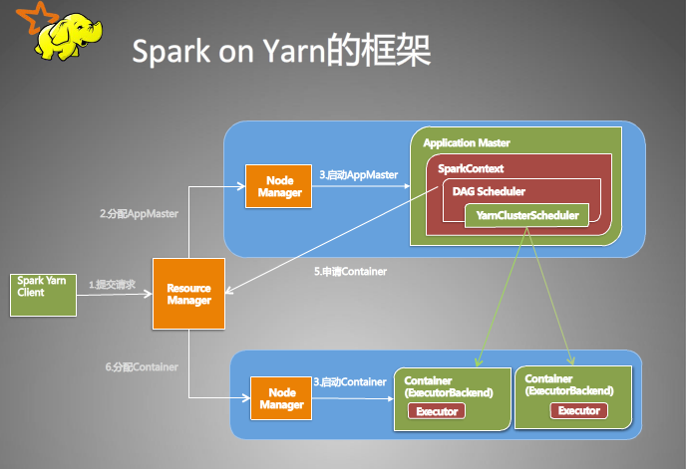
一、客户端进行操作
1、根据yarnConf来初始化yarnClient,并启动yarnClient
2、创建客户端Application,并获取Application的ID,进一步判断集群中的资源是否满足executor和ApplicationMaster申请的资源,如果不满足则抛出IllegalArgumentException;
3、设置资源、环境变量:其中包括了设置Application的Staging目录、准备本地资源(jar文件、log4j.properties)、设置Application其中的环境变量、创建Container启动的Context等;
4、设置Application提交的Context,包括设置应用的名字、队列、AM的申请的Container、标记该作业的类型为Spark;
5、申请Memory,并最终通过yarnClient.submitApplication向ResourceManager提交该Application。
当作业提交到YARN上之后,客户端就没事了,甚至在终端关掉那个进程也没事,因为整个作业运行在YARN集群上进行,运行的结果将会保存到HDFS或者日志中。
二、提交到YARN集群,YARN操作
1、运行ApplicationMaster的run方法;
2、设置好相关的环境变量。
3、创建amClient,并启动;
4、在Spark UI启动之前设置Spark UI的AmIpFilter;
5、在startUserClass函数专门启动了一个线程(名称为Driver的线程)来启动用户提交的Application,也就是启动了Driver。在Driver中将会初始化SparkContext;
6、等待SparkContext初始化完成,最多等待spark.yarn.applicationMaster.waitTries次数(默认为10),如果等待了的次数超过了配置的,程序将会退出;否则用SparkContext初始化yarnAllocator;
7、当SparkContext、Driver初始化完成的时候,通过amClient向ResourceManager注册ApplicationMaster
8、分配并启动Executeors。在启动Executeors之前,先要通过yarnAllocator获取到numExecutors个Container,然后在Container中启动Executeors。那么这个Application将失败,将Application Status标明为FAILED,并将关闭SparkContext。其实,启动Executeors是通过ExecutorRunnable实现的,而ExecutorRunnable内部是启动CoarseGrainedExecutorBackend的。
9、最后,Task将在CoarseGrainedExecutorBackend里面运行,然后运行状况会通过Akka通知CoarseGrainedScheduler,直到作业运行完成。
三、Spark on Yarn配置参数
1. spark.yarn.applicationMaster.waitTries 5
用于applicationMaster等待Spark master的次数以及SparkContext初始化尝试的次数 (一般不用设置)
2.spark.yarn.am.waitTime 100s
3.spark.yarn.submit.file.replication 3
应用程序上载到HDFS的复制份数
4.spark.preserve.staging.files false
设置为true,在job结束后,将stage相关的文件保留而不是删除。 (一般无需保留,设置成false)
5.spark.yarn.scheduler.heartbeat.interal-ms 5000
Spark application master给YARN ResourceManager 发送心跳的时间间隔(ms)
6.spark.yarn.executor.memoryOverhead 1000
此为vm的开销(根据实际情况调整)
7.spark.shuffle.consolidateFiles true
仅适用于HashShuffleMananger的实现,同样是为了解决生成过多文件的问题,采用的方式是在不同批次运行的Map任务之间重用Shuffle输出文件,也就是说合并的是不同批次的Map任务的输出数据,但是每个Map任务所需要的文件还是取决于Reduce分区的数量,因此,它并不减少同时打开的输出文件的数量,因此对内存使用量的减少并没有帮助。只是HashShuffleManager里的一个折中的解决方案。
8.spark.serializer org.apache.spark.serializer.KryoSerializer
暂时只支持Java serializer和KryoSerializer序列化方式
9.spark.kryoserializer.buffer.max 128m
允许的最大大小的序列化值。
10.spark.storage.memoryFraction 0.3
用来调整cache所占用的内存大小。默认为0.6。如果频繁发生Full GC,可以考虑降低这个比值,这样RDD Cache可用的内存空间减少(剩下的部分Cache数据就需要通过Disk Store写到磁盘上了),会带来一定的性能损失,但是腾出更多的内存空间用于执行任务,减少Full GC发生的次数,反而可能改善程序运行的整体性能。
11.spark.sql.shuffle.partitions 800
一个partition对应着一个task,如果数据量过大,可以调整次参数来减少每个task所需消耗的内存.
12.spark.sql.autoBroadcastJoinThreshold -1
当处理join查询时广播到每个worker的表的最大字节数,当设置为-1广播功能将失效。
13.spark.speculation false
如果设置成true,倘若有一个或多个task执行相当缓慢,就会被重启执行。(事实证明,这种做法会造成hdfs中临时文件的丢失,报找不到文件的错)
14.spark.shuffle.manager tungsten-sort
tungsten-sort是一种类似于sort的shuffle方式,shuffle data还有其他两种方式 sort、hash. (不过官网说 tungsten-sort 应用于spark 1.5版本以上)
15.spark.sql.codegen true
Spark SQL在每次执行次,先把SQL查询编译JAVA字节码。针对执行时间长的SQL查询或频繁执行的SQL查询,此配置能加快查询速度,因为它产生特殊的字节码去执行。但是针对很短的查询,可能会增加开销,因为它必须先编译每一个查询
16.spark.shuffle.spill false
如果设置成true,将会把spill的数据存入磁盘
17.spark.shuffle.consolidateFiles true
我们都知道shuffle默认情况下的文件数据为map tasks * reduce tasks,通过设置其为true,可以使spark合并shuffle的中间文件为reduce的tasks数目。
18.代码中 如果filter过滤后 会有很多空的任务或小文件产生,这时我们使用coalesce或repartition去减少RDD中partition数量。