古今地名映射
爬取来源
从百度百科调用它的搜索接口:检索两个内容,一个是它的现地名,另一个是它的简介,从简介中在进行词性分析找出对应的地名
代码
import urllib.request
import urllib.parse
from lxml import etree
from pyhanlp import *
import pandas as pd
def query(content):
# 请求地址
url = 'https://baike.baidu.com/item/' + urllib.parse.quote(content)
print(url)
# 请求头部
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# 利用请求地址和请求头部构造请求对象
req = urllib.request.Request(url=url, headers=headers, method='GET')
# 发送请求,获得响应
response = urllib.request.urlopen(req)
# 读取响应,获得文本
text = response.read().decode('utf-8')
# 构造 _Element 对象
html = etree.HTML(text)
# 使用 xpath 匹配数据,得到匹配字符串列表
#'/html/body/div[3]/div[2]/div/div[1]/div[7]/dl[2]/dd[5]/a'
#sen_list = html.xpath('//div[contains(@class,"lemma-summary") or contains(@class,"lemmaWgt-lemmaSummary")]//text()')
f=False
sen_list=html.xpath('/html/body/div[3]/div[2]/div/div[1]/dl[1]/dd/h2//text()')
if sen_list==[]:
sen_list = html.xpath(
'//div[contains(@class,"lemma-summary") or contains(@class,"lemmaWgt-lemmaSummary")]//text()')
if sen_list!=[]:
# 过滤数据,去掉空白
sen_list_after_filter = [item.strip('\n') for item in sen_list]
# 将字符串列表连成字符串并返回
text=''.join(sen_list_after_filter)
CRFnewSegment = HanLP.newSegment("crf")
term_list = CRFnewSegment.seg(text)
ci=['ns']
where_list=[]
for it in term_list:
if str(it.nature) in ci:
where_list.append(str(it.word))
if len(where_list)>0:
print(where_list)
return where_list[0]
else:
return "无"
else:
return "无"
from xlrd import open_workbook
from xlutils.copy import copy
#将分类结果重新写入原excel中
def write_to(data,file):
print(len(data))
xl =open_workbook(file)
excel = copy(xl)
sheet1 = excel.get_sheet(0)
sheet1.write(0, 1, "jin_where")
for i in range(0, len(data)):
sheet1.write(i + 1, 1, data[i])
excel.save(file)
if __name__ == '__main__':
jin_list=[]
data=pd.read_excel('gu_where.xlsx')
gu_where=data.gu_where
for i in range(len(gu_where)):
content=gu_where[i]
print(content)
result = query(content)
print("查询结果:%s" % result)
jin_list.append(result)
write_to(jin_list,'gu_where.xlsx')
结果

现今地点经纬度
首先对古代地点进行经纬度获取,获取后保存获得的现金地名
若古代地名获取不到经纬度,用现今地名进行获取经纬度,同样保存获得的现金地名和经纬度
在进行高德地图经纬度调用的时候要注意一次不能太多:500个地名经纬度能容忍(别问我是如何知道的!!!惨痛的实践)
import pandas as pd
import requests
import json
def coords(city):
# 输入API问号前固定不变的部分
url = 'https://restapi.amap.com/v3/geocode/geo'
# 将两个参数放入字典
params = {'key': 'cd0c1ab60e3a22a87009a4196abd94e0',
'address': city}
res = requests.get(url, params)
jd = json.loads(res.text)
if len(jd['geocodes']) != 0:
print(jd)
coords = jd['geocodes'][0]['location']
address=jd['geocodes'][0]['formatted_address']
print(address)
return coords,address
else:
return '无','无'
if __name__ == '__main__':
data=pd.read_excel('gu_where.xlsx')
gu_name=list(data.gu_where)
jin_name=list(data.jin_where)
ans_gu=[]
ans_jin=[]
#经度与纬度
lng=[]
lat=[]
for i in range(6500,len(gu_name)):
gu=gu_name[i]
jin=jin_name[i]
loca, address = coords(gu)
if loca != '无':
ans_gu.append(gu)
ans_jin.append(address)
loca_list=loca.split(',')
lng.append(loca_list[0])
lat.append(loca_list[1])
print(gu+" "+address+" "+str(loca_list[0])+" "+str(loca_list[1]))
else:
loca,address=coords(jin)
if loca!='无':
ans_gu.append(gu)
ans_jin.append(address)
loca_list = loca.split(',')
lng.append(loca_list[0])
