一、前言
上一篇说了一下查询和存储机制,接下来我们主要来说一下排序、聚合、分页;
写完文章以后发现之前文章没有介绍Coordinating Node,这个地方补充说明下Coordinating Node(协调节点):搜索请求或索引请求可能涉及保存在不同数据节点上的数据。例如,搜索请求在两个阶段中执行,当客户端请求到节点上这个阶段的时候,协调节点将请求转发到保存数据的数据节点。每个数据节点在分片执行请求并将其结果返回给协调节点。当节点返回到客端这个阶段的时候,协调节点将每个数据节点的结果减少为单个节点的所有数据的结果集。这意味着每个节点具有全部三个node.master,node.data并node.ingest这个属性,当node.ingest设置为false仅作为协调节点,不能被禁用。
二、排序
ES默认使用相关性算分来排序,如果想改变排序规则可以使用sort:
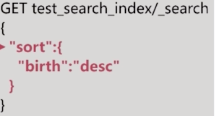
也可以指定多个排序条件:

排序的过程是指是对字段原始内容排序的过程,在排序的过程中使用的正排索引,是通过文档的id和字段进行排序的;Elasticsearch针对这种情况提供两种实现方式:fielddata和doc_value;
fielddata
fielddata的数据结构,其实根据倒排索引反向出来的一个正排索引,即document到term的映射。只要我们针对需要分词的字段设置了fielddata,就可以使用该字段进行聚合,排序等。我们设置为true之后,在索引期间,就会以列式存储在内存中。为什么存在于内存呢,因为按照term聚合,需要执行更加复杂的算法和操作,如果基于磁盘或者 OS 缓存,性能会比较差。用法如下:

fielddata加载到内存中有几种情况,默认是懒加载。即对一个分词的字段执行聚合或者排序的时候,加载到内存。所以他不是在索引创建期间创建的,而是查询在期间创建的。
fielddata在内存中加载的这样就会出现一个问题,数据量很大的情况容易发生OOM,这种时候我们该如何控制OOM的情况发生?
1.内存限制
indices.fielddata.cache.size: 20% 默认是无限制,限制内存使用以后频繁的导致内存回收,容易照成GC和IO损耗。
2.断路器(circuit breaker)
如果查询一次的fielddata超过总内存,就会发生内存溢出,circuit breaker会估算query要加载的fielddata大小,如果超出总内存,就短路,query直接失败;
indices.breaker.fielddata.limit:fielddata的内存限制,默认60%
indices.breaker.request.limit:执行聚合的内存限制,默认40%
indices.breaker.total.limit:综合上面两个,限制在70%以内
3.频率(frequency)
加载fielddata的时候,也是按照segment去进行加载的,所以可以通过限制segment文档出现的频率去限制加载的数目;
min :0.01 只是加载至少1%的doc文档中出现过的term对应的文档;
min_segment_size: 500 少于500 文档数的segment不加载fielddata;
fielddata加载方式:
1.lazy
这个在查询的放入到内存中,上面已经介绍过;
2.eager(预加载)
当一个新的segment形成的时候,就加载到内存中,查询的时候遇到这个segment直接查询出去就可以;
3.eager_global_ordinals(全局序号加载)
构建一个全局的Hash,新出现的文档加入Hash,文档中用序号代替字符,这样会减少内存的消耗,但是每次要是有segment新增或者删除时候回导致全局序号重建的问题;
doc_value
fielddata对内存要求比较高,如果数据量很大的话对内存是一个很大的考验。所以Elasticsearch又给我们提供了另外的策略doc_value,doc_value使用磁盘存储,与fielddata结构完全是一样的,在倒排索引基础上反向出来的正排索引,并且是预先构建,即在建倒排索引的时候,就会创建doc values。,这会消耗额外的存储空间,但是对于JVM的内存需求就会减少。总体来看,dov_valus只是比fielddata慢一点,大概10-25%,则带来了更多的稳定性。
类型是string的字段,生成分词字段(text)和不分词字段(keyword),不分词字段即使用keyword,所以我们在聚合的时候,可以直接使用field.keyword进行聚合,而这种默认就是使用doc_values,建立正排索引。不分词的字段,默认建立doc_values,即字段类型为keyword,他不会创建分词,就会默认建立doc_value,如果我们不想该字段参与聚合排序,我们可以设置doc_values=false,避免不必要的磁盘空间浪费。但是这个只能在索引映射的时候做,即索引映射建好之后不能修改。
两者对比:

