数据探索
Elasticsearch具有强大的数据检索和分析同能,支持模糊、全文、过滤、管道等数据查询。对于日志型数据处理很有优势。
下图为KIbana的主页图,将逐步说明每一部分的功能:

依照图中的编号:
1、Discover点击后是整个日志总况,这也是经常使用的入口,在这个地方可以定时刷新最新日志,过滤整个日志,添加指定字段显示,展示不同时段的日志总量等等。
2、显示8所选定的时间范围内的日志总量按时间的分布情况,通过该直方图,可以判断应用一天的高峰期时段,通常日志量越大,使用的用户越多。同时,当服务出现故障,会有某类日志暴增,所以环比前一天的数据可以判断服务运行状况。
3、具体日志显示区域,其中Time字段为固定字段,对应日志中的@timestamp字段,该区域从6的区域添加任何你想关注的字段值,在表头位置,鼠标放置该位置 有排序图表 以及左右移动的图标。
4、表示该条件下所查询到的日志总条数
5、当被添加到3(表格)中的字段会显示在该区域,鼠标滑到对应字段可以移除
6、可用字段区域,下方的字段鼠标滑上去会有 add 按钮, 通过该按钮可以添加到3的表格区域显示,点击字段名可以看出该字段的值分布占比。旁边的齿轮小按钮,点击后会展开输入框,输入字符后可以自动匹配下方的字段(该功能在字段特别多的情况下非常有用)。另外,该区域显示的字段总数可以在 Management -> Advanced Settings->Number of terms处设置最大显示字段数。字段中 前面的 t 表示字段类型为字符串, # 表示number字段,时钟表示时间类型字段(具体字段类型请查阅elasticsearch文档),?表示未maping字段,需要在Management ->Index Patterns 处选中对应的索引模式,点击右上角的刷新按钮。
7、查询输入框,查询方式以elasticsearch的query_string查询,如以下查询:
NOT(+app_feed_bug_1 +app_feed_bug_2 +app_feed_bug_3 +app_feed_bug_4 +app_feed_bug_5 +app_feed_bug_6 +app_feed_bug_7 +app_feed_bug_8 +app_feed_bug_9 +app_feed_bug_10)
表示app_feed_bug_1 到 app_feed_bug_10都不同时存在的结果。具体查询语法参考 https://www.elastic.co/guide/en/elasticsearch/reference/6.4/query-dsl-query-string-query.html#query-string-syntax
8、时间段选择,通过@timestamp字段过滤时间段
9、查询条件保存操作,当我们配置好一次查询之后,希望下次可以直接使用,就可以点击该按钮进行保存
10、保存的查询条件可以通过点击此处打开
11、定时刷新操作
12、添加日志字段过滤,支持 is , is one of 等等条件过滤,是一个经常使用而其非常强大的功能
告警模块
sentinl 插件安装,kibana插件安装很简单,只需要注意插件版本和kibana版本保持一致即可。以下是一个安装sentinal 6.4.0的命令:
在kibana安装目录的/bin 目录下执行:
./kibana-plugin install https://github.com/sirensolutions/sentinl/releases/download/tag-6.4.2-0/sentinl-v6.4.0.zip
