用PHP是如何做图片防盗链的
1、图片防盗链
在一些大型网站中,比如百度贴吧,该站点的图片采用了防盗链的规则,以至于使用下面代码会发生错误。
简单代码:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<title></title>
<link rel="stylesheet" href="">
</head>
<body>
<!--引用一张百度贴吧的图片-->
<img src="http://imgsrc.baidu.com/forum/pic/item/03a4462309f79052204229be04f3d7ca7acbd5d5.jpg"/>
</body>
</html>
出现的问题:
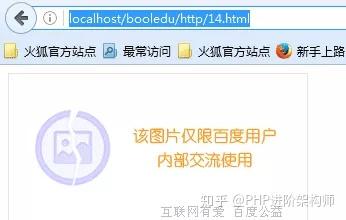
出错的原因
主要是该站点的图片采用了防盗链的规则,其实这个规则也比较简单, 和大家一说就知道啦,主要是该站点在得知有请求时,会先判断请求头中的信息,如果请求头中有Referer信息,然后根据自己的规则来判断Referer头信息是否符合要求,Referer 信息是请求该图片的来源地址。
浏览器中的请求头信息:
(1)正常使用百度贴吧查看图片的请求头信息

(2)我的代码的头信息
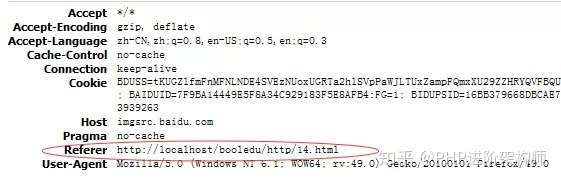
相信读者看到这,也就明白了,为什么我的代码不能访问到图片,而是显示一张警告盗链图片,因为我们的Referer头信息和百度贴吧的不同,当我的请求发出去时,该站点查看Referer头信息,一看来源不是本站,就重定向到另外一张图片了。
给自己的站点配置图片防盗链:
(1)在web服务器中开启mod_rewrite模块
#LoadModule rewrite_module modules/mod_rewrite.so,//将前面的#给去掉,然后重新启动服务器
(2)在需要防盗的网站或目录中,写.htaccess文件,并指定防盗链规则
步骤:
新建一个.htaccess文件,在windows中使用另存为的方式来新建此文件
查找手册,在.htaccess文件中利用正则判断
指定规则:
如果是图片资源且referer头信息是来自于本站,则通过
重写规则如下:
假定我的服务器是localhost,规则的意思是,如果请求的是图片资源,但是请求来源不是本站的话,就重定向到当前目录的一张no.png的图片上
RewriteEngine On
RewriteCond %{SCRIPT_FILENAME} .*.(jpg|jpeg|png|gif) [NC]
RewriteCond %{HTTP_REFERER} !localhost [NC]
RewriteRule .* no.png
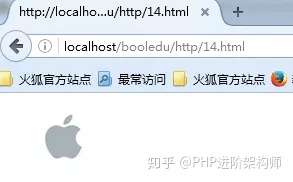
来自localhost的访问:
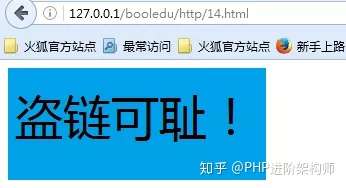
来自于其他站点的访问:
至此,关于防盗链的知识我们学完了,但是不急,既然是一个请求头,当然是可以伪造的,下面我们来说一下反防盗链的规则。
2、反防盗链
上面我的服务器配置了图片防盗链,现在以它来讲解反防盗链,如果我们在采集图片的时候,遇到使用防盗链技术的站点,我们可以在采集图片的时候伪造一个Referer头信息。
下面的代码是从一个配置了图片防盗链的站点下载一张图片。
<?php
/**
* 下载图片
* @author webbc
*/
require './Http.class.php';//这个类是我自己封装的一个用于HTTp请求的类
$http = new Http("http://localhost/booledu/http/apple.jpg");
//$http->setHeader('Referer:http://tieba.baidu.com/');//设置referer头
$res = $http->get();
$content = strstr($res,"
");
file_put_contents('./toutupian.jpg',substr($content,4));
echo "ok";
?>不加Referer头信息下载的结果:

加Referer头信息下载的结果:

相应大家看到这,应该能看出来如何反防盗链吧,其实就是加上一个Referer头信息,那么,每个站点的Referer头信息从哪里找呢?这个应该抓包分析就可以得出来了!