背景: 项目中需要在 caffe 中增加 binary convolution layer, 所以在单步调试了 minist 的训练,大致看了一下流程,就详细看 convolution layer 了。
1、数据结构
caffe 的基本数据结构是 Blob,也就是数据流的基本结构。
2、网络结构
Net 是 Layer 构造出来的,Layer 包括了数据和运算(Blob input, Blob output, operation)。
3、卷积
3.1 卷积意义
卷积实际上是一种线性运算,只不过用卷积核移动的方式实现,会达到提取特征的效果。对于卷积层来说,输入是一个特征图(Feature Map), 输出是通过卷积核的提取得到的新特征图。之所以叫特征图,是由于卷积核的作用下得到的结果是和卷积核代表的特征相关的结果。
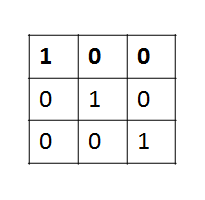
如上图的卷积核,当卷积核在输入上移动时,提取到的特征是和对角线相关的特征,对于输入来说,对角线的值越大,得到的特征值越大。
3.2 im2col
对于神经网络来说,只考虑计算机视觉,也就是二维图片的情况,原始原始输入是 batch_size x channels x height x width, 那么在计算的时候,每个卷积核移动的次数就是 height x width, 在 caffe 使用的卷积计算是矩阵乘法获得效率,用空间换时间,将图片按卷积核扩展。
贾扬凊大神在知乎的回答链接:在 caffe 中如何计算卷积?
(其他的实现方法可以参考 github 上 ncnn 的实现)
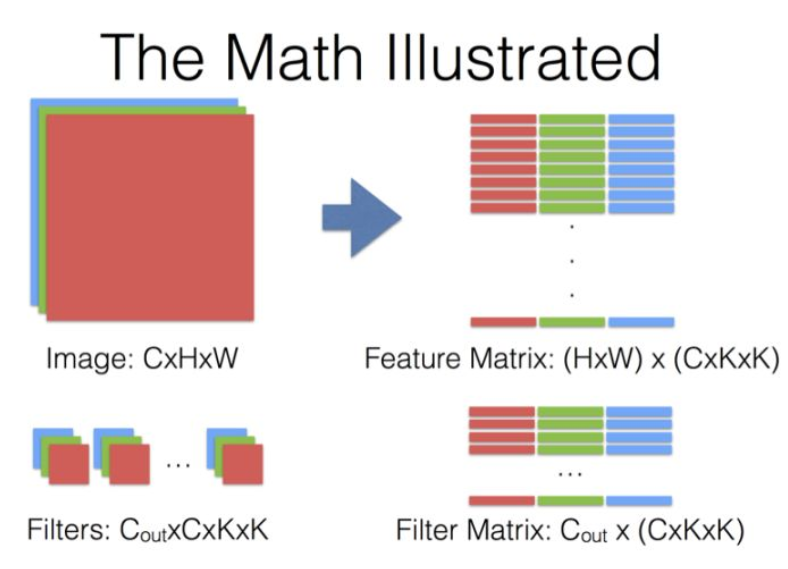
Image 和 Filters 都是实际所需要的内容, 后面 Feature Matrix 和 Filter Matirx 是计算过程的数据。
3.3 caffe 实现
实现部分在 base_conv_layer.cpp, 这种设计结构是为了 deconvolution 和 convolution 共用。Convolution 和 Deconvolution 都通过 ConvolutionParameter 配置基本参数,也就是说,在 Conv 和 Deconv 里的参数是一样的,但是实际上两个模块输入输出的 shape 和计算都是相反的,实现的原理是重写base_conv_layer 的虚函数,实现不同的 shape 定义和计算。 除此之外,还有一个翻转参数 reverse_dimensions() 通过虚函数的方法实现,但是只是在两种层里重写为返回 true 或者 false。贴一下 Setup 的注释,建立完卷积层就是计算的东西了,代码比较好读,不写了。
void BaseConvolutionLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) { // Configure the kernel size, padding, stride, and inputs. ConvolutionParameter conv_param = this->layer_param_.convolution_param(); force_nd_im2col_ = conv_param.force_nd_im2col(); /** * 这里解释一下,blob的CanonicalAxisIndex是为了标准化维度索引的输入,将一些非法维度输入转化为合法输入。 * blob的count(int)是统计从某个维度开始,到结尾的总个数。这里第一个维度表示的是样本个数,其后面的是表示输入特征的个数。 */ channel_axis_ = bottom[0]->CanonicalAxisIndex(conv_param.axis()); const int first_spatial_axis = channel_axis_ + 1; const int num_axes = bottom[0]->num_axes(); num_spatial_axes_ = num_axes - first_spatial_axis; // 计算空间轴个数 // 空间轴大于等于 0, 即保证 blob 的维数至少到 channel(channel 的位置是在 conv_param 中定义的) CHECK_GE(num_spatial_axes_, 0); vector<int> bottom_dim_blob_shape(1, num_spatial_axes_ + 1); vector<int> spatial_dim_blob_shape(1, std::max(num_spatial_axes_, 1)); // Setup filter kernel dimensions (kernel_shape_). kernel_shape_.Reshape(spatial_dim_blob_shape); // kernel dimensions = input dim in one channel int* kernel_shape_data = kernel_shape_.mutable_cpu_data(); // 修改 kernel_shape if (conv_param.has_kernel_h() || conv_param.has_kernel_w()) { // 给定卷积核 h 和 w 参数的时候确定是二维的 CHECK_EQ(num_spatial_axes_, 2) << "kernel_h & kernel_w can only be used for 2D convolution."; CHECK_EQ(0, conv_param.kernel_size_size()) << "Either kernel_size or kernel_h/w should be specified; not both."; kernel_shape_data[0] = conv_param.kernel_h(); kernel_shape_data[1] = conv_param.kernel_w(); } else { // 未给定 h w 参数的时候,是 n 维, 每一维的大小从 conv_param 获得 const int num_kernel_dims = conv_param.kernel_size_size(); CHECK(num_kernel_dims == 1 || num_kernel_dims == num_spatial_axes_) << "kernel_size must be specified once, or once per spatial dimension " << "(kernel_size specified " << num_kernel_dims << " times; " << num_spatial_axes_ << " spatial dims)."; for (int i = 0; i < num_spatial_axes_; ++i) { kernel_shape_data[i] = conv_param.kernel_size((num_kernel_dims == 1) ? 