大家好,我是小鸭酱,博客地址为:http://www.cnblogs.com/xiaoyajiang
pyAudioAnalysis是一个音频分析python库,用于Feature Extraction, Classification, Segmentation 和Applications,其github见 https://github.com/tyiannak/pyAudioAnalysis
由于时间紧凑,每次更新一点,请见谅。
1 安装
非常容易,如果你使用的是Linux下的pycharm,那么new一个project,再设置其解释器为python2.7,然后再点击绿色的+号,搜索pyAudioAnalysis,点击install,那么pycharm就可以自动为你解决好所有的依赖问题。好开心。当然,你如果不想用pycharm,你可以直接使用pip安装,见https://github.com/tyiannak/pyAudioAnalysis/wiki/2.-General,也很容易。
2 功能介绍
安装好以后,可以看到其包含如下6个python文件:
| python文件名 | 功能概览 |
| audioAnalysis.py | 算法库基本功能的命令行界面,及一些记录功能 |
| audioFeatureExtraction.py | 所有的音频特征提取算法实现。总共计算了21个短期特征(short-term features),同时还实现了中期开窗技术(mid-term windowing technique)以提取音频特征的统计数据 |
| audioTrainTest.py | 音频分类程序。包含用于训练支持向量机(SVM)或k-最近邻分类器(knn classifier)。此外,还提供包装函数和脚本,用于通用训练(general training),评估和特征标准化(feature normalization) |
| audioSegmentation.py | 该文件实现了音频分段(segmentation)功能,例如,定长语音段分类(fixed-sized segment classification),和分段(segmentation),说话人分割(speaker diarization),等 |
| audioBasicIO.py | 这个文件实现了一些基本的音频输入输出功能,以及文件转换 |
| audioVisualization.py | 产生用于友好和具有代表性内容的可视化 |
在 data/ 文件夹中, 提供了几个音频样本文件,以及训练好的SVM和kNN模型,它们用于特定分类任务的(例如,语音vs音乐,音乐风格分类)
2.1 特征提取(Feature Extraction)
在音频特征提取方法论中,有两个阶段:
- 短期特征提取(short-term feature extraction):见audioFeatureExtraction.py文件中的stFeatureExtraction()函数,可见"st"是“short-term”的缩写。它将输入信号分解为短期窗口(short-term windows)(帧),并计算每帧的若干特征。该过程引入了整个信号的一系列短期特征向量(short-term feature vectors)。
- 中期特征提取(mid-term feature extraction):在大多情况下,上述短期特征序列(short-term feature sequences)的统计数据足以表示信号。为此,audioFeatureExtraction.py文件中的函数mtFeatureExtraction()会在每个短期特征序列上提取许多统计量(如均值,标准差)。
pyAudioAnalysis提供了34个短期特征(short-term features),如表:
| 编号 | 特征名 | 描述 |
| 1 | 过零率(Zero Crossing Rate) | 在特定帧的持续时间内,离散采样信号值的正负符号变换次数,体现频率特征 |
| 2 | 能量(Energy) | 信号值平方和,由相应的帧长度归一化 |
| 3 | 能量熵(Entropy of Energy) | 子帧(sub-frames)归一化能量之熵,一种突变度量 |
