大厂算法面试之leetcode精讲16.set&map
视频讲解(高效学习):点击学习
目录:
集合与字典 :
- 集合常见的形式是Set,字典常见的形式是Map
- Set 和 Map 主要的应用场景在于 数据重组 和 数据储存。
集合 与 字典 的区别:
- 共同点:集合、字典 可以储存不重复的值
- 不同点:集合类似于数组,元素的只有key没有value,value就是key。字典是以 [key, value] 的形式储存,键的范围不限于字符串,各种类型的值(包括对象)都可以当作键
时间复杂度:
set或map可以用哈希表或平衡二叉搜索树实现
哈希表实现的map或者set查找的时间复杂度是O(1),哈希表优点是查找非常快,哈希表的缺点是失去了数据的顺序性,平衡二叉搜索树实现的map或set查找时间复杂度是O(logn),它保证了数据顺序性
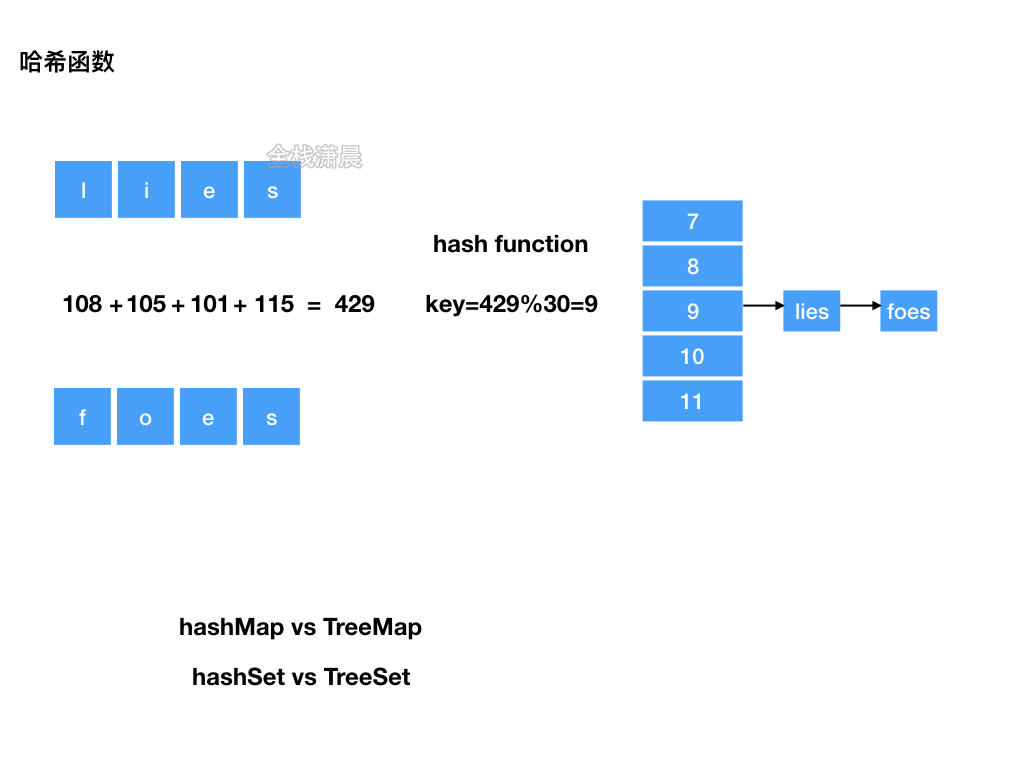
哈希函数
哈希函数是一个接受输入值的函数,由此输入计算出一个确定输出。
- 均匀分布:哈希函数计算出来的地址均匀分布
- 哈希碰撞:哈希函数计算出来的结果冲突
- 开放定址法
- 链地址法
1. 两数之和 (easy)
方法1.暴力枚举
- 思路:两层for循环,第一层
for i:0->n-1, 枚举nums中的每一个数x,第二层for j:i+1->n-1,寻找是否存在两个数字的和是target。 - 复杂度分析:时间复杂度:
O(n^2), n为数组的长度。空间复杂度O(1)。
方法2.哈希表:
- 思路:方法一第一层循环是必须的,关键是优化第二次循环,也就是寻找
targrt-x的过程,这里关键采用空间换时间,也就是采用哈希表进行优化,让查找的过程变为O(1)。首先还是遍历nums数组,然后在哈希表中寻找target-x,如果不存在就把当前元素x和下标存入哈希表,如果存在就返回target-x和当前元素的下标 - 复杂度分析:时间复杂度
O(n), n为数组的长度,空间复杂度O(n),n为数组的长度,主要是哈希表的空间开销
js:
var twoSum = function (nums, target) {
const map = new Map();
for (let i = 0; i < nums.length; i++) {//第一层循环
const complement = target - nums[i];
if (map.has(complement)) {//判断complement是否在map中
return [map.get(complement), i]; //存在的话返回两个数的下标
} else {
map.set(nums[i], i);//不存在map中就将当前元素和下标存入map
}
}
return [];
};
java:
class Solution {
public int[] twoSum(int[] nums, int target) {
if (Objects.isNull(nums) || nums.length == 0) return null;
HashMap<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
int complement = target - nums[i];
if (map.containsKey(complement)) {
return new int[]{map.get(complement), i};
}
map.put(nums[i], i);
}
return null;
}
}
454. 四数相加 II( medium)
方法1:哈希表
- 思路:在A和B中取出两个数的组合,将这两个数的和作为键,出现次数作为值加入哈希表中,循环C、D,判断C和D中是否存在两个数的和 加 AB中的俩元素的和正好是0,统计组合数
- 复杂度:时间复杂度
O(n^2),两个嵌套循环。空间复杂度O(n^2),哈希表的空间,最差的情况下是n^2
js:
var fourSumCount = function(A, B, C, D) {
const countAB = new Map();
//在A和B中取出两个数的组合,将这两个数的和作为键,出现次数作为值加入哈希表中,
A.forEach(u => B.forEach(v => countAB.set(u + v, (countAB.get(u + v) || 0) + 1)));