lat.append(loca_list[1])
print(gu+" "+address+" "+str(loca_list[0])+" "+str(loca_list[1]))
import xlwt
xl = xlwt.Workbook()
# 调用对象的add_sheet方法
sheet1 = xl.add_sheet('sheet1', cell_overwrite_ok=True)
sheet1.write(0, 0, "gu_name")
sheet1.write(0,1,"jin_name")
sheet1.write(0,2,"lng")
sheet1.write(0,3,"lat")
for i in range(0, len(ans_jin)):
sheet1.write(i + 1, 0, ans_gu[i])
sheet1.write(i + 1, 1, ans_jin[i])
sheet1.write(i + 1, 2, lng[i])
sheet1.write(i + 1, 3, lat[i])
xl.save("gu_jin_lng_lat2.xlsx")
清洗后数据
在获得经纬度的地名进行相应的保存

部分实体导入
诗人与朝代实体
import pandas as pd
import numpy as np
import re
from py2neo import Node,Relationship,Graph,NodeMatcher,RelationshipMatcher
# 创建节点
def CreateNode(m_graph,m_label,m_attrs):
m_n="_.name="+"\'"+m_attrs['name']+"\'"
matcher = NodeMatcher(m_graph)
re_value = matcher.match(m_label).where(m_n).first()
#print(re_value)
if re_value is None:
m_mode = Node(m_label,**m_attrs)
n = graph.create(m_mode)
return n
return None
# 查询节点
def MatchNode(m_graph,m_label,m_attrs):
m_n="_.name="+"\'"+m_attrs['name']+"\'"
matcher = NodeMatcher(m_graph)
re_value = matcher.match(m_label).where(m_n).first()
return re_value
# 创建关系
def CreateRelationship(m_graph,m_label1,m_attrs1,m_label2,m_attrs2,m_r_name):
reValue1 = MatchNode(m_graph,m_label1,m_attrs1)
reValue2 = MatchNode(m_graph,m_label2,m_attrs2)
if reValue1 is None or reValue2 is None:
return False
m_r = Relationship(reValue1,m_r_name,reValue2)
n = graph.create(m_r)
return n
#查找关系
def findRelationship(m_graph,m_label1,m_attrs1,m_label2,m_attrs2,m_r_name):
reValue1 = MatchNode(m_graph, m_label1, m_attrs1)
reValue2 = MatchNode(m_graph, m_label2, m_attrs2)
if reValue1 is None or reValue2 is None:
return False
m_r = Relationship(reValue1, m_r_name['name'], reValue2)
return m_r
def updateRelation(m_graph,m_label1,m_attrs1,m_label2,m_attrs2,m_r_name):
reValue1 = MatchNode(m_graph, m_label1, m_attrs1)
reValue2 = MatchNode(m_graph, m_label2, m_attrs2)
if reValue1 is None or reValue2 is None:
return False
print(m_r_name)
propertyes={'value': m_r_name['value'], 'danwei': m_r_name['danwei']}
m_r = Relationship(reValue1, m_r_name['name'], reValue2,**propertyes)
graph.merge(m_r)
#修改节点属性
def updateNode(m_graph,m_label1,m_attrs1,new_attrs):
reValue1 = MatchNode(m_graph, m_label1, m_attrs1)
if reValue1 is None:
return False
reValue1.update(new_attrs)
graph.push(reValue1)
graph = Graph('http://localhost:7474',username='neo4j',password='fengge666')
def create_author():
file='./data2/author.xlsx'
data=pd.read_excel(file).fillna("无")
author=list(data.author)
produce=list(data.produce)
num=list(data.num)
src=list(data.src)
desty=list(data.desty)
bg_time=list(data.begin_time)
ed_time=list(data.end_time)
zi_list=list(data.zi)
hao_list=list(data.hao)
author_label='author'
desty_label='desty'
for i in range(len(author)):
print("第"+str(i)+"个")
attr1 = {"name": author[i], "produce": produce[i], "num": num[i],
"src": src[i],"bg_time":bg_time[i],"ed_time":ed_time[i],"zi":zi_list[i],"hao":hao_list[i]}
CreateNode(graph, author_label, attr1)
print("创建诗人:" + author[i] + "成功!!")
attr2={"name":desty[i]}
if MatchNode(graph,desty_label,attr2)==None:
CreateNode(graph,desty_label,attr2)
print("创建朝代:"+desty[i]+"成功!!")
