代码练习
图像处理基本练习
下载并显示图像
(1) io.imread()、plt.imshow(),返回/读取数据维度的是(m,n,c),最后一维是通道数,(c,m,n)形式的数据通过np.transpose(img,(1,2,0))转换。
(2) plt.subplot(121) 前两个数字表示将画布划分为1行2列,第三个数字1表示在第1个位置绘图(位置顺序:从左到右,从上到下)。
读取并改变图像像素值
(1) data.camera(),返回一张相机的灰度图片(512 x 512)。
(2) mask = camera < 80, mask是一个bool数组,维度(512 x 512),与图片像素对应。图片中像素值大于80的位置对应的mask数组的值为False,其余为True。
(3) data.chelsea(),返回一张彩色图片:切尔西的猫;reddish = cat[:, :, 0] > 160:图片R(RGB)通道的像素值大于160的位置对应的reddish数组的值为True,其余为False,下一句代码将相应位置变为红色。
(4) opencv中图像不是RGB格式,是BGR格式。BGR_cat = cat[:, :, ::-1] : 将最后一维数据顺序反转,cat.shape:(300,451,3),最后一维的形式是[r,g,b],倒序后即[b,g,r]。
转换图像数据类型
skimage.img_as_float(img)--- [64-float]
skimage.img_as_ubyte(i1. mg)--- [8-unit]
skimage.img_as_uint(img)--- [16-unit]
skimage.img_as_int(img)--- [16-int]
显示图像直方图
(1) img.ravel() 数据打平为1维,与np.flatten()功能一致,但前者返回的是视图,类似与c++的引用,改变视图的值会改变原始数据,后者返回一个拷贝,不会影响原始数据。
(2) plt.hist(x,bins=None,range=None, density=None, bottom=None, histtype='bar', align='mid', log=False, color=None, label=None, stacked=False, normed=None)。
x:数据集;
bins:统计的区间分布;range:tuple,显示的区间;
density:bool,默认为false,显示统计频数;
histtype: 可选{'bar', 'barstacked', 'step', 'stepfilled'}之一,默认为bar,step使用的是梯状,stepfilled则会对梯状内部进行填充,效果与bar类似;
图像分割
skimage.color.rgb2gray(img):RGB图像转灰度图像。
Canny算子用于边缘检测
img_edges = canny(img):边缘检测
img_filled = ndi.binary_fill_holes(img_edges):填充二进制图像矩阵中的孔洞
改变图像的对比度
(1) p2, p98 = np.percentile(img, (2, 98)):取img数组的百分位数,2%和98%。
例如:x=[1,2,3,4,5,6,7,8,9],np.percentile(x,60)结果是5.8。1到9有8个间隔,每个间隔表示12.5%。60/12.5=4.8需要4.8个间隔.4个间隔到达数字5,5和6间隔为1,1 x 0.8 = 0.8,最终结果为5.8.
(2) skimage.exposure.rescale_intensity(): 对比度拉伸。在该处的作用猜测是将img数组中大于p98的数变为1.0,小于p2的数变为0.0,在p2和p98之间的数除以p98作为最后结果。
(3) exposure.equalize_hist(img):直方图均衡化。
解释: 如果一副图像的像素占有很多的灰度级而且分布均匀,那么这样的图像往往有高对比度和多变的灰度色调。直方图均衡化就是一种能仅靠输入图像直方图信息自动达到这种效果(得到高对比度的图像)的变换函数。它的基本思想是对图像中像素个数多的灰度级进行展宽,而对图像中像素个数少的灰度进行压缩,从而扩展取值的动态范围,提高了对比度和灰度色调的变化,使图像更加清晰。那么这个过程就被称为直方图均衡化。直方图均衡后的图像的累计分布函数大致是线性的.