let ans = 0;
for (let u of C) {//循环C、D
for (let v of D) {
if (countAB.has(-u - v)) {//判断C和D中是否存在两个数的和 加 AB中的俩元素的和正好是0
ans += countAB.get(-u - v);//累加组合数
}
}
}
return ans;
};
java:
class Solution {
public int fourSumCount(int[] A, int[] B, int[] C, int[] D) {
Map<Integer, Integer> countAB = new HashMap<Integer, Integer>();
for (int u : A) {
for (int v : B) {
countAB.put(u + v, countAB.getOrDefault(u + v, 0) + 1);
}
}
int ans = 0;
for (int u : C) {
for (int v : D) {
if (countAB.containsKey(-u - v)) {
ans += countAB.get(-u - v);
}
}
}
return ans;
}
}
242. 有效的字母异位词 (easy)
方法1.排序
- 思路:两个字符串转成数组,排序后转回字符串进行比较。
- 复杂度分析:时间复杂度
O(nlogn),排序采用快排,时间复杂度是nlogn,比较两字符串是否相等时间复杂度为n,O(n)+O(nlogn)=O(nlogn)。空间复杂度为O(logn),排序需要O(logn)的空间,java和js字符串是不可变的,需要额外的O(n)空间来拷贝字符串,我们忽略这个复杂度,这依赖不同语言实现的细节。
方法2.哈希表:
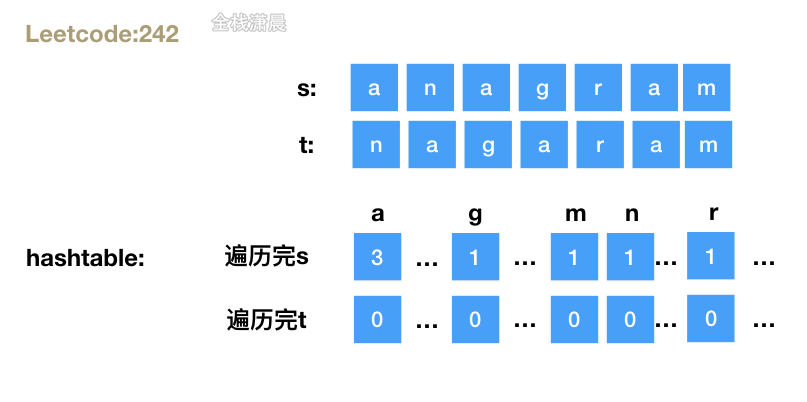
- 思路:采用空间换时间的策略,准备一个数组,循环字符串s,每个元素出现一次加1,然后循环t元素,每次出现的字符减1,如果t中出现一些不在s中的字符 则返回false,所有循环结束 说明两个字符串中每个字符的数量相同
- 复杂度分析: 时间复杂度
O(n),n是字符串的长度,空间复杂度O(s),s为字符集大小
js:
var isAnagram = function(s, t) {
if (s.length !== t.length) {//长度不想等 直接返回false
return false;
}
const table = new Array(26).fill(0);//大小为26的数组
for (let i = 0; i < s.length; ++i) {//循环字符串s,每个元素出现一次加1
table[s.codePointAt(i) - 'a'.codePointAt(0)]++;
}
for (let i = 0; i < t.length; ++i) {//循环t元素
table[t.codePointAt(i) - 'a'.codePointAt(0)]--;//每次出现的字符减1
//如果t中出现一些字符对于s中的字符 则返回false
if (table[t.codePointAt(i) - 'a'.codePointAt(0)] < 0) {
return false;
}
}
return true;//所有循环结束 说明两个字符串中每个字符的数量相同
}
java:
class Solution {
public boolean isAnagram(String s, String t) {
if (s.length() != t.length()) {
return false;
}
int[] table = new int[26];
for (int i = 0; i < s.length(); i++) {
table[s.charAt(i) - 'a']++;
}
for (int i = 0; i < t.length(); i++) {
table[t.charAt(i) - 'a']--;
if (table[t.charAt(i) - 'a'] < 0) {
return false;
}
}
return true;
}
}
447. 回旋镖的数量 (medium)
