[提要]
随着人工智能技术的快速发展, 深度学习,强化学习等技术不断进入各行各业。金融领域也不例外,利用深度学习进行
大数据挖掘,分析客户的画像,提供对应的金融服务已经在现实中使用。 在金融交易领域其中一个分支量化交易(金融工程)
采用相关的人工智能技术,必将大势所趋。 本文主要是针对证券期货交易的量化交易采用深度神经,卷积神经网络在交易
信号选取的一个落地应用。 深度学习和金融工程都是属于高精尖专业, 不足,不周之处,请勘正。
关键词:金融工程, 量化交易,深度学习,卷积神经网络,VGG
[引言,背景]
在量化交易系统中, 一般系统分为三个部分: 交易信号(模式识别), 持仓控制, 资金管理。 交易信号指的是,在
什么时间点,买入什么股票(本文均已股票二级市场,且为散户的角度做说明)。 持仓控制是指, 在买入股票后,根据
后期的股票走势进行,加仓,减仓,平仓等操作。 而资金管理,是对许多交易策略进行资金分配,用来保证资金在固定时
间周期内达到最低的风险和最大的收益平衡。 下文是利用卷积神经网络对交易信号的识别。
[正文]
人类识别股票行情的方式是直观的,拟态的, 比如多根均线向上, 均线交叉,多根阳线,多根阴线等。 传统的量化交易
把这些抽象的图提取成数学数据, 再用条件判断,形成信号。再利用统计学,统计后期的收益情况来分析信号的性能(准确率)。
在深度学习领域里, AI已经能高概率的识别数字, 图像内容。 那人工智能是否能(依靠图像感知,而非数据的表示)识别,读
懂金融的k线, 折线呢?答案是肯定的。
(以下试验论述会有较多多的神经网络和编程术语)
我们将一个股票的当天分时线提取成 48 个5分钟的k线,再根据k线绘制成图像。 如下:
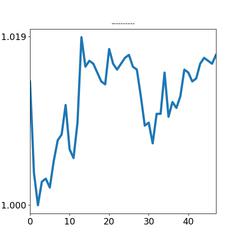
我们将日内走势分型, 暂分为: 横盘震荡, 上行, 下行, V形, A形, 例如:
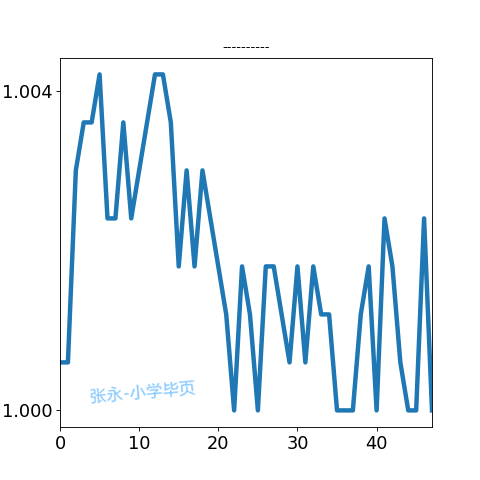

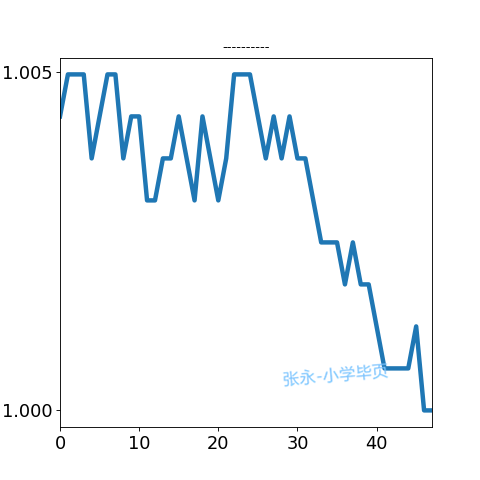

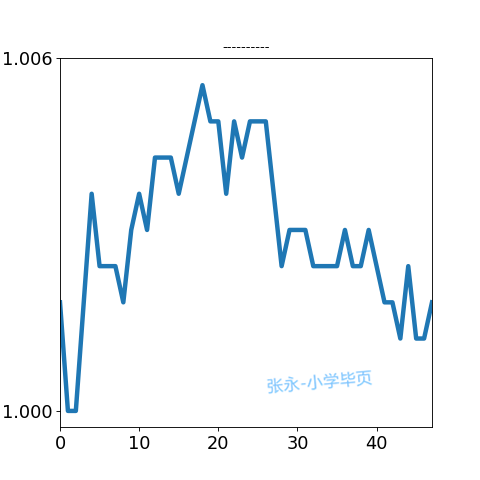
我们根据2017年上半年实际沪深行情, 制作了40多万个日内图, 并对其中10万个图进行了,机器+人工标识。 我们得到了10万个训练/测试数据。
数据内容 : 480x480 分辨率的图片 + 对应的分型标识(0,1,2,3,4 )
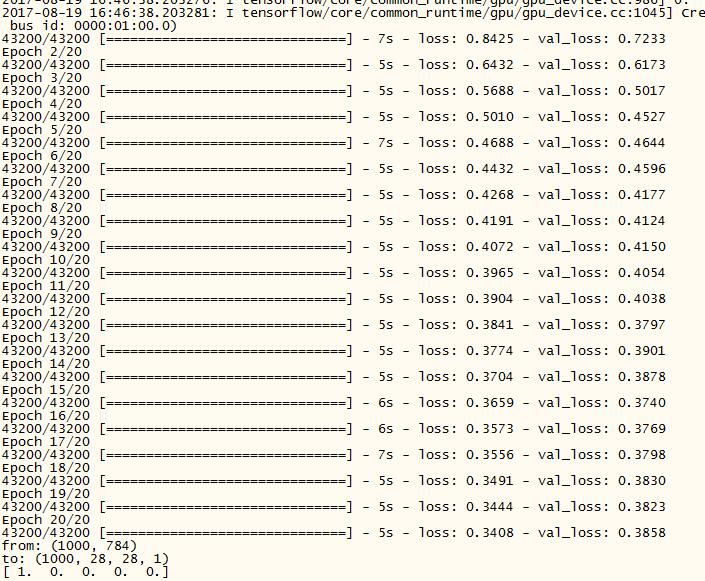
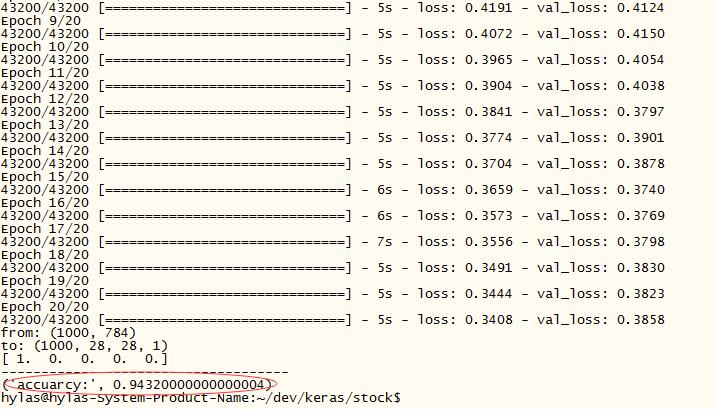
我们的试验内容:把10万个数据扔给卷积神经网络进行训练; 用另外的 1000 个数据进行测试(测试数据不参与训练)。 试验结果: VGG 卷积神经网络
的准确为:94%(尚未调优)。 (实际实验数据目前为 48000 )
在试验过程中,我们碰到许多问题, 把这些问题也简单的罗列一下,以便再研究深度学习的同学,同行,不再踩坑。
A. 内存溢出: 刚开始采用 480x480,3 的数据, 直接显卡内存不够 (out of memory )。 解决方法:调成 240x240,1
B. 训练时间过长: 48000 个数据,1轮学习 需要 4个小时左右, 如果整个 30轮, 那还不疯掉,需要等个4,5天才知道结果。