(4) exposure.equalize_adapthist(img, clip_limit=0.03):有限对比度自适应直方图均衡(局部直方图均衡化)。clip_limit越大,对比度越大。
2.2 pytorch基础练习
(1) tensor.numel(): 返回tensor中元素数目。
(2)

螺旋数据分类
构建线性模型
(1) 交叉熵损失函数
对于二分类,记函数为:
其中:
-(y_{i})表示样本i的类别,正类为1,负类为0。
-(p_{i})表示样本i预测为正类的概率,即网络的输出,该情况下网络应只有一个输出单元。
不难看出对正类的输出(最大为1)越大或负类的输出(最小为0)越小时,损失越小。
对于多分类,记函数为:
-(p_{i})表示样本i的真实概率分布。
-(q_{i})表示样本i预测概率分布。
例如:一个三分类问题中真实分布为(one-hot编码后):([0,1,0]),预测分布为(三个输出单元的输出,假设已softmax):([q1,q2,q3])。H(p,q)=-(0logq1+1logq1+0logq3)=-logq2,即最终结果只和你对真实类别的预测概率有关,你对真实类别预测的概率q2越大(最大为1),损失就越小。
(2) 随机梯度下降(SGD)
深度学习框架中的SGD均是指mini-batch GD,并不是定义上的SGD(只使用一个样本更新梯度),当需要真正意义上的SGD时,batch_size设置为1即可。
(3) 权重衰减(L2正则化)
weight_decay,L2正则化就是在损失函数后面加上一个正则化项:
权重衰减到更小的值,在一定程度上减少模型过拟合的问题。
回归分析
(1) torch.squeeze():压缩数据的维度,torch.squeeze(a),去掉a所有维数为1的维度;torch.squeeze(a,n),去掉a指定维度n(n的维数必须是1),否则无效(不会报错)。
(2) torch.unsqueeze():扩充数据的维度,torch.unsqueeze(a,n),在指定位置n加上一个维数为1的维度。
(3) torch.nn.MSELoss():均方误差损失函数:
其中N是样本个数,(y_{i})是真实值,(hat{y_{i}})是预测值。
(4) SGD在此处效果差的原因:SGD只考虑当前batch的数据,用它求梯度、更新参数。这通常会受数据噪声的影响,只靠当前batch的数据虽然大体方向是可以朝着最优或局部最优解前进,但是由于每个batch之间的噪声影响,每次求解的梯度方向偏差可能会有些大,可能会走'之'字形,导致SGD收敛速度较慢。(个人猜测)
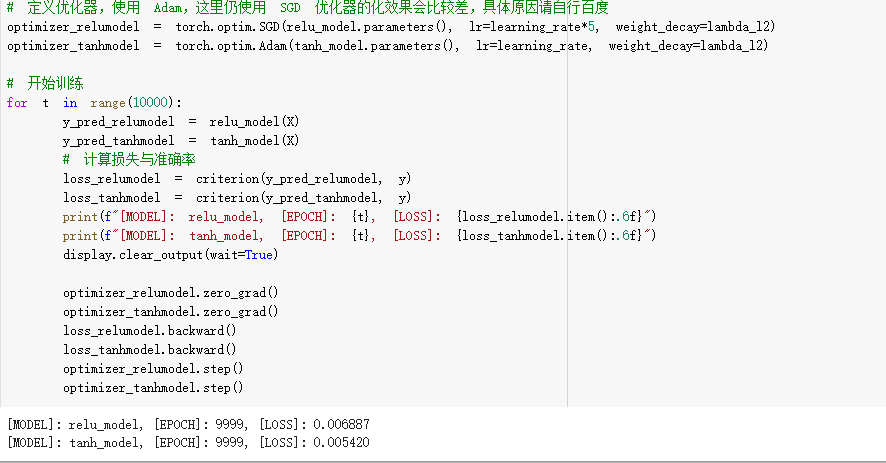
(5) 使用 ReLU 激活函数,收敛较快;使用 Tanh 激活函数,一开始收敛较慢,但随后也快速收敛:应该和relu函数和tanh函数的导数有关,relu函数的导数是0或1,tanh的导数信息是0到1,在进行反向传播时,relu函数参数更新更快,收敛的也就快。(个人猜测)
(6) ReLU 激活函数的网络得到的结果,和使用 Tanh 激活函数的网络得到的结果不同的原因:
从图片中可以观察的tanh激活函数的模型得到的结果很平滑,relu激活函数的模型有些硬直。暂时没想明白结果和分段函数或连续函数有什么关系。我输出了两个模型的权重进行了对比,将使用relu函数的模型和使用tanh的模型的第二个全连接层的参数截图:


进阶练习
-toTxt.py 将图片路径和类别存储到txt文件
# -*- coding: utf-8 -*-
"""
Created on Tue Jul 21 10:42:28 2020
@author: xzj
"""
import os
'''
为数据集生成对应的txt文件
train和val 生成txt文件每行的格式如:G:pytorchcat_dog raincat_0.jpg 0,保存地址和类别
test数据集命名有规律,直接循环生成路径
'''
train_path = r'G:pytorchdogscats rain rain.txt'
train_dir = r'G:pytorchdogscats rain'
test_path = r'G:pytorchcat_dog est est.txt'
test_dir = r'G:pytorchcat_dog est'
val_path = r'G:pytorchdogscatsvalval.txt'
val_dir = r'G:pytorchdogscatsval'
trans_label = {'cat':'0','dog':'1'}
def gen_txt(txt_path, img_dir):
f = open(txt_path, 'w')
for root, _, files in os.walk(img_dir, topdown=True):
for file in files:
if not file.endswith('jpg'):
continue
label = file.split('.')[0]
f_path = os.path.join(root, file)
line = f_path + ' ' + trans_label[label] + '
'
f.write(line)
# for i in range(2000):
# line = 'G:\pytorch\cat_dog\test\' + str(i) +'.jpg'+'
'
# f.write(line)
f.close()
gen_txt(train_path, train_dir)
gen_txt(val_path, val_dir)
# gen_txt(test_path,test_dir)
-MyDataSet.py 建立datasets,读取数据
# -*- coding: utf-8 -*-
"""
Created on Tue Jul 21 10:43:57 2020
@author: xzj
"""
"""
建立自己的datasets,继承自Dataset类,实现getitem方法
getitem函数接收一个index,然后返回图片数据、标签(不一定俩都返回,第二个类就只返回了图片数据,根据需要写)
"""
from torch.utils.data import Dataset
from PIL import Image