0 : i); } } for (int i = 0; i < num_spatial_axes_; ++i) { // 保证卷积核在每一维的大小是大于 0 的 CHECK_GT(kernel_shape_data[i], 0) << "Filter dimensions must be nonzero."; } // Setup stride dimensions (stride_). stride_.Reshape(spatial_dim_blob_shape); // 设置 stride, 和 kernal 类似 int* stride_data = stride_.mutable_cpu_data(); // cy, if there are stride params, then set as the params. If there are no param set as default. if (conv_param.has_stride_h() || conv_param.has_stride_w()) { CHECK_EQ(num_spatial_axes_, 2) << "stride_h & stride_w can only be used for 2D convolution."; CHECK_EQ(0, conv_param.stride_size()) << "Either stride or stride_h/w should be specified; not both."; stride_data[0] = conv_param.stride_h(); stride_data[1] = conv_param.stride_w(); } else { const int num_stride_dims = conv_param.stride_size(); CHECK(num_stride_dims == 0 || num_stride_dims == 1 || num_stride_dims == num_spatial_axes_) << "stride must be specified once, or once per spatial dimension " << "(stride specified " << num_stride_dims << " times; " << num_spatial_axes_ << " spatial dims)."; const int kDefaultStride = 1; for (int i = 0; i < num_spatial_axes_; ++i) { stride_data[i] = (num_stride_dims == 0) ? kDefaultStride : conv_param.stride((num_stride_dims == 1) ? 0 : i); CHECK_GT(stride_data[i], 0) << "Stride dimensions must be nonzero."; } } // Setup pad dimensions (pad_). pad_.Reshape(spatial_dim_blob_shape); // 设置 pad, 和 kernal 类似 int* pad_data = pad_.mutable_cpu_data(); // cy, if there are pad params, then set as the params. If there are no param set as default. if (conv_param.has_pad_h() || conv_param.has_pad_w()) { CHECK_EQ(num_spatial_axes_, 2) << "pad_h & pad_w can only be used for 2D convolution."; CHECK_EQ(0, conv_param.pad_size()) << "Either pad or pad_h/w should be specified; not both."; pad_data[0] = conv_param.pad_h(); pad_data[1] = conv_param.pad_w(); } else { const int num_pad_dims = conv_param.pad_size(); CHECK(num_pad_dims == 0 || num_pad_dims == 1 || num_pad_dims == num_spatial_axes_) << "pad must be specified once, or once per spatial dimension " << "(pad specified " << num_pad_dims << " times; " << num_spatial_axes_ << " spatial dims)."; const int kDefaultPad = 0; for (int i = 0; i < num_spatial_axes_; ++i) { pad_data[i] = (num_pad_dims == 0) ? kDefaultPad : conv_param.pad((num_pad_dims == 1) ? 0 : i); } } // Setup dilation dimensions (dilation_). // 膨胀卷积(有翻译为 空洞卷积, 更形象一些): 扩大感受野。 一种技术修正 pooling 丢失信息的技术。 dilation_.Reshape(spatial_dim_blob_shape); // 设置 dilation, 和 kernal 类似 int* dilation_data = dilation_.mutable_cpu_data(); const int num_dilation_dims = conv_param.dilation_size(); CHECK(num_dilation_dims == 0 || num_dilation_dims == 1 || num_dilation_dims == num_spatial_axes_) << "dilation must be specified once, or once per spatial dimension " << "(dilation specified " << num_dilation_dims << " times; " << num_spatial_axes_ << " spatial dims)."; const int kDefaultDilation = 1; for (int i = 0; i < num_spatial_axes_; ++i) { dilation_data[i] = (num_dilation_dims == 0) ? kDefaultDilation : conv_param.dilation((num_dilation_dims == 1) ? 