| 4 | 谱频率中心(Spectral Centroid) | 又称为频谱一阶距,频谱中心的值越小,表明越多的频谱能量集中在低频范围内,如:voice与music相比,通常spectral centroid较低 |
| 5 | 频谱延展度(Spectral Spread) | 又称为频谱二阶中心矩,它描述了信号在频谱中心周围的分布状况 |
| 6 | 谱熵(Spectral Entropy) | 分布越均匀,熵越大,能量熵反应了每一帧信号的均匀程度,如说话人频谱由于共振峰存在显得不均匀,而白噪声的频谱就更加均匀,借此进行VAD便是应用之一 |
| 7 | 频谱通量(Spectral Flux) | 两个连续帧的光谱归一化幅度之间的平方差。 |
| 8 | 频谱滚降点(Spectral Rolloff) | 低于90%频谱分布的频率集中。 |
| 9-21 | ||
| 22-33 | ||
| 34 |
2.2 分类和回归(Classification and Regression)
2.3 语音分割(Segmentation)
Segmentation对于大多数语音分析来说都是非常重要的。目标是将连续语音分离为同质段。分割可以是
- 监督:适用于监督类信息被使用于分类和语音分割。这要么通过应用分类器来将连续的固定大小的片段分类为一组预定义的类或通过使用HMM方法来实现联合分割分类来实现。
- 无监督:监督模型不可用,检测到的片段聚集(例如:speaker diarization)
2.3.1 固定分段分类和分类(Fixed-segment Segmentation & Classification)
此功能的目标是将现有的分类器应用于音频录制的固定大小段,产生表征整个信号的一系列类别标签。 因此,正是audioSegmentation.py文件中的函数mtFileClassification() 的用武之地。
函数mtFileClassification() 的功能有如下4个:
- 将音频信号分割为连续的中期分段,并从这些分段中提取中期特征统计数据,(使用audioFeatureExtraction.py文件中的mtFeatureExtraction()函数)
- 使用预先训练的监督模型对每个片段进行分类
- 将相同类标签的连续的固定大小段,进行合并
- 可视化有关分割结果的统计分类过程
心心念念的代码来啦:
1 from pyAudioAnalysis import audioSegmentation as aS 2 [flagsInd, classesAll, acc, CM] = aS.mtFileClassification("data/scottish.wav", "data/svmSM", "svm", True, 'data/scottish.segments')
请注意,该函数的最后一个参数是.segments文件。这被用作地面实况(ground-truth,如果有的话),以便估计分类—分割(classification-segmentation)方法的总体性能。 如果此文件不存在,则不会计算性能度量。 这些文件是格式简单的逗号分隔文件:<起点 (seconds)>,<终点(seconds)>,<此段标签>。.segments文件格式栗子:
0.01,9.90,speech 9.90,10.70,silence 10.70,23.50,speech 23.50,184.30,music 184.30,185.10,silence 185.10,200.75,speech ...
函数plotSegmentationResults()用于绘制结果分段分类和评估此结果的性能(如果ground-truth文件可用)。命令行的使用语法如下:
python audioAnalysis.py segmentClassifyFile -i <inputFile> --model <model type (svm or knn)> --modelName <path to classifier model>
比如敲入这样的:
python audioAnalysis.py segmentClassifyFile -i data/scottish.wav --model svm --modelName data/svmSM
据说,上面的命令行执行会生成下图(在上面的示例中,data / scottish.segmengts被找到并自动用作计算总体准确性的ground-truth)
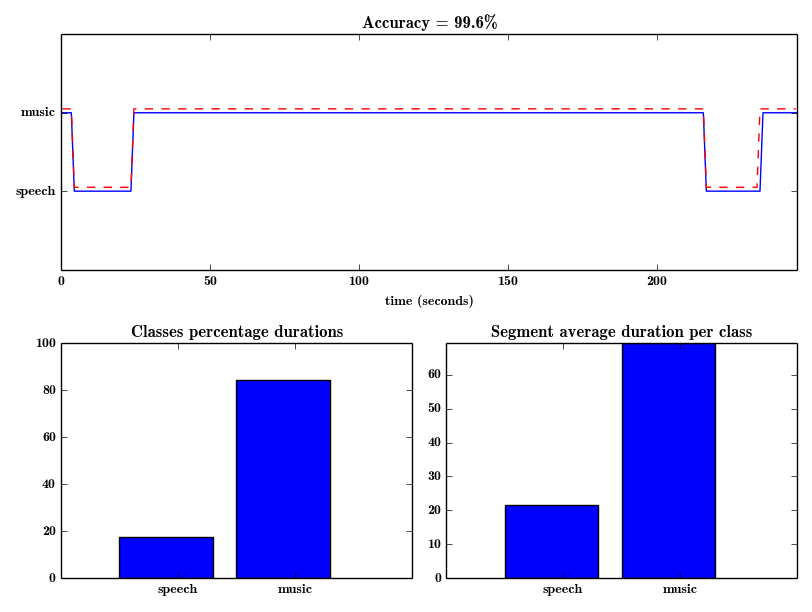
注意在下一节(基于hmm的分割分类)中,我们介绍如何使用注释数据集评估修正大小的方法和hmm方法。
2.3.2 基于HMM的分割和分类(HMM-based segmentation and classification)
2.3.3 无声移除和事件检测(Silence Removal and Event Detection)
算法库还提供半监督式的无声移除(silence removal)功能。 来自audioSegmentation.py的函数silenceRemoval()将不间断的音频记录作为输入,并返回对应于单个音频事件的段端点(segments endpoints),从而消除录音的“无声”区域。 这是通过执行以下步骤的半监督方法实现的:
-
整个录音的短期特征被提取出来
-
训练SVM模型以区分高能量和低能量短期帧。 特别是,10%的最高能量帧和10%的最低能量用于训练SVM模型
-
SVM分类器在整个记录中被应用(具有概率性输出),导致对应于各个短期帧属于音频事件(并且不属于无声段)的置信度水平的概率序列。
-
动态阈值用于检测活动段
silenceRemoval()采用以下参数:信号,采样频率,短期窗口大小和步长,用于平滑SVM概率序列的窗口(以秒为单位),介于0和1之间的因子指定阈值的严格程度, 最后是一个与绘制结果相关的布尔值。 再来一波代码:
1 from pyAudioAnalysis import audioBasicIO as aIO 2 from pyAudioAnalysis import audioSegmentation as aS 3 [Fs, x] = aIO.readAudioFile("data/recording1.wav") 4 segments = aS.silenceRemoval(x, Fs, 0.020, 0.020, smoothWindow = 1.0, Weight = 0.3, plot = True)
在本例中,segments是分段端点(segments endpoints)的列表,即每个元素是两个元素的列表:分段开始和分段结束(以秒为单位)。
一个命令行调用可以用来生成带有检测到的段的WAV文件。 在以下示例中,还会执行使用预定义的分类器(在本例中,演讲vs音乐)对所有结果段进行分类:
python audioAnalysis.py silenceRemoval -i data/recording3.wav --smoothing 1.0 --weight 0.3
python audioAnalysis.py classifyFolder -i data/recording3_ --model svm --classifier data/svmSM --detail
下图显示了文件data/recording3.wav上的静音删除输出(垂直线对应于检测到的段限制):
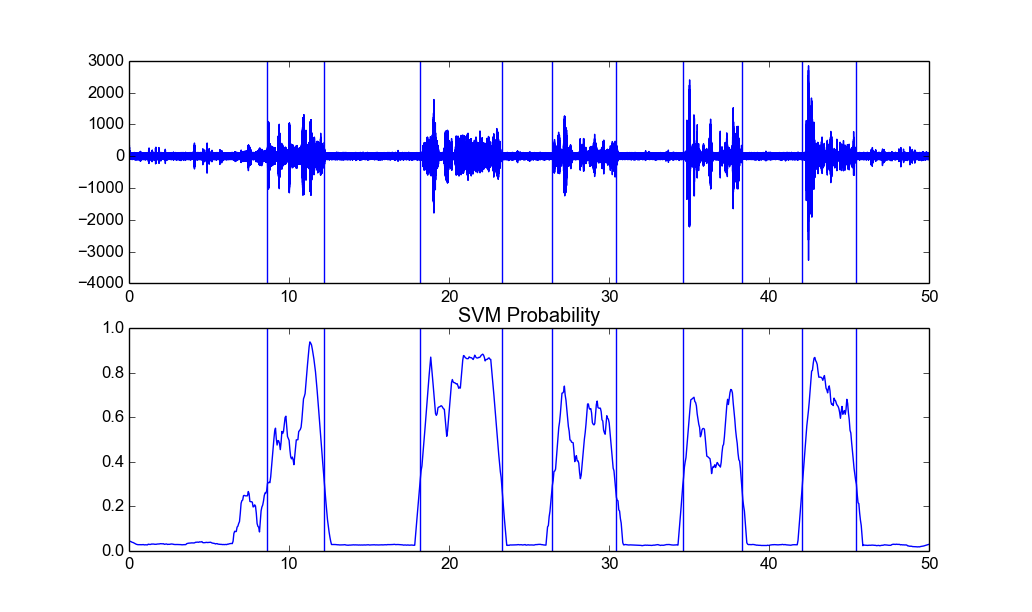
根据研究中记录的性质,必须使用不同的平滑窗口长度和概率权重。 上述例子适用于两个相当稀疏的记录(即相当长的寂静期)。 对于连续语音记录(例如data/count2.wav),必须使用更短的平滑窗口和更严格的概率阈值,例如:
python audioAnalysis.py silenceRemoval -i data/count2.wav --smoothing 0.1 --weight 0.6
2.3.4 说话人切分(speaker diarization)
pyAudioAnalysis主要实现了论文Fisher linear semi-discriminant analysis for speaker diarization。