kibana-plugin会自动下载并解压安装该插件,以及下载安装插件的依赖。默认安装目录在 kibana目录的plugin目录下。
插件的依赖声明在插件包的package.json文件中,其使用方式和nodejs的 npm一致。
插件安装好之后,重启kibana。打开kibana,可以看到左侧已经有Sentinl 菜单,单击该菜单可以添加告警规则,以下展示一个告警规则的配置(可以使用配置向导图形化操作之后再更改):
1 { 2 "actions": { 3 "email_html_alarm_07ba0173-4e8e-4835-afb9-654687859fdd87": { 4 "name": "复习模块资源错误", 5 "throttle_period": "24h", //告警频率阀,如果满足告警条件,每多少时间告警一次,防止频繁消息,这儿显示24小时限制告警一次 6 "email_html": { //以email的形式告警 7 "stateless": false, 8 "subject": "[告警] - {{payload.hits.hits.0._source.app_ppt_module}} - {{payload.hits.hits.0._source.app_ppt_name}} - {{payload.hits.hits.0._source.app_ppt_error_type}} From日志系统", //email的主题 9 "priority": "high", 10 "html": "<p><p>模块:{{payload.hits.hits.0._source.app_ppt_module}}</p><p>名称:{{payload.hits.hits.0._source.app_ppt_name}}</p><p>出错页码:{{payload.hits.hits.0._source.app_ppt_file_name}}</p><p>出错类型:{{payload.hits.hits.0._source.app_ppt_error_type}}</p><p>userid:{{payload.hits.hits.0._source.user_id}}</p><p>From:日志系统, <i>修改告警邮件请联系 谢正才</i></p></p>", //EMAIL的邮件内容 11 "to": "qqq@qq.com,bbbb@ddd.com,bbb@ddd.com,bb@ddd.com", //邮件的接收这 12 "from": "xxxx@xxxxx.com" //邮件的发送者,该值需要再kibana配置,稍后会有介绍 13 } 14 } 15 }, 16 "input": { 17 "search": { 18 "request": { 19 "index": [ 20 "client_report-*" 21 ], 22 "body": { 23 "query": { //这儿表示的是一个elasticsearch搜索 24 "bool": { 25 "must": [ 26 { 27 "match": { 28 "app_eventid": "app1096" 29 } 30 }, 31 { 32 "match": { 33 "app_ppt_module": "复" 34 } 35 }, 36 { 37 "range": { 38 "@timestamp": { 39 "gte": "now-1440m", 