一、前言
Spring Cloud Sleuth 主要功能就是在分布式系统中提供追踪解决方案 ,并且兼容了zipkin,提供了REST API接口来辅助我们查询跟踪数据以实现对分布式系统的监控程序 。
Sleuth 是个组件,没有提供我们可视化的界面,和一些相信的api信息,而zipkin 是个系统,他有可视化的界面,和对应接口调用详细的信息情况。
二、为什么要使用链路追踪
微服务架构上通过业务来划分服务的,通过REST调用,对外暴露的一个接口,可能需要很多个服务协同才能完成这个接口功能,如果链路上任何一个服务出现问题或者网络超时,都会形成导致接口调用失败。随着业务的不断扩张,服务之间互相调用会越来越复杂。
,对调用链的分析会越来越复杂。如果那里出现了错误,我们是很排查的。所以我们引入了链路追踪,使用可视化的界面我们可以很容易的找到那一块耗时多,等等。
Sleuth 的使用:
1.在项目中加入依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
2.然后在你想打印日志的地方输入
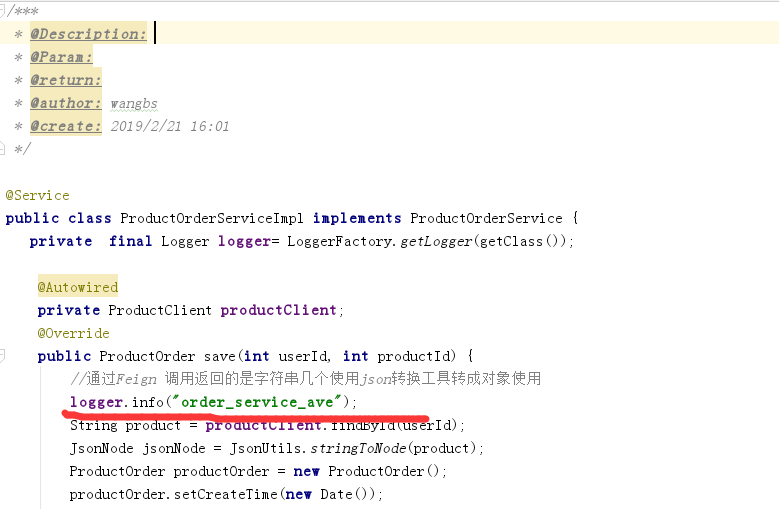
控制台会出现下面这个 (现在看起来是不是感觉使用起来也不怎方便,下面我会讲zipkin,他提供了可视化界面,看的就清楚多了。)
[order-service,96f95a0dd81fe3ab,852ef4cfcdecabf3,false]
