二叉树定义
二叉树 (Binary Tree) 是 n(n ≥ 0) 个结点的有限集合,该集合为空集时称为空二叉树,由一个根结点和两棵互不相交的、分别称为根结点的左子树和右子树的二叉树组成。
二叉树种类
- 满二叉树
- 完全二叉树
- 二叉搜索树
- 平衡AVL树
- 红黑树也属于AVL树
满二叉树
满二叉树:一棵树深度为k,节点数量为2^k-1的树是满二叉树。
满二叉树的特征
所有内部节点都有两个子节点,最底一层是叶子节点。
如果一颗树深度为h,最大层数为k,且深度与最大层数相同,即k=h;
第k层的结点数是:2^(k-1)
总结点数是:2^k-1 (2的k次方减一)
总节点数一定是奇数。
树高:h=log2(n+1)
完全二叉树
若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h 层所有的结点都连续集中在最左边,这就是完全二叉树。

完全二叉树的特征
完全二叉树的叶结点只能存在于最下两层,其中最下层的叶结点只集中在树结构的左侧,而倒数第二层的叶结点集中于树结构的右侧。当结点的度为 1 时,该结点只能拥有左子树。
深度为k的完全二叉树,至少有2^(k-1)个节点,至多有2^k-1个节点。
满二叉树一定是完全二叉树,完全二叉树不一定是满二叉树。
树高h=log2n + 1
二叉查找/搜索/排序树-BST
二叉搜索树的特征
- 左子树上所有结点的值均小于等于它的根结点的值
- 右子树上所有结点的值均大于等于它的根结点的值
二叉搜索树的优缺点
优点:查找速度快,二叉查找树比普通树查找更快,查找、插入、删除的时间复杂度为O(logN)。
缺点:出现平衡问题(二叉搜索树在经过多次插入与删除后,会出现线性结构。)
平衡二叉树(AVL树)
平衡二叉树全称平衡二叉搜索树,也叫AVL树,是一种自平衡的树,从上面二叉搜索树升级过来的,重点是改进了平衡问题。
平衡二叉树的特征
- AVL树也规定了左结点小于根节点,右结点大于根节点。
- 并且还规定了左子树和右子树的高度差不得超过1,这样保证了它不会成为线性的链表。
AVL树怎么解决平衡
主要就是通过左旋和右旋来解决。
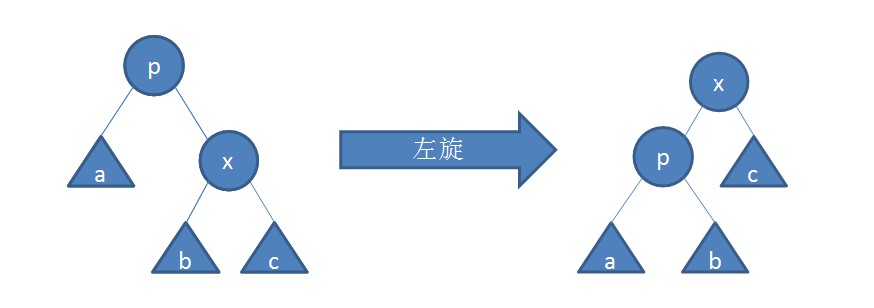
1.左旋
旋转前,x是p的右儿子。
x的左儿子(若存在)变为p的右儿子,p变为x的左儿子。如下图
2.右旋
旋转前,x是p的左儿子。
x的右儿子(若存在)变为p的左儿子,p变为x的右儿子。如下图

综上总结:
是左旋还是右旋的判断,我们可以通过检查选择前x是p的左儿子还是右儿子来判断该次旋转是左旋还是右旋。
旋转的方式,也就是把父节点旋转到旋转点的子节点,然后把旋转点多余的子节点给父节点。
左旋——自己变为右孩子的左孩子;右旋——自己变为左孩子的右孩子;
二叉树的性质
| 性质 | 内容 |
|---|---|
| 性质一 | 在二叉树的 i 层上至多有 2i-1 个结点(i>=1) |
| 性质二 | 深度为 k 的二叉树至多有 2k-1 个结点(i>=1) |
| 性质三 | 对任何一棵二叉树 T,如果其终端结点树为 n0,度为 2 的结点为 n2,则 n0 = n2 + n1 |
| 性质四 | 具有 n 个结点的完全二叉树的深度为 [log2n] + 1 向下取整 |
| 性质五 | 如果有一棵有 n 个结点的完全二叉树(其深度为 [log2n] + 1,向下取整)的结点按层次序编号(从第 1 层到第 [log2n] + 1,向下取整层,每层从左到右),则对任一结点 i(1 <= i <= n)有 1.如果 i = 1,则结点 i 是二叉树的根,无双亲;如果 i > 1,则其双亲是结点 [i / 2],向下取整 2.如果 2i > n 则结点 i 无左孩子,否则其左孩子是结点 2i 3.如果 2i + 1 > n 则结点无右孩子,否则其右孩子是结点 2i + 1 |
二叉树的存储结构
顺序存储
由于二叉树的结点至多为 2,因此这种性质使得二叉树可以使用顺序存储结构来描述,在使用顺序存储结构时我们需要令数组的下标体现结点之间的逻辑关系。我们先来看完全二叉树,如果我们按照从上到下,从左到右的顺序遍历完全二叉树时,顺序是这样的:
那么我们就会发现,设父结点的序号为 k,则子结点的序号会分别为 2k 和 2k + 1,子结点的序号和父结点都是相互对应的,因此我们可以用顺序存储结构来描述。
那么对于一般的二叉树呢?我们可以利用完全二叉树的编号来实现,如果在完全二叉树对应的结点是空结点,修改其值为 NULL 即可,例如:
再看个例子,左斜树:
但是我们可以很明显地看到,对于一个斜树,我开辟的空间数远超过实际使用的空间,这样空间就被浪费了,因此顺序存储结构虽然可行,但不合适。
链式存储
由于二叉树的每个结点最多只能有 2 个子树,所以我们可以直接设置一个结点具有两个指针和一个数据域。例如:
public class TreeNode { public int val; public TreeNode left; public TreeNode right; public TreeNode() { } public TreeNode(int val) { this.val = val; } public TreeNode(int val, TreeNode left, TreeNode right) { this.val = val; this.left = left; this.right = right; } }
上述的例子:
可以表示为:
二叉树的遍历
遍历算法
纵向遍历
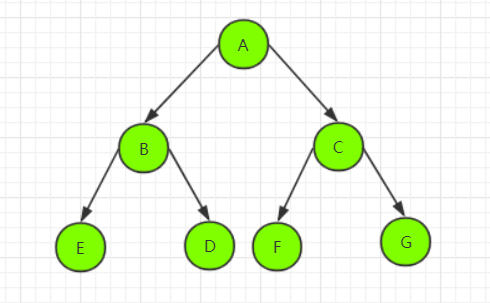
前序遍历(根左右):先访问根结点,然后先进入左子树前序遍历,再进入右子树前序遍历。
结果:ABDGECF
递归写法:
public static void preorderTraversalRecursion(TreeNode root) { if (root != null) { System.out.println(root.val); preorderTraversalRecursion(root.left); preorderTraversalRecursion(root.right); } }