40 "lt": "now" 41 } 42 } 43 } 44 ] 45 } 46 } 47 } 48 } 49 } 50 }, 51 "condition": { 52 "script": { 53 "script": "payload.hits.total > 2" //告警条件,此处表示查询条数大于2条开始告警 54 } 55 }, 56 "trigger": { 57 "schedule": { 58 "later": "every 5 minutes" //每5分钟执行一次告警条件 59 } 60 }, 61 "disable": false, 62 "report": false, 63 "title": "复习模块资源错误告警", 64 "save_payload": false, 65 "spy": false, 66 "impersonate": false 67 }
该告警规则中,可以访问Elasticsearch查询结果中的字段,如:payload.hits.hits.0._source.app_ppt_module 获取app_ppt_module字段的值,(注意:如果数组不是用[0]的方式,而是 .0 的方式)
kibana.yml 中增加配置:
sentinl: settings: email: active: true user: xxxx@xxxx.com password: xxxx host: smtp.exmail.qq.com port: 465 ssl: true report: active: true
该配置设置了发送邮箱的相关参数,包括密码、smtp服务器等。配置好之后重启kibana。
总体来说,该告警功能还是比较强大的。也支持webhook等告警方式,
可视化
可视化是Kibana中很重要的一部分,而其也很强大。下图展示一张折线图的配置(看上去是柱形图,实际是折现图,只是在展现形式上做了调整,文中会说明)
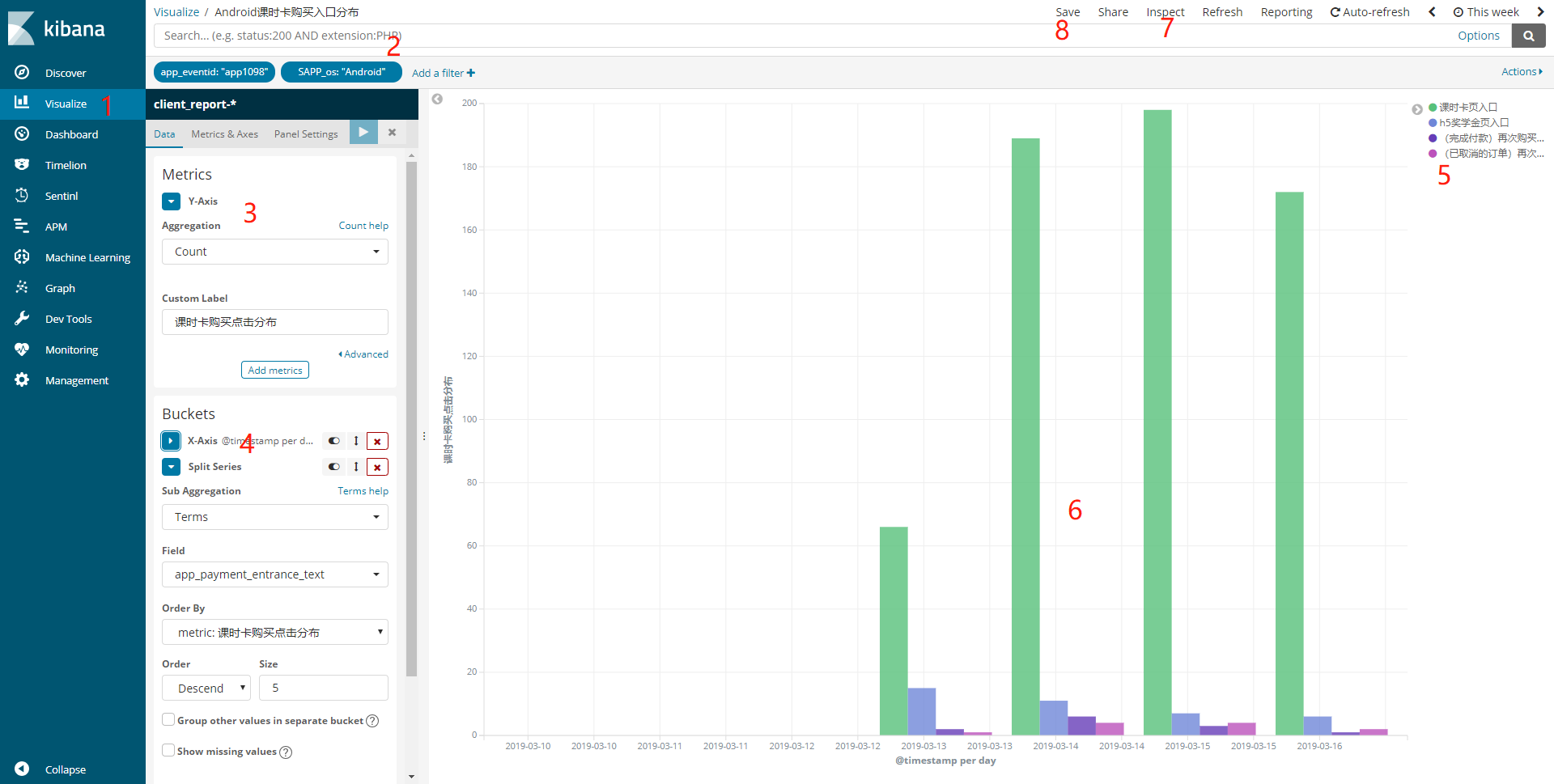
按图中的顺序,一步一步说明:
1、可视化的菜单入口
2、查询输入框和过滤栏,使用方式和Discover处相同,该处的条件设置好以后,则定义好了图表的数据总体,表明图表在该数据总体上去做可视化。是很关键和重要的一步。在我们考虑要做一张图形化的时候,第一步就该考虑数据总体是什么。
3、需要观察的指标,图中表示我要观察count值,配合第二条,此时说明我想count 该查询条件下的日志总数,在这儿特别说明一下,指标的计算类型:
Average : 求总量的平均值,需要指定number型字段
Count: 计算总量的总条数,
Max:计算总量的最大值,需要指定number型字段
Median:计算总量中的中间值,需要指定number型字段
Min:计算总量的最小值,需要指定number型字段
Percentile Ranks
Percentile
Standard Deviation 计算总量的均方差,需要指定number型字段
Sum 计算总量的总和,需要指定number型字段
Top Hit
Unique Count 去重统计总条数,如计算独立IP数、独立userid数等非常有用
Average Bucket
Max Bucket
Min Bucket
Sum Bucket
Cumulative Sum 对总量的累计汇总,比如每分钟日志条数是 10 、 12、15、8、15、13 。那么按每两分中按该公式计算的结果为, 10+12 = 22、10+12+15+8 = 45、0+12+15+8+15+13 = 73,最终结果为 22、45、73