1、第一个值,spring.application.name的值
2、第二个值,96f95a0dd81fe3ab ,sleuth生成的一个ID,叫Trace ID,用来标识一条请求链路,一条请求链路中包含一个Trace ID,多个Span ID
3、第三个值,852ef4cfcdecabf3、spanid 基本的工作单元,获取元数据,如发送一个http
4、第四个值:false,是否要将该信息输出到zipkin服务中来收集和展示。
3、可视化链路追踪系统Zipkin
大规模分布式系统的APM工具(Application Performance Management),基于Google Dapper的基础实现,和sleuth结合可以提供可视化web界面分析调用链路耗时情况
3.1 可视化链路追踪系统Zipkin部署。(我使用的是docker 我后面会讲下docker的部署,很简单的)
//阿里提供的部署Zipkin的方法,里面讲了好几种 包括java 部署 和docker 部署
docker部署:
docker run -d -p 9411:9411 openzipkin/zipkin
这样就搞定了 ,然后ip+端口就能访问:
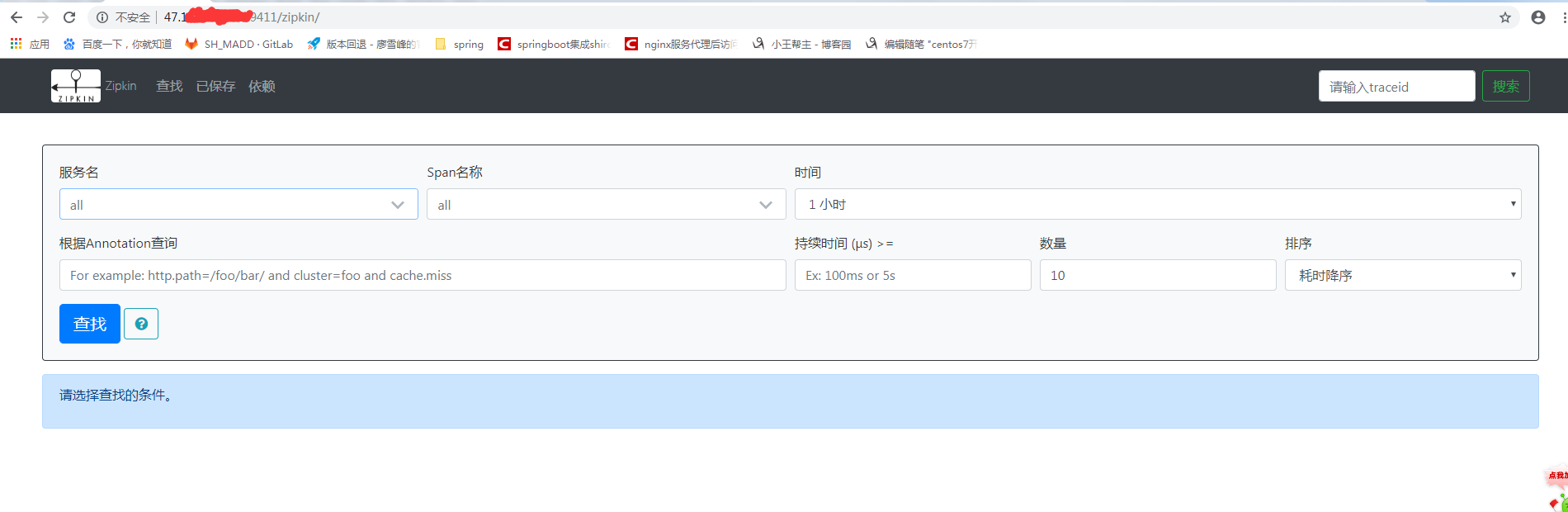
3.2 代码中的使用。
那个项目想要链路追踪就都加入下面的两个配置
3.1.1 加入依赖