解决办法:
1). 降低数据维度 480->240->120->28 ,
2). 放大卷积核 3x3 ->5x5->7x7 , 从文件读取 --- > 一次读入内存再训练
C. 梯度不下降: 这个是做深度学习最要命的问题。
解决办法:
1. 变更模型,调超参数;
2.图像变换(裁剪成核心数据图片), 图像反色, 图像归1(0~1)
最后效率和结果: 45000 个图片。 图像缩小到 28x28。 20分钟左右,跑完一次训练/预测。
遗留问题:
图像缩小是否会影响判断的准确率?这个问题需要在细化求精的过程中,反复试验验证了。
准确率是否能提高,我相信肯定能提高。 ( 我会在最后开源代码和数据,有兴趣的朋友可以用更牛x的网络模型,提升准确率。如能提高希望能在blog留言 )
[用途,意义]
1. 机器可以根据人的前期指导, 学会判别走势形态。有别于传统的数值分类统计的判别。判别的结果是一个可能性,比如80%,而传统的为1,0.
2. 可以根据我上述论文的原理进行特定模型学习。 参考建议: 把特征进行二分类, 包含有你特征的图片定义为1, 其它图形为0; 进行训练学习。以此得到模型识别器
3. 对于量化交易系统行业是一次革命性的提升, 因为它具有更强的泛化性。 它的使用可以使程序开发人员和策略开发人员 一定的程度的分开。 策略师不再依靠程序员一个思路一个思路编写一个程序(指标)。 着一点对于 大智慧/通达信 提供神经网络机构版,是一个相当不错的思路。 机构策略开发变成了,不断选取入场点。 (还有一个在期货交易上也有貌似不错的点子)
[总结]
深度神经网络(卷积神经 CNN) 在量化交易里的模式(图形)识别效果较好。 相信不久的将来, 深度神经网络的相关技术会不断进入金融工程(量化交易)
这个领域。
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
代码:
导入相关库
# -*- coding: UTF-8 -*-
print(__doc__)
'''
author : hylas
date:2017/8/19
discp: 用cnn给证券的行情进行分类, 未来用来识别当天的行情或者检测某个特殊的特征模型
'''
import sys
import os
import time
from keras.utils import np_utils
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout
import numpy as np
import PIL.Image as Image
import keras
from keras.layers import Conv2D, MaxPooling2D
from keras.optimizers import SGD
from keras.models import load_model
from keras.layers import Dense, Dropout, Flatten
from keras.utils import np_utils
pngRootPath ='/home/hylas/dev/data/min5_png/'
imgWidth =480
imgHeitht =480
nWidth = 28
nHeight = 28
nCannle = 1