class MyDataset(Dataset):
def __init__(self,txt_path,transform = None):
#根据txt_path读取数据集的txt文件,获得图片路径、类别,将图片路径和类别存入一个list
#可以选择添加transform函数对图片进行变换
f = open(txt_path,'r')
imgs = []
for line in f:
line = line.rstrip()
part = line.split()
imgs.append((part[0],int(part[1])))
self.imgs = imgs
self.transform = transform
def __getitem__(self,index):
#通过Image.open读取list[index]代表的图片
f_path,label = self.imgs[index]
img = Image.open(f_path).convert("RGB")
if self.transform is not None:
img = self.transform(img)
return img,label
def __len__(self):
return len(self.imgs)
#这里因为测试数据集的txt文件没有类别,处理流程不大一样,没有在上一个类里改,直接复制下来处理一下
class TestDataset(Dataset):
def __init__(self,txt_path,transform=None):
f = open(txt_path,'r')
imgs = []
for line in f:
line = line.rstrip()
imgs.append(line)
self.imgs = imgs
self.transform = transform
def __getitem__(self,index):
f_path = self.imgs[index]
img = Image.open(f_path).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img
def __len__(self):
return len(self.imgs)
-main.py VGG19模型预训练
# coding:utf-8
import torch
from torch.utils.data import DataLoader
from torchvision import transforms,models
import torch.nn as nn
import torch.optim as optim
from MyDataSet import MyDataset,TestDataset
import time
import copy
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
batch_size = 64
#从大量图片统计出来的均值和标准差,通常使用这些数据进行标准化
normMean = [0.4948052, 0.48568845, 0.44682974]
normStd = [0.24580306, 0.24236229, 0.2603115]
norm_transform = transforms.Normalize(normMean,normStd)
data_transforms = {
'train':transforms.Compose([
##VGG19输入数据的大小是224x224,先用resize调整大小
##Randomcrop随机剪裁,第一个参数是输出图像大小,仍是224x224,padding=16的意思是在在图像周围填充16像素(相当于在原图像添加了16圈像素点),然后再随机剪切出224x224大小
##ToTensor会将图像像素值缩放至0-1(除以255)
transforms.Resize((224,224)),
transforms.RandomCrop((224,224),padding = 16),
transforms.ToTensor(),
norm_transform
]),
'val':transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
norm_transform
])
}
test_transforms = transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
norm_transform
])
#使用自己定义的datasets加载数据
path = {'train': r'G:pytorchdogscats rain rain.txt',
'val':r'G:pytorchdogscatsvalval.txt'
}
test_path = r'G:pytorchcat_dog est est.txt'
image_datasets = {x: MyDataset(path[x],transform=data_transforms[x])
for x in ['train','val']}
test_datasets = TestDataset(test_path,transform=test_transforms)
data_loader = {x: DataLoader(dataset=image_datasets[x],batch_size=batch_size,shuffle=True)
for x in ['train','val']}
test_loader = DataLoader(dataset=test_datasets,batch_size=batch_size)
data_size = {x:image_datasets[x].__len__() for x in ['train','val']}
def train_model(model,criterion,optimizer,num_epochs):
since = time.time()
#保存验证集上准确率最高的模型
best_model = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print("Epoch {}/{}".format(epoch+1,num_epochs))