<!--里面包含 spring-cloud-starter-sleuth、spring-cloud-sleuth-zipkin ->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
3.1.1 配置文件添加
#服务的名称
spring:
application:
name: order-service
#zipkin服务所在地址
zipkin:
base-url: http://47.XX.XX.XX:9411/
#配置采样百分比,开发环境可以设置为1,表示全部,生产就用默认(0.1)
sleuth:
sampler:
probability: 1
3.2 测试
调用 api 接口

查看Zipkin 可视化系统
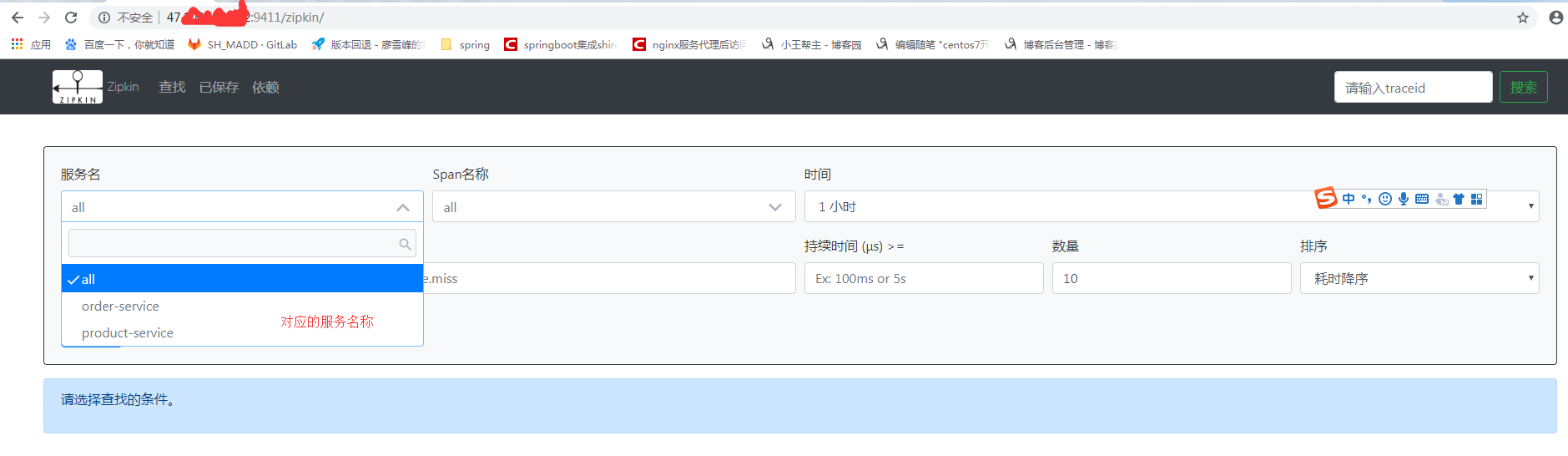
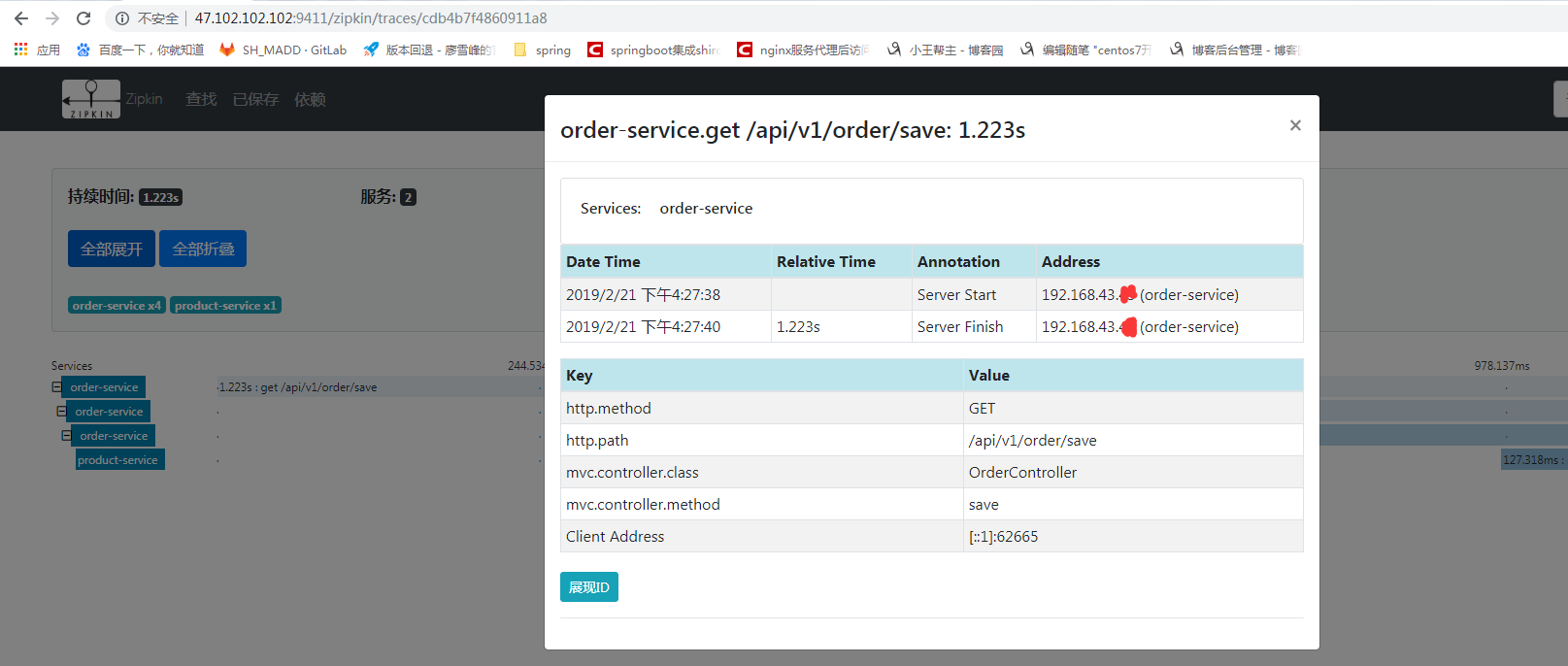
这样详细信息就全部追踪到了。
3.4 大致说下 Sleuth 和Zipkin 是怎么调用的.
sleuth收集跟踪信息通过http请求发送给zipkin server,zipkinserver进行跟踪信息的存储以及提供Rest API即可,Zipkin UI调用其API接口进行数据展示
默认存储是内存,可也用mysql、或者elasticsearch等存储。 所以说,Sleuth 才是根本,而Zipkin 这是进行了对数据的分析和展示。