梯度下降是不同于Normal Equals的方式;梯度本质是一个试错过程,不断的尝试一个个theta,寻找能够使的成本函数值最小的可能性。所谓下降是指不断的theat的取值是不断小步减少的;梯度,是指这个减少是逐渐,非线性的。
梯度下降有三种常见的函数:批量梯度下降,随机梯度下降以及最小化梯度下降。
先来看批量梯度下降,在Normal Equal里面我们接触了函数MSE,那么在梯度下降里面我们还是要接触这个MSE,但是因为theta值有多个,所以,每个theta都是一个维度,对于某个指定维度求最小值,我们对其进行求导:
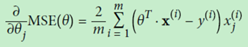
如果想要同时对多个theta求向量,可以放置到一个向量中进行,公式如下:

这样对于多个theta的最小成本函数的求值转变为了矩阵公式(上图右侧部分)。因为线性的成本函数是凸函数,所以我们不用安心拐点问题,只要theta值不断减少,cost值就会不断减少。通常的做法是定义一个迭代的次数,即梯度的台阶数,向下的每个台阶都比之前的台阶要小,小的程度就是上面公式的计算值;这样获取到的theta就是某种程度上满足了的成本函数的最小值。
实现的python代码如下:
theta_path_bgd = []
def plot_gradient_descent(theta, eta, theta_path=None):
m = len(X_b)
plt.plot(X, y, "b.")
n_iterations = 1000 # 定义迭代的次数
for iteration in range(n_iterations):
#为了更加直观,前10个数据(线段)将会被打印出来
if iteration < 10:
y_predict = X_new_b.dot(theta)
style = "b-" if iteration > 0 else "r--"
plt.plot(X_new, y_predict, style)
gradients = 2/m * X_b.T.dot(X_b.dot(theta) - y) #核心的公式计算,计算下降的梯度
theta = theta - eta * gradients #theta值
if theta_path is not None:
theta_path.append(theta)
plt.xlabel("$x_1$", fontsize=18)
plt.axis([0, 2, 0, 15])
plt.title(r"$eta = {}$".format(eta), fontsize=16)
rnd.seed(42)
theta = rnd.randn(2,1) # random initialization
plt.figure(figsize=(10,4))
plt.subplot(131); plot_gradient_descent(theta, eta=0.02)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.subplot(132); plot_gradient_descent(theta, eta=0.1, theta_path=theta_path_bgd)
plt.subplot(133); plot_gradient_descent(theta, eta=0.5)
plt.show()
划线的部分就是公式计算部分,也是整个计算过程的核心;在真实调用中,分别通过学习率0.02,0.1以及0.5进行学习,学习的效果如下图所示,可见学习率在0.1的时候是最好的,但是在0.5则有些过,而且现象是线段在点集的上下乱窜,说明这个学习率是不可取的。0.02则学习的结果则是总在点集的下方。
批量的梯度下降已经比normal equals快很多了为什么快?因为NE的算法中用一个矩阵的inverse(求逆矩阵),对NE算法而言将会导致一个N*N矩阵的一次求逆矩阵的操作,非常耗时,这一点在属性(feature)很大的时候,将会非常明显,所以如果万级别的,NE操作比较合适,但是超过万级别的,梯度下降的算法将会更优,当然这个说法有待验证。
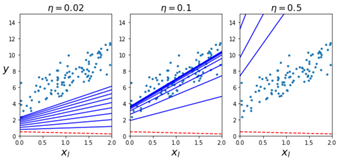
但是每次梯度计算都是要全集计算,仍然开销很大;有一种方法开销非常小,而且得到的效果和全量计算差不多的,那就是随机梯度下降。他的算法就是随机抽取m个X,y值,然后根据这个X,y值来计算梯度,注意此X非彼X,只是X全集中的一个元素,矩阵中的一列(一行),y其实只是一个值,这样你在来通过公式来算梯度,那可就小的多了。
Python实现如下:
theta_path_sgd = []
n_iterations = 50
t0, t1 = 5, 50 # learning schedule hyperparameters
rnd.seed(42)
theta = rnd.randn(2,1) # random initialization
def learning_schedule(t):
return t0 / (t + t1)
m = len(X_b)
for epoch in range(n_iterations): #迭代n次(N个台阶下降)
for i in range(m): #每次取m个值进行梯度下降
if epoch == 0 and i < 20:
y_predict = X_new_b.dot(theta)
style = "b-" if i > 0 else "r--"
plt.plot(X_new, y_predict, style)
random_index = rnd.randint(m)
xi = X_b[random_index:random_index+1] #取出X值,一个向量
yi = y[random_index:random_index+1] #取出y值,单个值
gradients = 2 * xi.T.dot(xi.dot(theta) - yi) #梯度值
eta = learning_schedule(epoch * m + i) #学习率,这个公式什么用意,其实没懂
theta = theta - eta * gradients
theta_path_sgd.append(theta)
plt.plot(X, y, "b.")
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.axis([0, 2, 0, 15])
plt.show()
theta
array([[3.90754833] ,[3.1762325 ]])
然后用ski内置的梯度下降SGDRegression来求解,注意:SGDRegression内部封装的就是随机梯度下降的算法:
from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(max_iter=50, penalty=None, eta0=0.1)
sgd_reg.fit(X, y.ravel())
sgd_reg.intercept_, sgd_reg.coef_
输出:
(array([3.87605957]), array([3.08965292]))
基本是一样的,SGD里面的算法就是酱紫的(上面的上面的代码)。
最后一种就是mini-batch,其实和随机梯度下降非常类似,只不过SGD每次取出一个X,y,mini-batch则是每次取出一批来,差别就在这里,下面是实现:
theta_path_mgd = []
n_iterations = 50
minibatch_size = 20
rnd.seed(42)
theta = rnd.randn(2,1) # random initialization
t0, t1 = 10, 1000
def learning_schedule(t):
return t0 / (t + t1)
t = 0
for epoch in range(n_iterations):
shuffled_indices = rnd.permutation(m)
X_b_shuffled = X_b[shuffled_indices]
y_shuffled = y[shuffled_indices]
for i in range(0, m, minibatch_size): # 遍历m次,每次增长minibatch_size
t += 1
xi = X_b_shuffled[i:i+minibatch_size]
yi = y_shuffled[i:i+minibatch_size]
gradients = 2 * xi.T.dot(xi.dot(theta) - yi)
eta = learning_schedule(t)
theta = theta - eta * gradients
theta_path_mgd.append(theta)