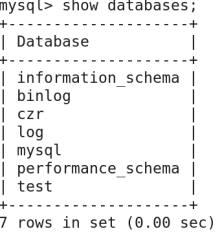
1》创建数据库:
语法:create database 数据库名;
语法:show databases 查看已经存在数据库
举例:
Mysql->create database zytest; 注意每一条要以;号结尾
Mysql->show databases;查询是否创建成功
>use zytest;
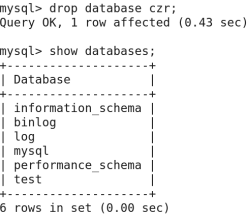
2》删除数据库:
语法:drop database 数据库名字;<使用此命令,请注意>
举例:
Mysql->drop database zytest; 删除zytest
Mysql->show databases; 查询是否删除成功
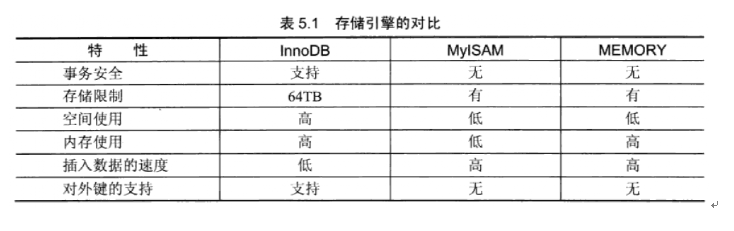
3》存储引擎介绍:
1>innoDB引擎
innoDB是mysql的一种存储引擎,inodb给mysql的表提供了事务日志,回滚、奔溃、修复能力和多版本并发控制的事务安全。Mysql从3.23.34a开始包含 innoDB存储引擎.
innoDB是第一个提供外键约束的表引擎,而且对innoDB对事务处理的能力。也是其它引擎无法与之抗衡的。,
innodb支持自动增长列使用auto_increment,自动增长列不值不能为空
innodb 存储引擎中支持外键Z(foreign key),外键所在的表为子表,外键所依赖的表为父母,父表中的被子表外检关联的字段必须是主键,当删除、更新父表 的某条信息时,子表也必须有相应的改变,
innodb存储引擎中,创建表的表结构存储在.frm文件中,数据和索引存储在innodb_data_home_dir 和 innodb_data_file_path定义的表空间.
元数据文件所有的表的ibdata1如果不定义innodb_data_home_dir 参数。默认就在datadir下面,InnoDB每个数据表的元数据(metadata)总是保 存在ibdata1 这个共享表空间里,因此该文件必不可少innodb_data_file_path = ibdata1:10M:autoextend
数据和索引文件集合在一起:*.ibd每个表都有单独一个元数据,
表定义文件:*.frm
所有的表总的元数据文件为ibdata1
Inoodb存储引擎的
优势:在于提供了良好的事务管理、崩溃、修复能力和并发控制,
缺点:是其读写效率稍差,占用的数据空间相对比较大.
什么是事务??我们先来看看ACID原则
ACID是数据库事务正常执行的四个基本要素,分别指原子性、一致性、独立性及持久性
原子性(Atomicity):事务的原子性是指一个事务要么全部执行,要么不执行.也就是说一个事务不可能只执行了一半就 停止了.比如你从取款机取钱, 这个事务可以分成两个步骤:1划卡,2出钱.不可能划了卡,而钱却没出来.这两步必须同时完成.要么就不完成.
一致性(Consistency):事务的一致性是指事务的运行并不改变数据库中数据的一致性.例如,完整性约束了a+b=10,一个事务改变了a,那么b也应该随 之改变.
独立性(Isolation):事务的独立性也有称作隔离性,是指两个以上的事务不会出现交错执行的状态.因为这样可能会导致数据不一致.
持久性(Durability):事务的持久性是指事务执行成功以后,该事务所对数据库所作的更改便是持久的保存在数据库之中,不会无缘无故的回滚.
2>MyISAM引擎
MyISAM存储表分为3个文件,文件与表名相同,扩展包括frm,MYD和MYI,
frm为扩展名的文件存储表的结构
myd为扩展名的文件存储数据
myi为扩展名的文件存储索引
优点:占用空间小,。处理速度快,
缺点:不支持事务日志的完整性和并发性 3>MEMORY 引擎 Mysql中的特殊引擎,所有的数据全部存放于内存当中,在企业生产环境当中。几乎是用不到。因为数据存储在内存,如果内存出现异常。将影响数据的完 整性。 优点:存储速度快
缺点:缺乏稳定性和完整性
MyISAM:不支持外键,不支持事务,索引和数据分开的,可以加载更多的索引,并且索引是压缩的,相对内存来说使用效率就提高不少,,他使用一 种表格锁定的机制,来优化多个并发读写操作,MYISAM强调了快速读取操作;
使用场合:在承载的大部分项目是读多写少的项目平台中,而MyISAM的读性能是比Innodb强不少的
Innodb: 支持外键,支持事务、回滚,但是索引和数据是紧密捆绑的,没有使用压缩从而会造成INNODB比MYISAM体积庞大不小。
使用场合:在承载的大部分项目执行insert 和update的话,应该选择InnoDB.