- 思路:循环数组,找出与当前元素距离相同的点,记录频次加入map中,最后循环map,从相同距离的数量中选取两个组合出来,加入结果中。从m个元素中选取两个的排列组合数 是
m*(m-1) - 复杂度:时间复杂度
O(n^2),数组遍历两层,空间复杂度O(n),哈希表的空间
js:
//m = {1:3,2:5}
var numberOfBoomerangs = function (points) {
let ans = 0;
for (const p of points) {
const m = new Map();
for (const q of points) {
//统计距离当前点相同距离的数量 加入map中
const dis = (p[0] - q[0]) * (p[0] - q[0]) + (p[1] - q[1]) * (p[1] - q[1]);
m.set(dis, (m.get(dis) || 0) + 1);
}
for (const [_, item] of m.entries()) {//从相同距离的点的数量中选取两个
ans += item * (item - 1);
}
}
return ans;
};
java:
class Solution {
public int numberOfBoomerangs(int[][] points) {
int ans = 0;
for (int[] p : points) {
Map<Integer, Integer> cnt = new HashMap<Integer, Integer>();
for (int[] q : points) {
int dis = (p[0] - q[0]) * (p[0] - q[0]) + (p[1] - q[1]) * (p[1] - q[1]);
cnt.put(dis, cnt.getOrDefault(dis, 0) + 1);
}
for (Map.Entry<Integer, Integer> entry : cnt.entrySet()) {
int item = entry.getValue();
ans += item * (item - 1);
}
}
return ans;
}
}
187. 重复的DNA序列 (medium)
- 思路:用map存储子串出现的次数,循环dna序列,每次截取长度为10的子串,加入map中 并更新出现的次数,次数超过2,加入ans
- 复杂度:时间复杂度
O(n),n是字符串的长度。空间复杂度O(n)
js:
var findRepeatedDnaSequences = function(s) {
const L = 10;
const ans = [];
const cnt = new Map();
const n = s.length;
for (let i = 0; i <= n - L; ++i) {
const sub = s.slice(i, i + L)//截取长度为10的子串
cnt.set(sub, (cnt.get(sub) || 0) + 1);//加入map中 并更新出现的次数
if (cnt.get(sub) === 2) {
ans.push(sub);
}
}
return ans;
};
java:
class Solution {
static final int L = 10;
public List<String> findRepeatedDnaSequences(String s) {
List<String> ans = new ArrayList<String>();
Map<String, Integer> cnt = new HashMap<String, Integer>();
int n = s.length();
for (int i = 0; i <= n - L; ++i) {
String sub = s.substring(i, i + L);
cnt.put(sub, cnt.getOrDefault(sub, 0) + 1);
if (cnt.get(sub) == 2) {
ans.add(sub);
}
}
return ans;
}
}
49. 字母异位词分组 (medium)
方法1.排序
- 思路:遍历字符串数组,对每个字符串中的字符排序,加入map对应的key的数组中。
- 复杂度:时间复杂度
