今天分享Python使用Chromedriver+Selenium爬虫的的方法,Chromedriver是一个有意思的爬虫插件,这个插件的爬虫方式主要是完全模拟浏览器点击页面,一步一步去找你要的东西,就跟个机器一样,不停的去执行命令。主要用于爬一些网站的反爬虫做的很好,自己又很想爬去里面的数据,那就可以用这个插件,
1. Selenium的安装
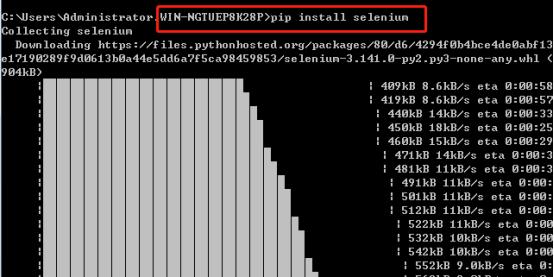
Selenium安装直接采用pip安装最为简便,即打开cmd,输入pip install selenium 安装成功如下:

2. Chromedriver安装
Chromedriver下载前需要先下载了google浏览器
Chromedriver下载地址:http://chromedriver.storage.googleapis.com/index.html
Chromedriver版本对应支持的Chrome版本如下表:
|
chromedriver版本 |
支持的Chrome版本 |
|
v2.43 |
v69-71 |
|
v2.42 |
v68-70 |
|
v2.41 |
v67-69 |
|
v2.40 |
v66-68 |
|
v2.39 |
v66-68 |
|
v2.38 |
v65-67 |
|
v2.37 |
v64-66 |
|
v2.36 |
v63-65 |
|
v2.35 |
v62-64 |
|
v2.34 |
v61-63 |
|
v2.33 |
v60-62 |
|
v2.32 |
v59-61 |
|
v2.31 |
v58-60 |
|
v2.30 |
v58-60 |
|
v2.29 |
v56-58 |
|
v2.28 |
v55-57 |
|
v2.27 |
v54-56 |
|
v2.26 |
v53-55 |
|
v2.25 |
v53-55 |
|
v2.24 |
v52-54 |
|
v2.23 |
v51-53 |
|
v2.22 |
v49-52 |
|
v2.21 |
v46-50 |
|
v2.20 |
v43-48 |
|
v2.19 |
v43-47 |
|
v2.18 |
v43-46 |
|
v2.17 |
v42-43 |
|
v2.13 |
v42-45 |
|
v2.15 |
v40-43 |
|
v2.14 |
v39-42 |
|
v2.13 |
v38-41 |
|
v2.12 |
v36-40 |
|
v2.11 |
v36-40 |
|
v2.10 |
v33-36 |
|
v2.9 |
v31-34 |
|
v2.8 |
v30-33 |
|
v2.7 |
v30-33 |
|
v2.6 |
v29-32 |
|
v2.5 |
v29-32 |
|
v2.4 |
v29-32 |
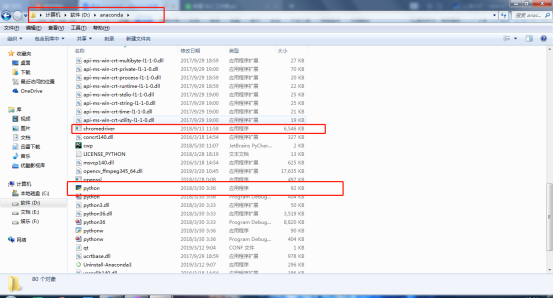
注意:解压好的Chromedriver需放在Python的安装路径下。我的Python路径在D:anaconda中,以我的为例:
3. 测试
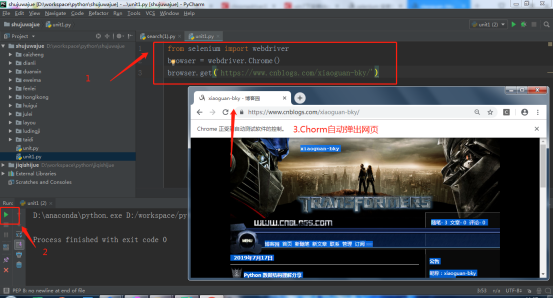
用一段Python代码检测Chromedriver+Selenium安装是否成功。在Pycharm编辑以下Python代码,运行下面代码,会自动打开浏览器,然后访问网页。

注意:建议运行代码时关闭360,金山等软件。