print("-"*10)
#每训练一个epoch后,验证一次
#model.tarin():启用BatchNormalization和Dropout
#model.eval() :不启用BatchNormalization和Dropout
for phase in ['train','val']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
for inputs,labels in data_loader[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
## val模式下关闭梯度 当确定不会调用Tensor.backward()计算梯度时,设置禁止计算梯度会减少内存消耗
outputs = model(inputs)
_,preds = torch.max(outputs,1)
#labels不需要one-hot编码
loss = criterion(outputs,labels)
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item()
running_corrects += (preds == labels).sum().item()
epoch_loss = running_loss / data_size[phase]
epoch_acc = running_corrects / data_size[phase]
print("{} Loss:{:.4f} Acc:{:.4f}".format(phase,epoch_loss,epoch_acc))
if phase =='val' and epoch_acc > best_acc:
best_model = copy.deepcopy(model.state_dict())
best_acc = epoch_acc
time_elpsed = time.time() - since
print("Training complete in {}m {}s".format(time_elpsed // 60,time_elpsed % 60))
print("Best val Acc:{:.4f}".format(best_acc))
model.load_state_dict(best_model)
return model
def test_model(model):
pred = []
for inputs in test_loader:
inputs = inputs.to(device)
outputs = model(inputs)
_,preds = torch.max(outputs,1)
for i in preds:
pred.append(i.item())
return pred
"""
使用VGG19模型预训练,我们只使用特征提取层(卷积层、池化层),并将参数冻结,我们自己用全连接层构造一个分类器,只对分类器中的权重进行训练。
"""
class VGG19(nn.Module):
def __init__(self):
super(VGG19,self).__init__()
net = models.vgg19(pretrained=True)
#net.features可以提取全连接池之前的特征提取层。
self.conv_net = net.features
#遍历特征提取层的每一层的参数,设置其requires_grad=False,将其冻结
for param in self.conv_net.parameters():
param.requires_grad = False
#inplace的表示是否直接修改原始输入。官方文档介绍:inplace=True意味着它将直接修改输入,而不分配任何额外的输出。它有时会稍微减少内存使用量,但可能并不总是有效的操作(因为原始输入已被破坏)。
#dropout层:每个单元有p的概率被暂时丢弃,与之相关联的权重不更新。
self.classifier = nn.Sequential(
nn.Linear(25088,1024),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5,inplace=False),
nn.Linear(1024,512),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5,inplace=False),
nn.Linear(512,32),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5,inplace=False),
nn.Linear(32,2),
)
def forward(self,x):
x = self.conv_net(x)
x = x.view(x.size(0),-1)
x = self.classifier(x)
return x
model = VGG19().to(device)
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
#Adam是一种学习率自适应的算法
optimizer = optim.Adam(model.parameters(), lr=0.001)
model = train_model(model, criterion, optimizer,
num_epochs=10)
pre = test_model(model)
#结果写入csv,保存模型
import csv
f = open('result.csv','w',encoding='utf-8',newline="")
csv_writer = csv.writer(f)
for i,pred in enumerate(pre):
csv_writer.writerow([i,pred])
f.close()
torch.save(model.state_dict(), 'parameter.pkl')

分析提高准确率的方法:
1、数据增强的方式可以再多样化一些
2、训练样本数目少,用完整数据集会好一点
2、可以添加BN层
3、可以使用ResNet的结构,训练更深层的网络