input_dim = (nWidth, nHeight, nCannle )
# 卷积层中使用的卷积核的个数
nb_filters = 32
# 卷积核的大小
kernel_size = (3, 3)
# 池化层操作的范围
pool_size = (2, 2)
nEpochs = 20
batch_size = 32
samples_per_epoch= 48000
#samples_per_epoch= 9600
网络模型
# 类似VGG的卷积神经网络: Conv2D --> Conv2D --> MaxPooling2D --> Conv2D --> Conv2D --> MaxPooling2D
# --> Flatten -->Dense(256) -->Dense(10)
def BuildMode_VGG():
print 'input_dim:', input_dim
model = Sequential()
model.add(Conv2D(nb_filters , kernel_size, activation='relu', input_shape= input_dim ))
model.add(Conv2D(nb_filters , kernel_size, activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D( nb_filters*2 , kernel_size, activation='relu'))
model.add(Conv2D( nb_filters*2 , kernel_size, activation='relu'))
model.add(MaxPooling2D(pool_size= pool_size ))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(5, activation='softmax'))
print model.summary()
#return
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd)
return model
训练神经网络及测试神经网络
def do2_fit_mem():
t = time.time()
#X,y = generate2mem( 'png_file_list.csv', samples_per_epoch)
X, y = loaddatafromdisk()
print type(X), type(y)
print X.shape , y.shape
print 'time:' , time.time() - t
model = BuildMode_VGG()
#print generate_arrays_from_file('png_file_list.csv', batch_size )
model.fit( X,y, batch_size, nb_epoch= nEpochs, verbose=1 , validation_split=0.10 )
model.save('stock_vgg2_'+ time.strftime('vgg2_%Y-%m-%d-%X', time.localtime()) +'.h5')
x_test=X[:1000]
