一、视图
1.啥是视图?
视图就是通过查询得到的一张虚拟表,然后保存下来,直接使用即可
2.为啥要用视图呢?
如果要频繁使用一张虚拟表,可以不用重复查询
3.如何用视图
创建:
create view teacher_courus as
select * from teacher inner join course on teacher.tid = course.teacher_id;
删除:
drop view teacher_course;
强调
1.在硬盘中,视图只有表结构文件,没有表数据文件
2.视图通常是用于查询,尽量不要修改视图中的数据
ps:开发过程中一般不会去使用视图
二、触发器
在满足对某张表数据的增、删、改的情况下,自动触发的功能称之为触发器。
1.为何要用触发器?
触发器专门针对我们对某一张表数据增insert、删delete、改updata的行为,这类行为一旦执行,就会触发触发器的执行,即自动运行另外一段sql代码
2.创建触发器语法(六种)
create trigger 触发器名字 after/before insert/update/delete on 表名 for each row
begin
sql 语句
end
增前/后 2种
删前/后 2种
改前/后 2种
可以修改MySQL默认的结束符( ; )
delimiter $$ # 只对当前窗口有效
create trigger tri_before_insert_user before insert on user for each row
begin
select * from user;
end $$
delimiter ;


# 往cmd添加数据,如果success enum为no,则向errlog添加数据 CREATE TABLE cmd ( id INT PRIMARY KEY auto_increment, USER CHAR (32), priv CHAR (10), cmd CHAR (64), sub_time datetime, #提交时间 success enum ('yes', 'no') #0代表执行失败 ); CREATE TABLE errlog ( id INT PRIMARY KEY auto_increment, err_cmd CHAR (64), err_time datetime ); #补充:NEW对象指代的就是当前记录 #触发器语法 delimiter $$ create trigger tri_after_insert_cmd after insert on cmd for each row begin if NEW.success = 'no' then insert into errlog(err_cmd,err_time) values(NEW.cmd,NEW.sub_time); end if; end $$ delimiter ;
三、事务 (同步完成几件事)
事务包含一大堆sql语句,这些sql要么同事成功,要么一个也别想成功
1.事务四大特性:ACID
A :原子性
一个事务是不可分割的工作单位,事务中包括的诸操作要么都做,要么都不做。
C :一致性
事务必须是使数据库从一个一致性状态变到另一个一致性状态,一致性与原子性密切相关。
I :隔离性
一个事务的执行不能被其他事务干扰。
D:持久性
一个事物一旦提交成功,他对数据库中数据改变是永久性的。
2.开启事务:start transaction
事务滚回:rollback
永久性更改:commit
create table user( id int primary key auto_increment, name char(32), balance int ); insert into user(name,balance) values ('wsb',1000), ('egon',1000), ('ysb',1000); # 修改数据之前先开启事务操作 start transaction; # 修改操作 update user set balance=900 where name='wsb'; #买支付100元 update user set balance=1010 where name='egon'; #中介拿走10元 update user set balance=1090 where name='ysb'; #卖家拿到90元 # 回滚到上一个状态 rollback; # 开启事务之后,只要没有执行commit操作,数据其实都没有真正刷新到硬盘 commit; """开启事务检测操作是否完整,不完整主动回滚到上一个状态,如果完整就应该执行commit操作"""
四、存储过程
类似于python中的自定义函数
内部封装了操作数据库的sql语句,后续想要实现相应的操作,只需要调用存储过程即可
1.语法结构
delimiter $$
create procedure p1(
in m int, # 不能被返回出去
in n int,
out res int, # 可以被返回
inout xxx int, # 既可以进又可以出
)
begin
select * from user
end $$
delimiter ;
delimiter $$ create procedure p1( in m int, # in表示这个参数必须只能是传入不能被返回出去 in n int, out res int # out表示这个参数可以被返回出去,还有一个inout表示即可以传入也可以被返回出去 ) begin select tname from teacher where tid > m and tid < n; set res=0; # 就类似于是一个标志位 用来标识存储器是否执行成功 end $$ delimiter ; ''' set @res = 10 # 设置一个变量与值的绑定关系 调用存储过程 将变量@res传入 之后通过 select @res 查看存储过程执行完成后的返回结果 '''
2.存储过程在哪个库下面定义,就只能在哪个库下面使用