锁的介绍:mysql常见的三种锁级别——表级锁、页面锁、行级锁;其中表级锁有两种模式——表共享读锁和表独占写锁。
MyISAM:
表级锁:对myisam表进行读操作的时候,它不会阻塞其他用户对同一表的读请求,但会阻塞对同一表>的写操作;
对myisam表进行写操作的时候,它会阻塞其他用户对同一表的读、写请求.
innodb:
提供行锁(locking on row level),另外,InnoDB表的行锁也不是绝对的,如果在执行一个SQL语句时MySQL不能确定要扫描的范围,InnoDB表同样会 锁全表.
行级锁的优点如下:
1)当很多连接分别进行不同的查询时减小LOCK状态。
2)如果出现异常,可以减少数据的丢失。因为一次可以只回滚一行或者几行少量的数据。
行级锁的缺点如下:
1)比页级锁和表级锁要占用更多的内存。
2)进行查询时比页级锁和表级锁需要的I/O要多,所以我们经常把行级锁用在写操作而不是读操作。
3)容易出现死锁。
注意:inodb不能确定操作的行,这个时候就使用的意向锁,也就是表锁on row level);
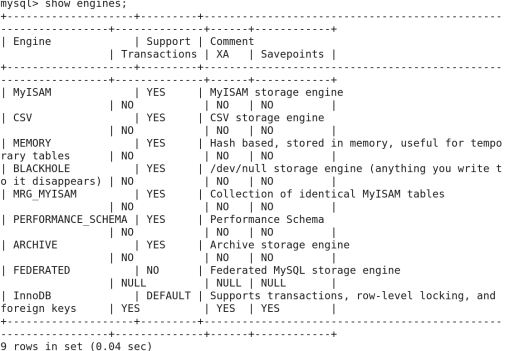
4》察看存储引擎:
存储引擎是Mysql的特点,Mysql可以选择多种存储引擎及不同的存储方式,是否进行事物处理等;
1> 查询Mysql支持的引擎
Mysql->show engines;
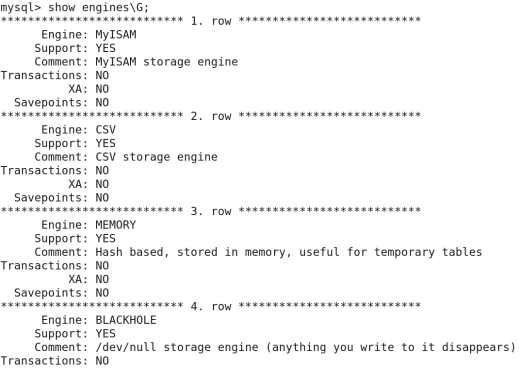
Mysql->show enginesG;
2>查询Mysql引擎详细信息:
Mysql->show engine innodb statusG;
3>查询Mysql默认存储引擎
Mysql-> show variables like 'storage_engine';
如果想修改存储引擎,可以在 my.ini中进行修改或者my.cnf中的Default-storage-engine=引擎类型;

5》如何选择存储引擎:
在企业生产环境中,选择一个款合适的存储引擎是一个很复杂的问题。每一种存储引擎都有各自的优势,不能笼统的说,谁比谁好。通常用的比较多的 是innodb存储引擎
以下是存储引擎的对比:
==========================创建,修改,删除表:
1》创建表的方法:
语法:create table 表名(
属性名数据类型完整约束条件,
属性名数据类型条完整约束件,
。。。。。。。。。
属性名数据类型
);
举例:
create table example0(
id int,
name varchar(20),
sexboolean);
2》表的完整性约束:
| 约束条件 | 说明|
| (1)primary key | 标识该字段为表的主键,具备唯一性|
| (2)foreign key | 标识该字段为表的外键,与某表的主键联系|
| (3)not null | 标识该属于的值不能为空|
| (4)unique | 标识这个属性值是唯一|
| (5)auto_increment | 标识该属性值的自动增加
| (6)default | 为该属性值设置默认值|
1>设置表的主键:
主键是一个表的特殊字段,这个字段是唯一标识表中的每条信息,主键和记录的关系,跟人的身份证一样。名字可以一样,但是身份证号码觉得不会一样, 主键用来标识每个记录,每个记录的主键值都不同,主键可以帮助Mysql以最快的速度查找到表中的某一条信息,主键必须满足的条件那就是它的唯一性,表中的 任意两条记录的主键值,不能相同,否则就会出现主键值冲突,主键值不能为空,可以是单一的字段,也可以多个字段的组合。
举例:
create table sxkj(
User_id int primary key,
user_name varchar(20),
user_sexchar(7));
2>设置多个字段做主键
举例:
create table sxkj2(
user_id int ,
user_name float,
grade float,
primary key(user_id,user_name));
3>设置表的外键:
外键是表的一个特殊字段,如果aa是B表的一个属性且依赖于A表的主键,那么A表被称为父表。B表为被称为子表,
举例说明:
user_id 是A 表的主键,aa 是B表的外键,那么user_id的值为zhangsan,如果这个zhangsan离职了,需要从A表中删除,那么B表关于 zhangsan的信息也该得到相应的删除,这样可以保证信息的完整性。
语法:
constraint外键别名 foreign key(外键字段1,外键字段2)
references 表名(关联的主键字段1,主键字段2)
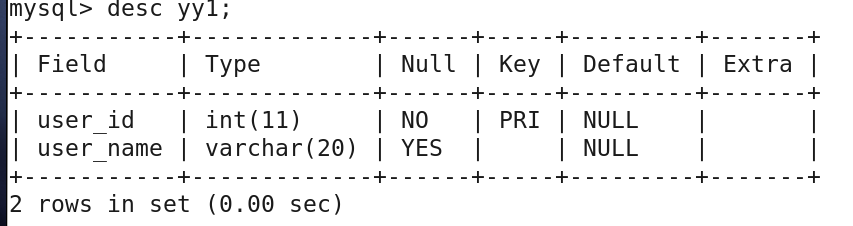