迭代写法(系统栈):
public static void preorderTraversalIteration(TreeNode root) { Stack<TreeNode> stack = new Stack<>(); if (root != null) { stack.push(root); while (!stack.isEmpty()) { TreeNode node = stack.pop(); System.out.println(node.val); if (node.right != null) { stack.push(node.right); } if (node.left != null) { stack.push(node.left); } } } }
迭代写法:
public static void preOrderMorris(TreeNode node) { TreeNode cur1 = node; TreeNode cur2 = null; while (cur1 != null) { cur2 = cur1.left; if (cur2 != null) { while (cur2.right != null && cur2.right != cur1) { cur2 = cur2.right; } if (cur2.right == null) { cur2.right = cur1; System.out.println(cur1.val); cur1 = cur1.left; continue; } else { cur2.right = null; } } else { System.out.println(cur1.val); } cur1 = cur1.right; } }
中序遍历(左根右):从根结点出发,先进入根结点的左子树中序遍历,然后访问根结点,最后进入右子树中序遍历。

结果:DGBEACF
递归写法:
public static void midOrderTraversalRecursion(TreeNode node) { if (node != null) { midOrderTraversalRecursion(node.left); System.out.println(node.val); midOrderTraversalRecursion(node.right); } }
迭代写法(系统栈):
public static void midOrderTraversalIteration(TreeNode node) { Stack<TreeNode> stack = new Stack<>(); TreeNode curr = node; while (!stack.isEmpty() || curr != null) {//1 5 3 7 while (curr != null) { //1 2 4 stack.push(curr);// 7 curr = curr.left; //6 } TreeNode temp = stack.pop();//4 2 5 1 6 3 7 System.out.println(temp.val);//4 2 5 1 6 3 if (temp.right != null) { //5 3 7 curr = temp.right; //5 3 7 } } }
迭代写法:
public static void midOrderMorris(TreeNode node) { TreeNode cur1 = node; TreeNode cur2 = null; while (cur1 != null) { //1 2 4 2 5 cur2 = cur1.left;//2 4 null 4 if (cur2 != null) { while (cur2.right != null && cur2.right != cur1) { cur2 = cur2.right; } if (cur2.right == null) {//5 2 cur2.right = cur1; //System.out.println(cur1.val); cur1 = cur1.left; continue; } else { cur2.right = null; } } System.out.println(cur1.val); cur1 = cur1.right;//2 5 5 } }
后序遍历(左右根):从左到右先叶子后结点的方式进入左、右子树遍历,最后访问根结点。
结果:GDEBFCA
递归写法:
public static void preorderTraversalRecursion(TreeNode root) { if (root != null) { preorderTraversalRecursion(root.left); preorderTraversalRecursion(root.right); System.out.println(root.val); } }
迭代写法(系统栈):
public static void preorderTraversalIteration(TreeNode root) { Stack<TreeNode> stack = new Stack<>(); if (root == null) { return; } stack.push(root); TreeNode temp = root; while (!stack.isEmpty()) { TreeNode node = stack.peek(); if (node.left != null && node.left != temp && node.right != temp) { stack.push(node.left); } else if (node.right != null && node.right != temp) { stack.push(node.right); } else { System.out.print(stack.pop().val + " "); temp = node; } } }