0 : i); } // Special case: im2col is the identity for 1x1 convolution with stride 1 // and no padding, so flag for skipping the buffer and transformation. is_1x1_ = true; for (int i = 0; i < num_spatial_axes_; ++i) { is_1x1_ &= kernel_shape_data[i] == 1 && stride_data[i] == 1 && pad_data[i] == 0; if (!is_1x1_) { break; } } // Configure output channels and groups. channels_ = bottom[0]->shape(channel_axis_); // 通道数 num_output_ = this->layer_param_.convolution_param().num_output(); //param 中定义的 num_output,即 output “channel” CHECK_GT(num_output_, 0); // 至少一个输出 group_ = this->layer_param_.convolution_param().group(); CHECK_EQ(channels_ % group_, 0); CHECK_EQ(num_output_ % group_, 0) << "Number of output should be multiples of group."; if (reverse_dimensions()) { conv_out_channels_ = channels_; conv_in_channels_ = num_output_; } else { conv_out_channels_ = num_output_; conv_in_channels_ = channels_; } // Handle the parameters: weights and biases. // - blobs_[0] holds the filter weights // - blobs_[1] holds the biases (optional) vector<int> weight_shape(2); weight_shape[0] = conv_out_channels_; weight_shape[1] = conv_in_channels_ / group_; for (int i = 0; i < num_spatial_axes_; ++i) { weight_shape.push_back(kernel_shape_data[i]); } bias_term_ = this->layer_param_.convolution_param().bias_term(); vector<int> bias_shape(bias_term_, num_output_); if (this->blobs_.size() > 0) { CHECK_EQ(1 + bias_term_, this->blobs_.size()) << "Incorrect number of weight blobs."; if (weight_shape != this->blobs_[0]->shape()) { Blob<Dtype> weight_shaped_blob(weight_shape); LOG(FATAL) << "Incorrect weight shape: expected shape " << weight_shaped_blob.shape_string() << "; instead, shape was " << this->blobs_[0]->shape_string(); } if (bias_term_ && bias_shape != this->blobs_[1]->shape()) { Blob<Dtype> bias_shaped_blob(bias_shape); LOG(FATAL) << "Incorrect bias shape: expected shape " << bias_shaped_blob.shape_string() << "; instead, shape was " << this->blobs_[1]->shape_string(); } LOG(INFO) << "Skipping parameter initialization"; } else { if (bias_term_) { this->blobs_.resize(2); } else { this->blobs_.resize(1); } // Initialize and fill the weights: // output channels x input channels per-group x kernel height x kernel width this->blobs_[0].reset(new Blob<Dtype>(weight_shape)); shared_ptr<Filler<Dtype> > weight_filler(GetFiller<Dtype>( this->layer_param_.convolution_param().weight_filler())); weight_filler->Fill(this->blobs_[0].get()); // If necessary, initialize and fill the biases. if (bias_term_) { this->blobs_[1].reset(new Blob<Dtype>(bias_shape)); shared_ptr<Filler<Dtype> > bias_filler(GetFiller<Dtype>( this->layer_param_.convolution_param().bias_filler())); bias_filler->Fill(this->blobs_[1].get()); } } kernel_dim_ = this->blobs_[0]->count(1); //写成(conv_out_channels_ / group_) * kernel_dim_更直观。这个offset是相对group分组来讲的。 weight_offset_ = conv_out_channels_ * kernel_dim_ / group_; // Propagate gradients to the parameters (as directed by backward pass). this->param_propagate_down_.resize(this->blobs_.size(), true); }