delimiter // create PROCEDURE p5( OUT p_return_code tinyint ) BEGIN DECLARE exit handler for sqlexception BEGIN -- ERROR set p_return_code = 1; rollback; END; DECLARE exit handler for sqlwarning BEGIN -- WARNING set p_return_code = 2; rollback; END; START TRANSACTION; update user set balance=900 where id =1; update user123 set balance=1010 where id = 2; update user set balance=1090 where id =3; COMMIT; -- SUCCESS set p_return_code = 0; #0代表执行成功 END // delimiter ;
3.如何使用
# 1、直接在mysql中调用 set @res=10 # res的值是用来判断存储过程是否被执行成功的依据,所以需要先定义一个变量@res存储10 call p1(2,4,10); # 报错 call p1(2,4,@res); # 查看结果 select @res; # 执行成功,@res变量值发生了变化 # 2、在python程序中调用 pymysql链接mysql 产生的游表cursor.callproc('p1',(2,4,10)) # 内部原理:@_p1_0=2,@_p1_1=4,@_p1_2=10; cursor.excute('select @_p1_2;') # 3、存储过程与事务使用举例(了解) delimiter // create PROCEDURE p5( OUT p_return_code tinyint ) BEGIN DECLARE exit handler for sqlexception BEGIN -- ERROR set p_return_code = 1; rollback; END; DECLARE exit handler for sqlwarning BEGIN -- WARNING set p_return_code = 2; rollback; END; START TRANSACTION; update user set balance=900 where id =1; update user123 set balance=1010 where id = 2; update user set balance=1090 where id =3; COMMIT; -- SUCCESS set p_return_code = 0; #0代表执行成功 END // delimiter ;
五、函数
注意与存储过程的区别,mysql内置的函数只能在sql语句中使用
CREATE TABLE blog ( id INT PRIMARY KEY auto_increment, NAME CHAR (32), sub_time datetime ); INSERT INTO blog (NAME, sub_time) VALUES ('第1篇','2015-03-01 11:31:21'), ('第2篇','2015-03-11 16:31:21'), ('第3篇','2016-07-01 10:21:31'), ('第4篇','2016-07-22 09:23:21'), ('第5篇','2016-07-23 10:11:11'), ('第6篇','2016-07-25 11:21:31'), ('第7篇','2017-03-01 15:33:21'), ('第8篇','2017-03-01 17:32:21'), ('第9篇','2017-03-01 18:31:21'); select date_format(sub_time,'%Y-%m'),count(id) from blog group by date_format(sub_time,'%Y-%m');
六、流程控制
delimiter // CREATE PROCEDURE proc_if () BEGIN declare i int default 0; if i = 1 THEN SELECT 1; ELSEIF i = 2 THEN SELECT 2; ELSE SELECT 7; END IF; END // delimiter ;
delimiter // CREATE PROCEDURE proc_while () BEGIN DECLARE num INT ; SET num = 0 ; WHILE num < 10 DO SELECT num ; SET num = num + 1 ; END WHILE ; END // delimiter ;
七、索引与慢查询优化
数据存储在硬盘上,查询数据不可避免的需要进行IO操作
1.索引在mysql中也叫作 ‘键‘ ,是存储引擎用于快速找到记录的一中数据结构
● primary key
● unique key
● index key 无约束功能,只帮忙加速查询
ps:foreign key 不是用来加速查询,
2.索引的影响
在表中有大量数据的前提下,创建索引速度会很慢
在索引创建完毕后,对表的查询性能会大幅度提升,但写的性能会降低
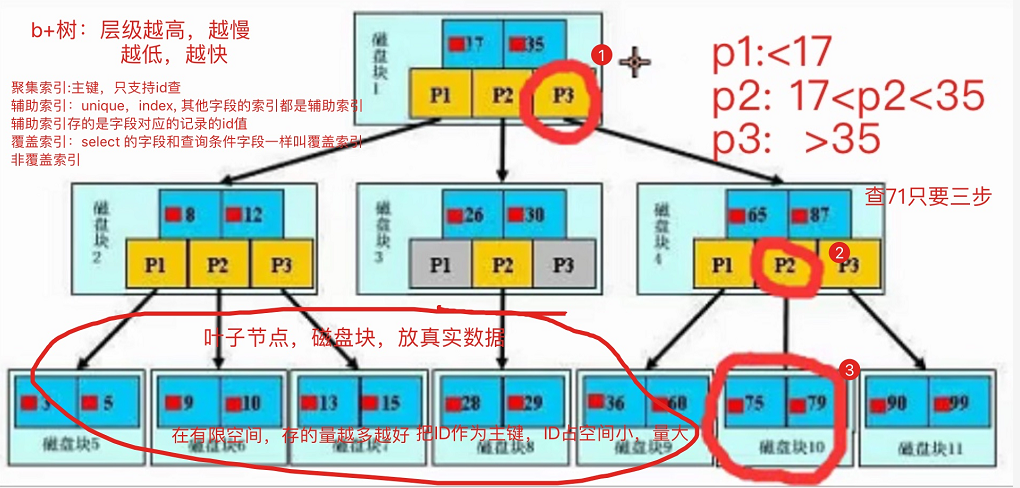
3.b+树
3.1只有叶子节点存放真是数据,根和树枝节点存放的仅仅是虚拟数据
3.2查询次数有树的层级决定,层级越低次数越少
3.3一个磁盘大小是一定,以为存放数据量是一定,所以我们一般用主键id字段建立索引,可以降低树的层级高度
4.聚焦索引(primary key)
用表的主键建立索引
辅助索引(unique、index)
查询数据不可能都用id作为筛选条件,用其他字段建立索引,就叫辅助索引