迭代写法:
public static void postOrderMorris(TreeNode head) { if (head == null) { return; } TreeNode cur1 = head;//遍历树的指针变量 TreeNode cur2 = null;//当前子树的最右节点 while (cur1 != null) { cur2 = cur1.left; if (cur2 != null) { while (cur2.right != null && cur2.right != cur1) { cur2 = cur2.right; } if (cur2.right == null) { cur2.right = cur1; cur1 = cur1.left; continue; } else { cur2.right = null; postMorrisPrint(cur1.left); } } cur1 = cur1.right; } postMorrisPrint(head); } //打印函数 public static void postMorrisPrint(TreeNode head) { TreeNode reverseList = postMorrisReverseList(head); TreeNode cur = reverseList; while (cur != null) { System.out.print(cur.val + " "); cur = cur.right; } postMorrisReverseList(reverseList); } //翻转单链表 public static TreeNode postMorrisReverseList(TreeNode head) { TreeNode cur = head; TreeNode pre = null; while (cur != null) { TreeNode next = cur.right; cur.right = pre; pre = cur; cur = next; } return pre; }
无论是什么样的遍历顺序,访问结点都是从根结点开始访问,按照从上到下,从左到右的顺序向下挖掘,分为 3 种顺序主要是因为我们需要有一些方式来描述递归遍历的结果,让我们可以抽象二叉树的结构,因此我们就按照输出语句放的位置不同而决定是什么序遍历。无论前中后遍历,每个节点的遍历如果访问有孩子的节点,先处理孩子的(逻辑是一样的)。
横向遍历
层序遍历:从第一层(根结点)开始,按照从上到下,从左到右的顺序进行遍历,利用队列实现,如图所示。
结果:ABCDEFG
代码实现:
public List<List<Integer>> levelOrder(TreeNode root) { List<List<Integer>> lists = new ArrayList<>(); if (root == null) { return lists; } Queue<TreeNode> queue = new ArrayDeque<>(); queue.add(root); while (!queue.isEmpty()) { List<Integer> list = new ArrayList<>(); int size = queue.size(); for (int i = 0; i < size; i++) { TreeNode node = queue.poll(); list.add(node.val); if (node.left != null) { queue.add(node.left); } if (node.right != null) { queue.add(node.right); } } lists.add(list); } return lists; }
二叉树的创建
上面说过二叉树的存储结构有两种,一种是数组形式,一种是结点形式。结点方式属于静态创建树,现在我们来动态创建树。
动态创建二叉树分两种情况,一种情况是给出一个数组,将数组转换成一个二叉树。另外一种情况是给出两个数组,将两个数组转换成一个二叉树。两个数组分别是先序和中序遍历的结果,或者是中序和后序的遍历结果。通过先序和中序或者中序和后序我们可以还原出原始的二叉树,但是通过先序和后序是无法还原出原始的二叉树的。
一个数组建树
一个数组建的树必须是二叉搜索树。他的特点上面已经说明了,当前根节点的左边全部比根节点小,当前根节点的右边全部比根节点大。
假设我有一个数组:int[] arrays = {3, 2, 1, 4, 5};
那么创建二叉树的步骤是这样的:
- 首先将3作为根节点
- 随后2进来了,我们跟3做比较,比3小,那么放在3的左边
- 随后1进来了,我们跟3做比较,比3小,那么放在3的左边,此时3的左边有2了,因此跟2比,比2小,放在2的左边
- 随后4进来了,我们跟3做比较,比3大,那么放在3的右边
- 随后5进来了,我们跟3做比较,比3大,那么放在3的右边,此时3的右边有4了,因此跟4比,比4大,放在4的右边
那么我们的二叉查找树就建立成功了,无论任何一颗子树,左边都比根要小,右边比根要大
代码实现:
public TreeNode createTree(int[] arrays) { TreeNode node = new TreeNode(null); for (int value : arrays) { create(node, value); } return node; } public void create(TreeNode treeNode, int value) { if (treeNode.val == null) { treeNode.val = value; return; } TreeNode temp = treeNode; while (temp != null) { //当前值大于根值,往右边走 if (value > temp.val) { //右边没有树根,那就直接插入 if (temp.right == null) { temp.right = new TreeNode(value); return; } else { //如果右边有树根,到右边的树根去 temp = temp.right; } } else { //左没有树根,那就直接插入 if (temp.left == null) { temp.left = new TreeNode(value); return; } else { //如果左有树根,到左边的树根去 temp = temp.left; } } } }
