RDD
RDD 是什么
定义
RDD, 全称为 Resilient Distributed Datasets, 是一个容错的, 并行的数据结构, 可以让用户显式地将数据存储到磁盘和内存中, 并能控制数据的分区.
同时, RDD 还提供了一组丰富的操作来操作这些数据. 在这些操作中, 诸如 map, flatMap, filter 等转换操作实现了 Monad 模式, 很好地契合了 Scala 的集合操作. 除此之外, RDD 还提供了诸如 join, groupBy, reduceByKey 等更为方便的操作, 以支持常见的数据运算.
特点
-
RDD 是一个编程模型
-
RDD 允许用户显式的指定数据存放在内存或者磁盘
-
RDD 是分布式的, 用户可以控制 RDD 的分区
-
-
RDD 是一个编程模型
-
RDD 提供了丰富的操作
-
RDD 提供了 map, flatMap, filter 等操作符, 用以实现 Monad 模式
-
RDD 提供了 reduceByKey, groupByKey 等操作符, 用以操作 Key-Value 型数据
-
RDD 提供了 max, min, mean 等操作符, 用以操作数字型的数据
-
-
RDD 是混合型的编程模型, 可以支持迭代计算, 关系查询, MapReduce, 流计算
-
RDD 是只读的
-
RDD 之间有依赖关系, 根据执行操作的操作符的不同, 依赖关系可以分为宽依赖和窄依赖
创建 RDD
简略的说, RDD 有三种创建方式
-
RDD 可以通过本地集合直接创建
-
RDD 也可以通过读取外部数据集来创建
-
RDD 也可以通过其它的 RDD 衍生而来
通过本地集合直接创建 RDD
//从本地集合创建
@Test
def rddCreationLocal(): Unit ={
val seq=Seq(1,2,3)
val rdd1: RDD[Int] = sc.parallelize(seq, 2)
//区别在于,parallelize不需要指定分区个数,makeRDD需要指定分区个数
val rdd2: RDD[Int] = sc.makeRDD(seq, 2)
}
通过读取外部文件创建 RDD
//从文件创建
@Test
def rddCreationHDFS(): Unit ={
sc.textFile("hdfs://hadoop101:8020/data/wordcount.txt")
// 1.textFile传入的是什么
// 传入的是路径,读取路径
// * hdfs://hadoop101:8020/../.. file:///... 一个是读hdfs,一个是读本地
// 2. 是否支持分区
// 如果传入的是hdfs,分区是由HDFS文件中block决定的
// 3.支持什么平台
// aws和阿里云
}
通过其它的 RDD 衍生新的 RDD
//从RDD衍生
@Test
def rddCreateFromRDD(): Unit ={
val rdd1 = sc.parallelize(Seq(1, 2, 3))
// 通过在rdd上执行算子操作,会生成新的 rdd
// 原地计算
// str.substr 返回新的字符串,非原地计算
// 和字符串中的方式很像,字符串是可变的吗?
// RDD可变吗》不可变
val rdd2 = rdd1.map(item => item)
}
RDD 算子
Map 算子
@Test