三、分页
有3种类型的分页,如下图:
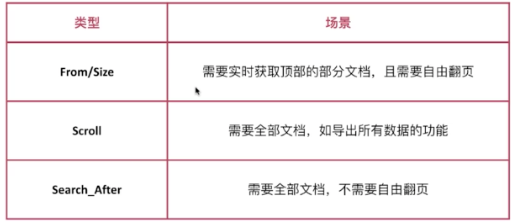
1.from/size
form开始的位置,size获取的数量;

数据在分片存储的情况下怎么查询前1000个文档?
在每个分片上都先获取1000个文档,然后再由Coordinating Node聚合所有分片的结果后再排序选取前1000个文档,页数越多,处理文档就越多,占用内存越多,耗时越长。数据分别存放在不同的分片上,必须一个去查询;为了避免深度分页,Elasticsearch通过index.max_result_window限定显示条数,默认是10000;

2.scroll
scroll按照快照的方式来查询数据,可以避免深度分页的问题,因为是快照所以不能用来做实时搜索,数据不是实时的,接下来说一下scroll流程:
首先发起scroll查询请求,Elasticsearch在接收到请求以后会根据查询条件查询文档i,1m表示该快照保留1分钟;

接下来查询的时候根据上一次返回的快照id继续查询,不断的迭代调用直到返回hits.hits数组为空时停止

过多的scroll调用会占用大量的内存,可以通过删除的clear api进行删除:
删除某个:

删除多个:

删除所有:

3.search after
避免深度分页的性能问题,提供实时的下一页文档获取功能,通过提供实时游标来解决此问题,接下来我们来解释下这个问题:
第一次查询:这个地方必须保证排序的值是唯一的

第二步: 使用上一步最后一个文档的sort值进行查询
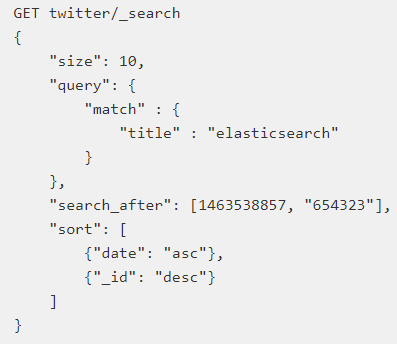
通过保证排序字段唯一,我们实现类似数据库游标功能的效果;
四、聚合分析
Aggregation,是Elasticsearch除搜索功能外提供的针对Elasticsearch数据做统计分析的功能,聚合的实时性很高,都是及时返回,另外还提供多种分析方式,接下来我们看下聚合的4种分析方式:
Metric
在一组文档中计算平均值、最大值、最小值、求和等等;
Avg(平均值)


Min最小值


Sum求和(过滤查询中的结果查询出帽子的价格的总和)


Percentile计算从聚合文档中提取的数值的一个或多个百分位数;
解释下下面这个例子,网站响应时间做的一个分析,单位是毫秒,5毫秒响应占总响应时间的1%;


Cardinality计算不同值的近似计数,类似数据库的distinct count


当然除了上面还包括很多类型,更加详细的内容可以参考官方文档;
Bucket
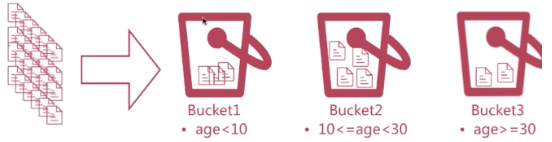
按照一定的规则将文档分配到不同的桶里,达到分类分析的目的;
比如把年龄小于10放入第一个桶,大于10小于30放入第二个桶里,大于30放到第三个桶里;
接下来我们介绍我们几个常用的类型:
Date Range
根据时间范围来划分桶的规则;


to表示小于当前时间减去10个月;from大于当前时间减去10个月;format设定返回格式;form和to还可以指定范围,大于某时间小于某时间;
Range
通过自定义范围来划分桶的规则;