#创建关系
m_r_name1 = "朝代"
reValue1 = CreateRelationship(graph, author_label, attr1, desty_label, attr2, m_r_name1)
print("创建关系:"+author[i]+"-所属朝代-"+desty[i]+"成功")
m_r_name2 = "包含"
reValue2 = CreateRelationship(graph,desty_label, attr2, author_label, attr1, m_r_name2)
print("创建关系:" + desty[i] + "-包含-" + author[i] + "成功")
if __name__ == '__main__':
create_author()
导入效果

牌名
包含词牌名,曲牌名
import pandas as pd
import numpy as np
import re
from py2neo import Node,Relationship,Graph,NodeMatcher,RelationshipMatcher
# 创建节点
def CreateNode(m_graph,m_label,m_attrs):
m_n="_.name="+"\'"+m_attrs['name']+"\'"
matcher = NodeMatcher(m_graph)
re_value = matcher.match(m_label).where(m_n).first()
#print(re_value)
if re_value is None:
m_mode = Node(m_label,**m_attrs)
n = graph.create(m_mode)
return n
return None
# 查询节点
def MatchNode(m_graph,m_label,m_attrs):
m_n="_.name="+"\'"+m_attrs['name']+"\'"
matcher = NodeMatcher(m_graph)
re_value = matcher.match(m_label).where(m_n).first()
return re_value
# 创建关系
def CreateRelationship(m_graph,m_label1,m_attrs1,m_label2,m_attrs2,m_r_name):
reValue1 = MatchNode(m_graph,m_label1,m_attrs1)
reValue2 = MatchNode(m_graph,m_label2,m_attrs2)
if reValue1 is None or reValue2 is None:
return False
m_r = Relationship(reValue1,m_r_name,reValue2)
n = graph.create(m_r)
return n
#查找关系
def findRelationship(m_graph,m_label1,m_attrs1,m_label2,m_attrs2,m_r_name):
reValue1 = MatchNode(m_graph, m_label1, m_attrs1)
reValue2 = MatchNode(m_graph, m_label2, m_attrs2)
if reValue1 is None or reValue2 is None:
return False
m_r = Relationship(reValue1, m_r_name['name'], reValue2)
return m_r
def updateRelation(m_graph,m_label1,m_attrs1,m_label2,m_attrs2,m_r_name):
reValue1 = MatchNode(m_graph, m_label1, m_attrs1)
reValue2 = MatchNode(m_graph, m_label2, m_attrs2)
if reValue1 is None or reValue2 is None:
return False
print(m_r_name)
propertyes={'value': m_r_name['value'], 'danwei': m_r_name['danwei']}
m_r = Relationship(reValue1, m_r_name['name'], reValue2,**propertyes)
graph.merge(m_r)
#修改节点属性
def updateNode(m_graph,m_label1,m_attrs1,new_attrs):
reValue1 = MatchNode(m_graph, m_label1, m_attrs1)
if reValue1 is None:
return False
reValue1.update(new_attrs)
graph.push(reValue1)
graph = Graph('http://localhost:7474',username='neo4j',password='fengge666')
def create_pai_name():
file = './data2/cipai_name.xlsx'
data = pd.read_excel(file).fillna("无")
title=list(data.title)
cipai_label="ci_pai"
for it in title:
attr1={"name":it}
CreateNode(graph, cipai_label, attr1)
print("创建词牌名"+it+"成功!!")
file2 = './data2/qupai_name.xlsx'
data2 = pd.read_excel(file2).fillna("无")
title2 = list(data2.qu_name)
qupai_label = "qu_pai"
for it in title2:
attr1 = {"name": it}
CreateNode(graph, qupai_label, attr1)
print("创建曲牌名" + it + "成功!!")