def mapTest(): Unit ={
//1.创建RDD
val rdd1=sc.parallelize(Seq(1,2,3))
//2.执行map操作
val rdd2=rdd1.map(item =>item*10)
//3.得到结果
val result=rdd2.collect()
result.foreach(item=>println(item))
}
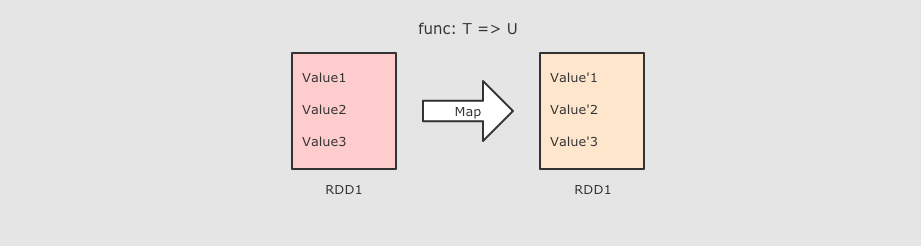
作用
把 RDD 中的数据 一对一 的转为另一种形式,Map是一对一
FlatMap 算子
@Test
def flatMapTest(): Unit ={
//1.创建RDD
val rdd1=sc.parallelize(Seq("Hello lily","Hello lucy","Hello tim"))
//2.处理数据
val rdd2: RDD[String] = rdd1.flatMap(item => item.split(" "))
//3.得到结果
val result=rdd2.collect()
result.foreach(item=>println(item))
//4.关闭sc
sc.stop()
}

作用
FlatMap 算子和 Map 算子类似, 但是 FlatMap 是一对多,flatMap 其实是两个操作, 是 map + flatten, 也就是先转换, 后把转换而来的 List 展开
ReduceByKey 算子
@Test
def reduceByKeyTest(): Unit ={
//1.创建RDD
val rdd1=sc.parallelize(Seq("Hello lily","Hello lucy","Hello tim"))
//2.处理数据
val rdd2=rdd1.flatMap(item => item.split(" "))
.map(item=>(item,1))
.reduceByKey((curr,agg) => curr+agg)
//3.得到结果
val result=rdd2.collect()
result.foreach(item=>println(item))
//4.关闭sc
sc.stop()
}
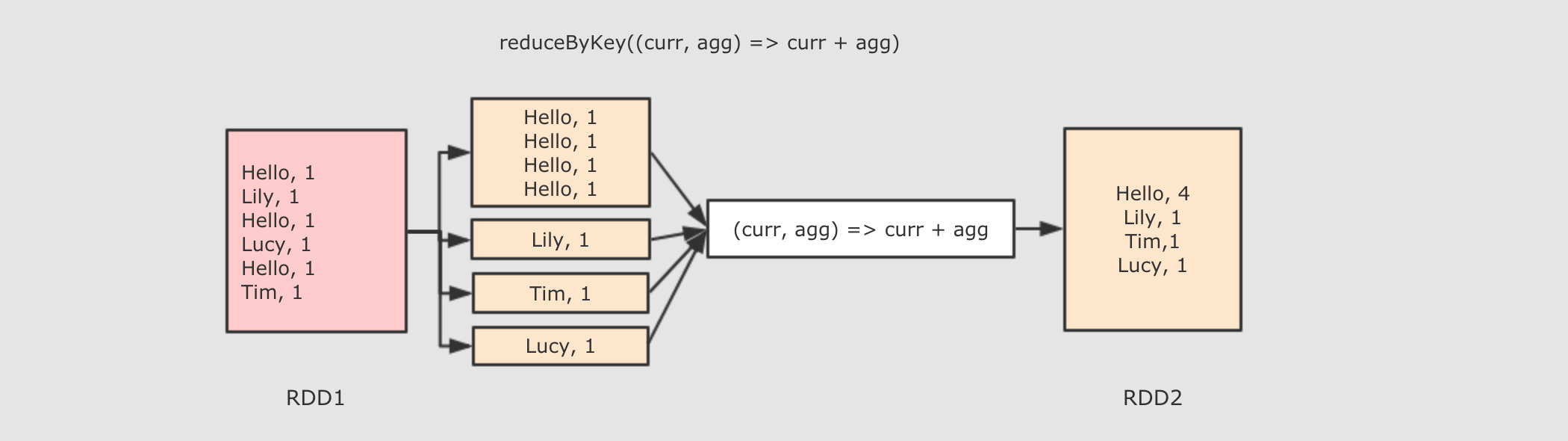

作用
首先按照 Key 分组, 接下来把整组的 Value 计算出一个聚合值, 这个操作非常类似于 MapReduce 中的 Reduce
参数
func → 执行数据处理的函数, 传入两个参数, 一个是当前值, 一个是局部汇总, 这个函数需要有一个输出, 输出就是这个 Key 的汇总结果,并进行更新
注意点
-
ReduceByKey 只能作用于 Key-Value 型数据, Key-Value 型数据在当前语境中特指 Tuple2
-
ReduceByKey 是一个需要 Shuffled 的操作
-
和其它的 Shuffled 相比, ReduceByKey是高效的, 因为类似 MapReduce 的, 在 Map 端有一个 Cominer, 这样 I/O 的数据便会减少
-
map 和 flatMap 算子都是转换, 只是 flatMap 在转换过后会再执行展开, 所以 map 是一对一, flatMap 是一对多
-
reduceByKey 类似 MapReduce 中的 Reduce