O(n*klogk),n是字符串的个数,k是最长的字符串的长度,排序复杂度O(klogk),n次排序,哈希表更新O(1)。空间复杂度O(nk),排序空间复杂度O(nlogk),map空间复杂度O(nk),取较大的O(nk)
js:
var groupAnagrams = function(strs) {
const map = new Map();
for (let str of strs) {
let array = Array.from(str);//字符转成数组
array.sort();//排序
let key = array.toString();
let list = map.get(key) ? map.get(key) : new Array();//从map中取到相应的数组
list.push(str);//加入数组
map.set(key, list);//重新设置该字符的数组
}
return Array.from(map.values());//map中的value转成数组
};
java:
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
Map<String, List<String>> map = new HashMap<String, List<String>>();
for (String str : strs) {
char[] array = str.toCharArray();
Arrays.sort(array);
String key = new String(array);
List<String> list = map.getOrDefault(key, new ArrayList<String>());
list.add(str);
map.put(key, list);
}
return new ArrayList<List<String>>(map.values());
}
}
方法2.计数
- 思路:题意是字符串的字符都是小写,可以对每个字符串统计其中字符的频次,将每个字符频次相同的字符串放在一组
- 复杂度:时间复杂度
O(n*k),n是字符串个数,k是最长字符串长度,循环字符串数组复杂度O(n),对每个字符串统计频次复杂度O(k)。空间复杂度O(n*k),map中存放了n个大小最长为k的字符串。
js:
var groupAnagrams = function(strs) {
const map = {};
for (let s of strs) {//循环字符串数组
const count = new Array(26).fill(0);//字符都是小写,初始化大小为26的数组
for (let c of s) {//对字符串的每个字符统计频次
count[c.charCodeAt() - 'a'.charCodeAt()]++;
}
map[count] ? map[count].push(s) : map[count] = [s];//加入map
}
return Object.values(map);
};
java:
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
Map<String, List<String>> map = new HashMap<String, List<String>>();
for (String str : strs) {
int[] counts = new int[26];
int length = str.length();
for (int i = 0; i < length; i++) {
counts[str.charAt(i) - 'a']++;
}
StringBuffer sb = new StringBuffer();
for (int i = 0; i < 26; i++) {
if (counts[i] != 0) {
sb.append((char) ('a' + i));
sb.append(counts[i]);
}
}
String key = sb.toString();
List<String> list = map.getOrDefault(key, new ArrayList<String>());
list.add(str);
map.put(key, list);
}
return new ArrayList<List<String>>(map.values());
}
}