if __name__ == '__main__':
create_pai_name()
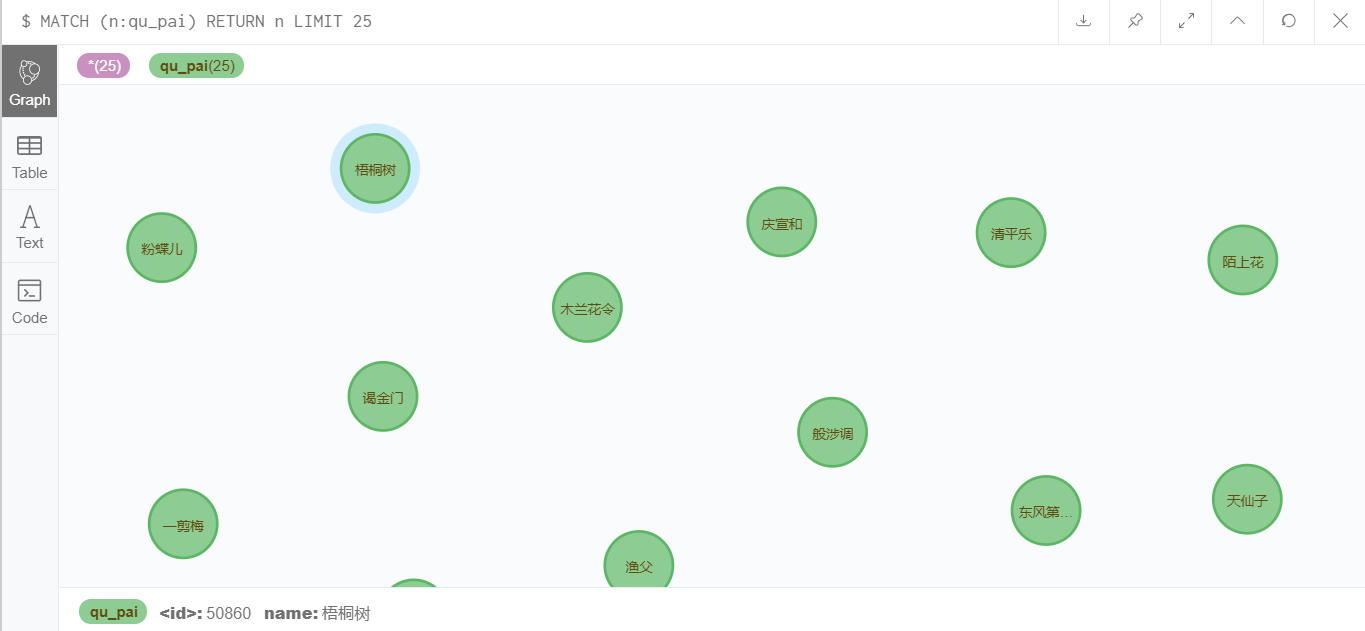
导入效果

曲牌名:
飞花令
import pandas as pd
import numpy as np
import re
from py2neo import Node,Relationship,Graph,NodeMatcher,RelationshipMatcher
# 创建节点
def CreateNode(m_graph,m_label,m_attrs):
m_n="_.name="+"\'"+m_attrs['name']+"\'"
matcher = NodeMatcher(m_graph)
re_value = matcher.match(m_label).where(m_n).first()
#print(re_value)
if re_value is None:
m_mode = Node(m_label,**m_attrs)
n = graph.create(m_mode)
return n
return None
# 查询节点
def MatchNode(m_graph,m_label,m_attrs):
m_n="_.name="+"\'"+m_attrs['name']+"\'"
matcher = NodeMatcher(m_graph)
re_value = matcher.match(m_label).where(m_n).first()
return re_value
# 创建关系
def CreateRelationship(m_graph,m_label1,m_attrs1,m_label2,m_attrs2,m_r_name):
reValue1 = MatchNode(m_graph,m_label1,m_attrs1)
reValue2 = MatchNode(m_graph,m_label2,m_attrs2)
if reValue1 is None or reValue2 is None:
return False
m_r = Relationship(reValue1,m_r_name,reValue2)
n = graph.create(m_r)
return n
#查找关系
def findRelationship(m_graph,m_label1,m_attrs1,m_label2,m_attrs2,m_r_name):
reValue1 = MatchNode(m_graph, m_label1, m_attrs1)
reValue2 = MatchNode(m_graph, m_label2, m_attrs2)
if reValue1 is None or reValue2 is None:
return False
m_r = Relationship(reValue1, m_r_name['name'], reValue2)
return m_r
def updateRelation(m_graph,m_label1,m_attrs1,m_label2,m_attrs2,m_r_name):
reValue1 = MatchNode(m_graph, m_label1, m_attrs1)
reValue2 = MatchNode(m_graph, m_label2, m_attrs2)
if reValue1 is None or reValue2 is None:
return False
print(m_r_name)
propertyes={'value': m_r_name['value'], 'danwei': m_r_name['danwei']}
m_r = Relationship(reValue1, m_r_name['name'], reValue2,**propertyes)
graph.merge(m_r)
#修改节点属性
def updateNode(m_graph,m_label1,m_attrs1,new_attrs):
reValue1 = MatchNode(m_graph, m_label1, m_attrs1)
if reValue1 is None:
return False
reValue1.update(new_attrs)
graph.push(reValue1)
graph = Graph('http://localhost:7474',username='neo4j',password='fengge666')
def create_word():
file = './data2/word.xlsx'
data = pd.read_excel(file).fillna("无")
word=list(data.word)
word_label="word"
for it in word:
attr1={"name":it}
CreateNode(graph, word_label, attr1)
print("创建飞花令:"+it+"成功!!")
if __name__ == '__main__':
create_word()
导入效果