已知前序、中序遍历建树法
假设我有如下遍历序列:
ABDFGHIEC //前序遍历
FDHGIBEAC //中序遍历
我们来尝试一下用这两个遍历结果反向建立一棵二叉树。首先根据前序遍历的特点,对于一棵树来说,在前序遍历时根结点会被先输出,在中序遍历时根结点会在左子树结点输出完毕之后输出,因此我们可以知道这棵二叉树的根结点的值为 “A”,而在中序遍历中“A”结点又把序列分为了左右子树,分别是“FDHGIBE”和“C”,如图所示。
我的根结点安排明白了,这个时候在我眼里,前序遍历只剩下了“BDFGHIEC”,而对于左子树的中序遍历是“FDHGIBE”,右子树的中序遍历是“C”。
对于二叉树来说,可以看做由两颗子树构成的森林重新组合的树结构,因此在我眼里根据前序遍历的结构,左子树的根结点是“B”,该结点把二叉树分成了左右子树分别是“FDHGI”和“E”,如图所示。
重复上述切片操作,就能够建立一棵二叉树。

代码实现:
Map<Integer, Integer> inMap = new HashMap(); public TreeNode buildTreePre(int[] preorder, int[] inorder) { int length = preorder.length; for (int i = 0; i < inorder.length; i++) { inMap.put(inorder[i], i); } return buildPre(preorder, inorder, 0, length - 1, 0, length - 1); } public TreeNode buildPre(int[] preorder, int[] inorder, int preorder_begin, int preorder_end, int inorder_begin, int inorder_end) { if (preorder_begin > preorder_end) { return null; } int mid = preorder[preorder_begin]; int root_index = inMap.get(mid); int length = root_index - inorder_begin; TreeNode root = new TreeNode(mid); root.left = buildPre(preorder, inorder, preorder_begin + 1, preorder_begin + length, inorder_begin, root_index - 1); root.right = buildPre(preorder, inorder, preorder_begin + length + 1, preorder_end, root_index + 1, inorder_end); return root; }
已知后序、中序遍历建树法
假设我有如下遍历序列:
2 3 1 5 7 6 4 //后序遍历
1 2 3 4 5 6 7 //中序遍历
后续遍历的最后一个元素是根结点,因此通过根结点“4”在中序序列分成了左、右子树。对于后续遍历也被分为两个序列“2 3 1”和“5 7 6”。
对于左子树来说,根据后序遍历“2 3 1”,他的根结点是“1”,这个结点将中序序列分成了左右子树,分别为右子树“2 3”和一个空左树。
重复上述操作即可还原出二叉树。

代码实现:
Map<Integer, Integer> inMap = new HashMap(); public TreeNode buildTreeAfter(int[] preorder, int[] inorder) { int length = preorder.length; for (int i = 0; i < inorder.length; i++) { inMap.put(inorder[i], i); } return buildAfter(preorder, inorder, 0, length - 1, 0, length - 1); } public TreeNode buildAfter(int[] postorder, int[] inorder, int postorder_begin, int postorder_end, int inorder_begin, int inorder_end) { if (postorder_begin > postorder_end) { return null; } int mid = postorder[postorder_end]; int root_index = inMap.get(mid); int length = inorder_end - root_index; TreeNode root = new TreeNode(mid); root.left = buildAfter(postorder, inorder, postorder_begin, postorder_end - 1 - length, inorder_begin, root_index - 1); root.right = buildAfter(postorder, inorder, postorder_end - length, postorder_end - 1, root_index + 1, inorder_end); return root; }