Derivative 导数,需要添加一个计算公司,该计算方式会自动计算该公式的导数值。
Moving Avg 移动平均数,类似与股票中的移动平均线
Serial Diff 微分
4、桶配置,桶时根据字段值的不同,将数据分为不同的部分,每一个部分就叫一个桶,比如说 字段 a 是 1-100的数字, 可以将a 分为 1- 20 , 21- 50, 51-70 ,71-100 四个桶。因此对于不同的数据类型,桶可以分为以下几种:
Date Histogram 以时间日期字段 按 天、按 年、 按月 ...分桶。
Date Range 日期范围,指定日期的间断来分桶
Filters 指定多个过滤条件,将数据分为多个桶,该方式做漏斗型数据非常有效
Histogram 指定一个数值字段,然后给定一个间隔长度,以此间隔来分桶
IPv4 Range 根据IPv4的范围来分桶
Range 指定要给数值字段,然后指定多个数值区间(类似于上面的列子),以该数值区间进行分桶
Significant Terms
当桶配置好之后,数据总量被分配到不同的桶中。
熟悉桶的概念之后,对于X-Axis就很容易理解 : X坐标即使根据桶的数量生成坐标刻度,而桶的生成过程也是聚合的过程。下面介绍在桶中进行 Split Series:
Split Series 即使在桶内根据字段的值的不同进行拆分成不同的小块,拆分的块数多少在图表中形成多少条折线。
Split Chart 即拆分为不同的图表,这都是在桶内进行的。
5、图列,在对桶进行中的数据进行 Split Series 时,图列会显示拆分后的字段分布值,该值有可能时1、2、3、4 ...这样的数字表示,比如说1 表示 首页入口 、2 表示个人中心入口 等,这样的数字作为图列时很难看懂的,这个时候如果需要友好的图列,kibana中没有直接配置的入口,需要在使用脚本字段,编写painless语句(该部分内容下面会有介绍),然后使用添加好的脚本字段作为 Split Series的字段,最终才能得到友好的图列显示。
6、最终显示图表,图中的图表类型为线图,为什么显示为柱状图呢?是在图表配置的Metrics & Axes 中的 Chart Type 配置为 bar。
7、查看该图表在elasticsearch的查询情况,配置图表过程中非常有用
8、保存图表,记得保存,保存后可以添加到面板。
脚本字段
在mysql中我们经常会 用 AS 将一个计算表达式的结果赋值给一个字段,这在elasticsearch中怎么做呢? 答案是:使用脚本字段。
脚本字段采用painless语言,关于该语言的学习,参靠elasticsearch官方网站:https://www.elastic.co/guide/en/elasticsearch/painless/current/painless-getting-started.html 。
在kibana中配置painless入口:management->Index Patterns->Scripted fields ,点击 Add scripted field 按钮可以得到下面的配置界面:
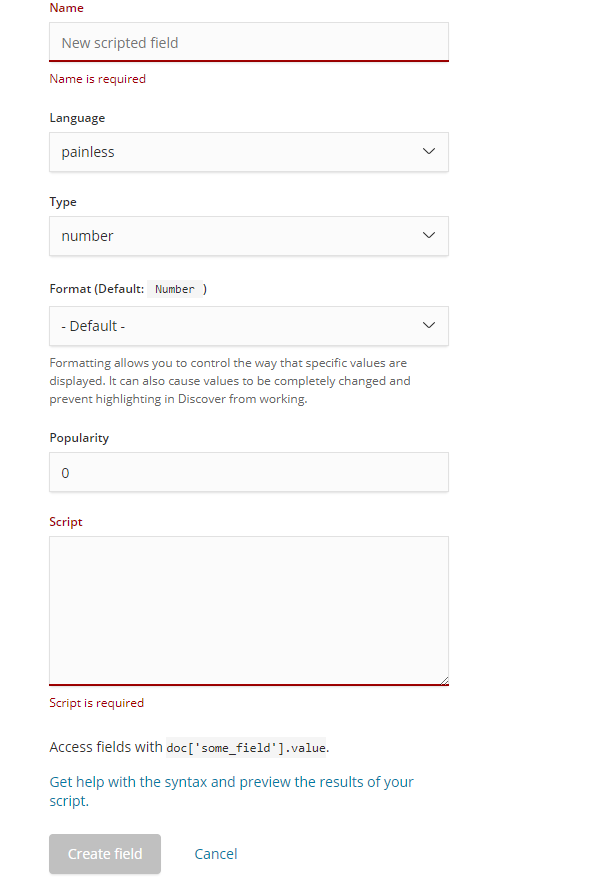
Name:脚本字段的名字, 类似mysql AS 后的字段名
Language: 采用的语言,有两种:painless 和 expression , painless是elasticsearch标准语言,强大、性能好。expression是elasticsearch表达式