这样就可以轻易做到上面按照年龄分组统计的规则;
Terms
直接按照term分桶,类似数据库group by以后求和,如果是text类型则按照分词结果分桶;


比较常用的类型大概就是这3种,比如还有什么Histogram等等,大家可以参考官方文档;
Pipeline
对聚合的结果在次进行聚合分析,根据输出的结果不同可以分成2类:
Parent
将返回的结果内嵌到现有的聚合结果中,主要有3种类型:
1.Derivative
计算Bucket值的导数;
2.Moving Average
计算Bucket值的移动平均值,一定时间段,对时间序列数据进行移动计算平均值;
3.Cumulatove Sum
计算累计加和;
Sibling
返回的结果与现有聚合结果同级;
1.Max/Min/Avg/Sum
2.Stats/Extended
Stats用于计算聚合中指定列的所有桶中的各种统计信息;
Extended对Stats的扩展,提供了更多统计数据(平方和,标准偏差等);
3.Percentiles
Percentiles 计算兄弟中指定列的所有桶中的百分位数;
更多介绍,请参考官方文档;
Matrix
矩阵分析,使用不多,参考官方文档;
原理探讨与数据准确性探讨:
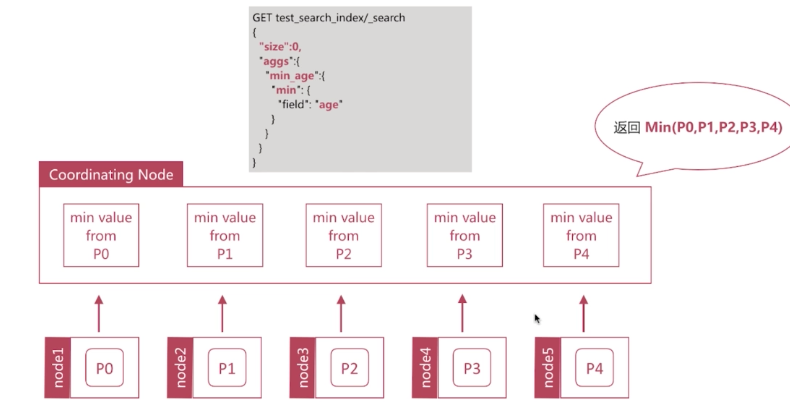
Min原理分析:
先从每个分片计算最小值 -> 再从这些值中计算出最小值
Terms聚合以及提升计算值的准确性:
Terms聚合的执行流程:每个分片返回top10的数据,Coordinating node拿到数据之后进行整合和排序然后返回给用户。注意Terms并不是永远准确的,因为数据分散在多个分片上,所以Coordinating node无法得到所有数据(这句话有同学会有疑惑请查看上一篇文章)。如果要解决可以把分片数设置为1,消除数据分散的问题,但是会分片数据过多问题,或者设在Shard_Size大小,即每次从Shard上额外多获取的数据,以提升准确度。
Terms聚合返回结果中有两个值:
doc_count_error_upper_bound 被遗漏的Term的最大值;
sum_other_doc_count 返回聚合的其他term的文档总数;
在Terms中设置show_term_doc_count_error可以查看每个聚合误算的最大值;
Shard_Size默认大小:shard_size = (size*1.5)+10;
通过调整Shard_Size的大小可以提升准确度,增大了计算量降低响应的时间。
由上面可以得出在Elasticsearch聚合分析中,Cardinality和Percentile分析使用是近似统计算法,就是结果近似准确但是不一定精确,可以通过参数的调整使其结果精确,意味着会有更多的时间和更大的性能消耗。
五、结束语
Search分析到此基本结束,下一篇介绍一些常用的优化手段和建立索引时的考虑问题;欢迎大家加群438836709,欢迎大家关注我公众号!