一般来说,这些是实施的diarization方法执行的主要算法步骤:
-
Feature extraction: 如特征提取(Feature Extraction)阶段所述,以短期为基础提取MFCC,并在中期基础上提取这些特征序列的平均值和标准偏差。建议的短期窗口(short-term window)大小为50 ms,步长(step)为25 ms,而纹理窗口(texture window 中期窗口)的大小为2秒,重叠率为90%(即中期步长为0.2秒)。 此外,pyAudioAnalysis实现了在特征提取阶段添加监督知识的能力。 这里的“监督”不是指分析录音的说话人,而是指一组预定义的说话人模型。 例如,通过将相应音频片段属于男性或女性说话者的概率相加,中间特征统计向量得到增强,其中该性别分类模型已经事先在一组注释片段上被训练(为此目的使用训练的模型,命名为 knnSpeakerFemaleMale
-
(Optional) FLsD step :在这个阶段,我们使用FLsD方法获得中期特征统计向量的接近最优的说话者鉴别投影。 具体来说,每个固定尺寸的纹理片段(2秒)被分配一个新的说话人线程,并且该片段内的特征向量被用于获得说话人线程平均特征向量和散布矩阵,并且还用于更新整个类内线程 以及用于FLsD方法的混合类散布矩阵。 最后,将散布矩阵作为Fisher准则的参数给出以获得最佳的说话人识别子空间。
-
Clustering:执行k-means聚类方法(在原始特征空间或FLsD子空间上)。 这产生了一系列簇标签(每个纹理窗口一个标签)。 k-means算法将用户提供的数量的簇(说话人)作为参数。 如果这不是先验已知的,则对于一定数量的说话人重复聚类过程,并且使用轮廓宽度标准[11]来确定每种情况下聚类结果的质量,并因此确定最佳数目 的说话人。
-
Smoothing :结合两步平滑处理(a)对提取的簇ID进行中值滤波和(b)维特比平滑步骤。
给出一个音频文件,audioSegmentation.py文件中的speakerDiarization()函数可以用于提取其音频片段和相应群集标签的序列(请参阅参数文档的源代码等)。此外,speakerDiarization()函数也使用了evaluateSpeakerDiarization()函数,用来与集群标签序列进行比较,其中之一是基础事实(ground-truth),从而提取评估指标,具体而言,是计算簇纯度(cluster purity)和说话者纯度(speaker purity)。因此,我们需要.segment ground-truth文件(与WAV输入文件具有相同的名称),类似于一般的音频分段情况。 最后,函数speakerDiarizationEvaluateScript()可用于提取一组音频录制的整体性能度量,并提取其相应的.segment文件并存储在一个目录下。
命令行举栗:
python audioAnalysis.py speakerDiarization -i data/diarizationExample.wav --num 4
该命令采用以下参数:-i <fileName>, --num <numberOfSpeakers (0 for unknown)>, --flsd (flag to enable FLsD method).
这个例子的结果如下图所示(ground-truth也用红色表示)。 性能测量结果显示在图的标题中。
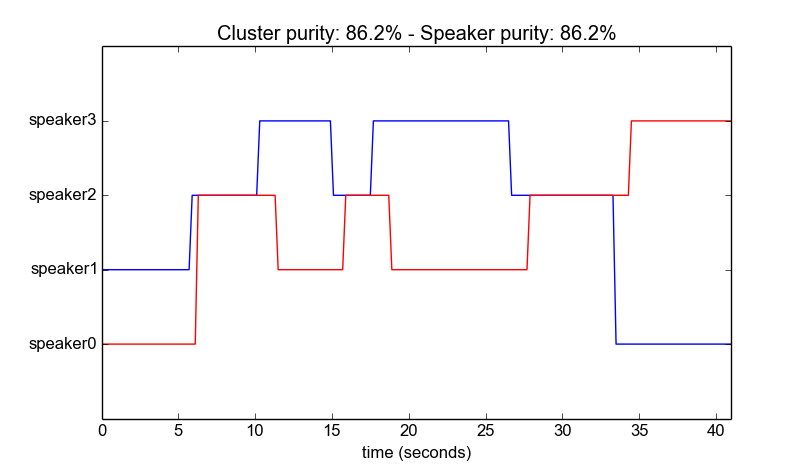
注1整个speaker diarization功能可应用于群集录音的任何任务。
2.3.5 音频缩略图(Audio thumbnailing)
音频缩略图(Audio thumbnailing)是音乐信息检索的重要应用,其重点在于检测音乐录制的最具代表性部分的实例。
2.4 数据可视化(Data-visualization)
2.5 音频再识别功能(Audio-Recording-Functionalities)
2.6 其他功能
有部分术语的解释参考好文如下,也是学习的好资料,感谢
1. https://blog.csdn.net/qq_39516859/article/details/80178135