一、java对象的内存布局
一个Java对象在内存中包括3个部分:对象头、实例数据和对齐填充

二、验证hashCode的储存方式
使用jol工具导入对应包、
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>RELEASE</version>
</dependency>
public class Worker {
private Integer id;
private String username;
private String password;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
@Override
public String toString() {
return super.toString ();
}
public static void printf(Worker p) {
// 查看对象的整体结构信息
// JOL工具类
System.out.println( ClassLayout.parseInstance(p).toPrintable());
}
}
public class Test {
public static void main(String[] args) {
Worker work = new Worker();
//输出对象信息
System.out.println(work.hashCode());
System.out.println(work);
//输出信息
Worker.printf(work);
}
}
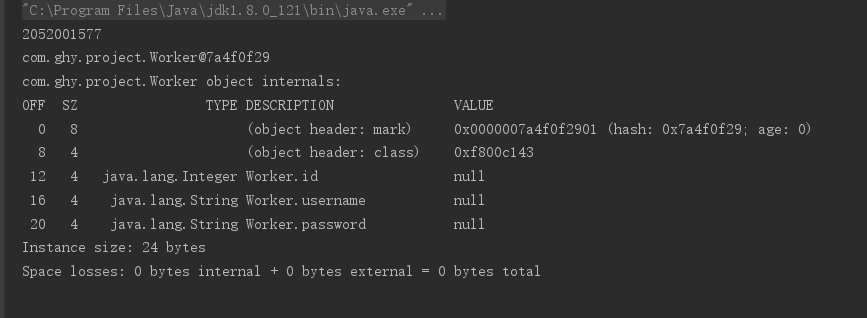
2052001577这个数字是我们的HashCode值,转换成16进制可得7a 4f 0f 29,经过对比。
由此可得,我们的哈希码使用的大端储存。
例如:
十进制数9877,如果用小端存储表示则为:
高地址 <- - - - - - - - 低地址
10010101`[高序字节]` 00100110`[低序字节]`
用大端存储表示则为:
高地址 <- - - - - - - - 低地址
00100110`[低序字节]` 10010101`[高序字节]`
小端存储:便于数据之间的类型转换,例如:long类型转换为int类型时,高地址部分的数据可以直接截掉。
大端存储:便于数据类型的符号判断,因为最低地址位数据即为符号位,可以直接判断数据的正负号。
2.1、Class Pointer
引用定位到对象的方式有两种,一种叫句柄池访问,一种叫直接访问
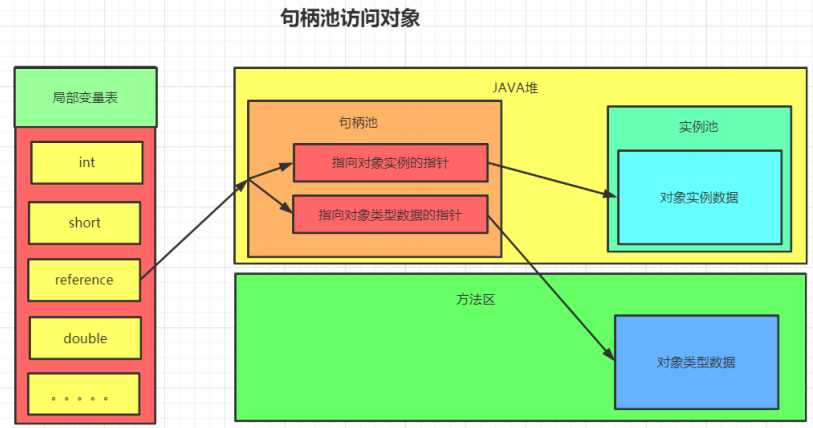
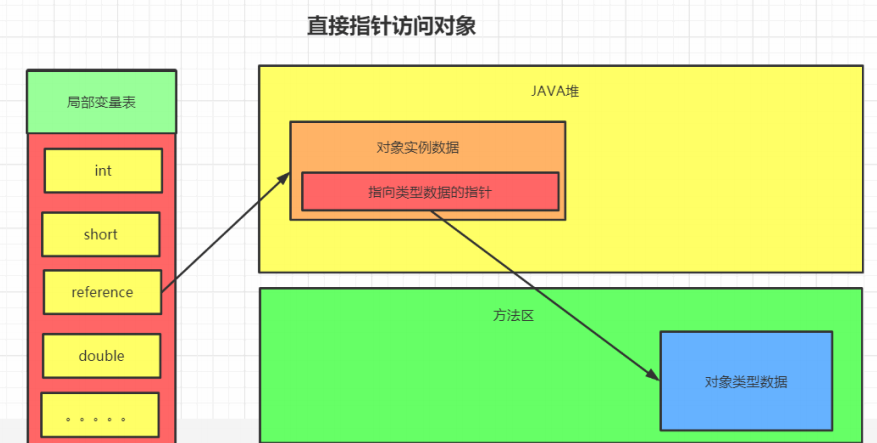
区别:
句柄池:
使用句柄访问对象,会在堆中开辟一块内存作为句柄池,句柄中储存了对象实例数据(属性值结构体)的内存地址,访问类型数据的内存地址(类信息,方法类型信息),对象实例数据一般也在heap中开辟,类型数据一般储存在方法区中。
优点:reference存储的是稳定的句柄地址,在对象被移动(垃圾收集时移动对象是非常普遍的行为)时只会改变句柄中的实例数据指针,而reference本身不需要改变。
缺点:增加了一次指针定位的时间开销。
直接访问:
直接指针访问方式指reference中直接储存对象在heap中的内存地址,但对应的类型数据访问地址需要在实例中存储。
优点:节省了一次指针定位的开销。
缺点:在对象被移动时(如进行GC后的内存重新排列),reference本身需要被修改。
指针压缩:
在32位系统中,类型指针为4字节32位,在64位系统中类型指针为8字节64位,但是JVM会默认的进行指针压缩,所以我们上图输出结果中类型指针也是4字节32位。如果我们关闭指针压缩的话,就可以看到64位的类型指针了,所以我们通常在部署服务时,JVM内存不要超过32G,因为超过32G就无法开启指针压缩了
关闭指针压缩 : -XX:+UseCompressedOops
对齐填充
没有对齐填充就可能会存在数据跨内存地址区域存储的情况,在没有对齐填充的情况下,内存地址存放情况如下:

因为处理器只能0x00-0x07,0x08-0x0F这样读取数据,所以当我们想获取这个long型的数据时,处理器必须要读两次内存,第一次(0x00-0x07),第二次(0x08-0x0F),然后将两次的结果才能获得真正的数值。
那么在有对齐填充的情况下,内存地址存放情况是这样的:

现在处理器只需要直接一次读取(0x08-0x0F)的内存地址就可以获得我们想要的数据了。对齐填充存在的意义就是为了提高CPU访问数据的效率,这是一种以空间换时间的做法;正如我们所见,虽然访问效率提高了(减少了内存访问次数),但是在0x07处产生了1bit的空间浪费。