波数:
评价语1 正面评价
评价语2 负面评价
评价语3 正面评价
评价语4 正面评价
其中评价属于最后我们想要的结果,即Label;评价语则是原始的数据,需要给变成可以计算的数值(方法有几种:词袋、TF-IDF、word2vec这个以后在详细说明,可以简单的理解为就是把一些评价文字,变成了 01010101的数值作为特征)
然后我们就形成了这样的数据:
(0 1 1 0 1),1
(1 1 0 0 1),0
(0 1 0 0 0),1
(0 1 1 1 0),1
接下来就需要准备训练集和测试集,训练集用来训练模型;测试集用来测试模型是否正确。训练集在选取时,需要注意正负两个label的比例。试想一下,如果你的训练集里面90%都是负面评价,那么这个模型直接就写死只返回负面评价的结果,那么如果测试集也是同样的数据分布比例,那么正确率也会高达90%。这样显然是不合理的,因此要保证样本中正负评价数据的均衡。关于评测,手段有很多比如RMSE,MSE等等,有兴趣可以多了解下。
训练模型
然后就是利用各种算法训练模型,训练之后对比一下,选一个正确率最高的即可。最后把模型保存下面,之后可以直接使用。
应用
这里就直接应用模型,传入响应评价对应的特征参数即可。
总结
如果想要快速实现一个情感分析系统,最快的方式就是找到对应的情感词库,直接基于词典来做。如果考虑到未来的优化...可以再尝试使用机器学习的方式。
参考
- 基于情感词典的代码示例:http://www.aidnoob.com/ai/python/qinggan1/
- Python做文本情感分析之情感极性分析:http://www.jianshu.com/p/4cfcf1610a73