y_test=y[:1000]
x_test, y_test = loadtestdatafromdisk()
testModle(model, x_test, y_test, batch_size= batch_size )
其它代码:
def loaddatafromdisk():
data = np.loadtxt('data_table_' + str(samples_per_epoch) + '_x.txt' )
print 'from:', data.shape
data = data.reshape( (samples_per_epoch, 28,28,1) )
print 'to:', data.shape
y = np.loadtxt('data_table_' + str(samples_per_epoch) + '_y.txt' )
return data,y
def loadtestdatafromdisk():
data = np.loadtxt('data_table_test_x.txt' )
print 'from:', data.shape
data = data.reshape( (1000, 28,28,1) )
print 'to:', data.shape
y = np.loadtxt('data_table_test_y.txt' )
return data,y
def testModle(model, x_test ,y_test, batch_size= 32 ):
y_pret= model.predict(x_test , batch_size= batch_size )
y_pret[0] = y_pret[0] / y_pret[0].max()
y_pret[0][(y_pret[0] != y_pret[0].max() ) ] = 0
print y_pret[0]
y_pret_ex = y_pret.copy()
for i in range(0, len( y_pret ) ):
y_pret_ex[i] = y_pret_ex[i] / y_pret_ex[i].max()
y_pret_ex[i][(y_pret_ex[i] != y_pret_ex[i].max())] = 0
print '------------------------------------'
#print y_pret_ex[:10]
#print y_pret[:10]
test_accuracy = np.mean(np.equal(y_test, y_pret_ex))
print("accuarcy:", test_accuracy)
def test():
do2_fit_mem()
pass
if __name__ == "__main__":
sys_code_type = sys.getfilesystemencoding()
test()
代码补充说明:
代码文件: 一份为最终整理代码, 一份包含调测过程,图片处理可做参考。
相关截图:
网络模型参数
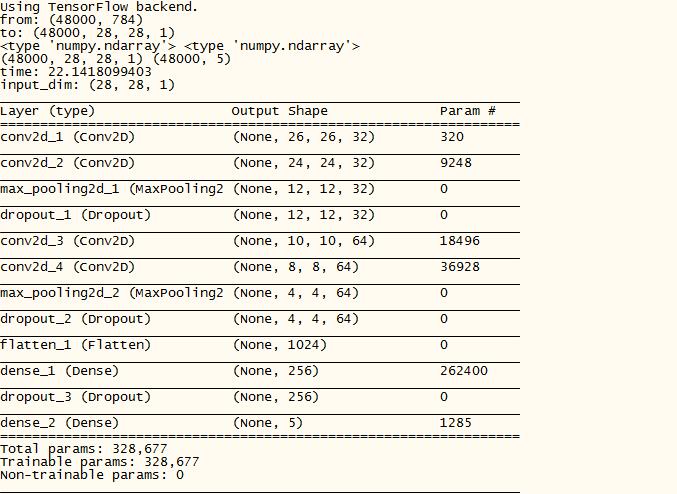
训练过程
预测分类成绩:
数据下载:
下载 http://pan.baidu.com/s/1mifxQNu
个人群: 杭州程序化交易群 375129936