Type:字段类型
Format: 字段格式
Popularity: 优先级,通常优先级高于0, 0是普通字段的优先级
Script:脚本类容,通过return来赋值给 Name 处填写的字段
关于painless的学习,这儿不再赘述, 下面是一个脚本样例:
if('app1097'.equals(doc['app_eventid.keyword'].value) || 'app1098'.equals(doc['app_eventid.keyword'].value) ){ if('7'.equals(doc['app_payment_entrance.keyword'] .value)) { return '我的账户入口'; } if('8'.equals(doc['app_payment_entrance.keyword'] .value)) { return '充值记录入口'; } if('1'.equals(doc['app_payment_entrance.keyword'] .value)) { return 'h5奖学金页入口'; } if('2'.equals(doc['app_payment_entrance.keyword'] .value)) { return 'h5活动页入口'; } if('3'.equals(doc['app_payment_entrance.keyword'] .value)) { return '课时卡页入口'; } if('4'.equals(doc['app_payment_entrance.keyword'] .value)) { return '(上课记录)去付款入口'; } if('5'.equals(doc['app_payment_entrance.keyword'] .value)) { return '(完成付款)再次购买入口'; } if('6'.equals(doc['app_payment_entrance.keyword'] .value)) { return '(已取消的订单)再次购买'; } }
该脚本返回一个字符串类型的数据,赋值给Name处命名的字段。
漏斗视图
kibana没有自带的 可视化 漏斗视图,需要在kibana安装ob-kb-funnel插件,该插件的github地址:https://github.com/outbrain/ob-kb-funnel,该插件目前最新支持到 6.4.0,但是没有release的包,安装步骤如下:
a、下载仓库代码,
b、修改package.json包中的json至如下所示:
{ "name": "ob-kb-funnel", "version": "6.4.0", "kibana": { "version": "6.4.0" }, "devDependencies": { "numeral": "1.5.3", "d3-funnel": "^1.2.0" } }
主要修改 version 和 kibana.version字段,修改与所支持的版本,注意:该版本也要与kibana的版本一致。
c、拷贝到kibana的plugins下,进入该目录, 执行 npm install (如果提示没有安装npm,网上查找nodejs npm 安装),会自动下载所依赖的包,安装在node_module下面。
d、重启kibana及可。
安装好之后会在可视化界面选择视图类型处看到Funnel View 组件,