(1) yy1表存储了zhangsan姓名和ID号
create table yy1(
user_id int primary key not null,
user_name varchar(20));
(2) yy2表存储了ID号和zhangsan的年龄(old)
create table yy2(
user_id int primary key not null,
old int(5),
constraint y_fk foreign key(user_id)
references yy1(user_id)on delete cascade on update cascade);

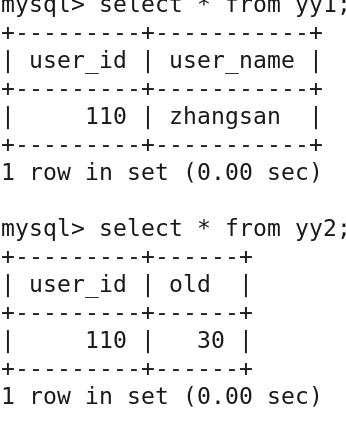
(3)数据填充yy1和yy2表
insert into yy1 values('110','zhangsan');
insert into yy2 values('110','30');
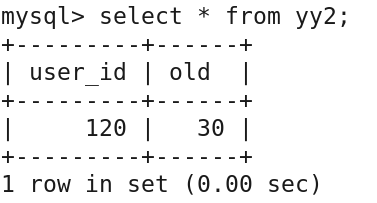
(4)更新测试:
update yy1 set user_id='120' where user_name='zhangsan';
查询验证
select * from yy2;
(5)删除测试:
delete from yy1 where user_id='120';
查询验证
select * from yy2;

4>设置表的非空值
语法:属性名数据类型 NOT NULL
举例:
create table C(
user_id int NOT NULL);
5> 设置表的唯一性约束
唯一性指的就是所有记录中该字段。不能重复出现。
语法:属性名数据类型 unique
举例:
root@zytest 15:43>create table D(
->user_id int unique);
root@zytest 15:44>show create table D;
6>设置表的属性值自动增加
Auto_increment 是Mysql数据库中特殊的约束条件,它的作用是向表中插入数据时自动生成唯一的ID,一个表只能有一个字段使用 auto_increment 约束,必须是唯一的;
语法:属性名数据类型 auto_increment,默认该字段的值从1开始自增。
举例:
create table F( user_id int primary key auto_increment);
root@zytest 15:56>insert into F values();插入一条空的信息
Query OK, 1 row affected, 1 warning (0.00 sec)
root@zytest 15:56>select * from F;值自动从1开始自增
+---------+
| user_id |
+---------+
| 1 |
+---------+
1 row in set (0.01 sec)
7>、设置表的默认值
在创建表时,可以指定表中的字段的默认值,如果插入一条新的纪录时,没有给这个字段赋值,那么数据库会自动的给这个字段插入一个默认 值,字段的默认值用default来设置。
语法: 属性名数据类型 default 默认值
举例:
root@zytest 16:05>create table G(
user_id int primary key auto_increment,
user_name varchar(20) default 'zero');
root@zytest 16:05>insert into G values('','');
插入数据,应为ID为自增,值为空,user_name设置了默认值,所以也为空。
3》查看表结构的方法:
DESCRIBE可以查看那表的基本定义,包括、字段名称,字段的数据类型,是否为主键以及默认值等。。
(1)语法:describe 表名;可以缩写为desc
(2) show create table查询表详细的结构语句,
1>修改表名
语法:alter table 旧表名 rename 新表名;
举例;
root@zytest 16:11>alter table A rename zyA;
Query OK, 0 rows affected (0.02 sec)
2>修改表的数据类型
语法:alter table 表名 modify 属性名 数据类型;
举例;
root@zytest 16:15>alter table A modify user_name double;
Query OK, 0 rows affected (0.18 sec)
3>修改表的字段名称
语法: alter table 表名 change 旧属性名 新属性名 新数据类型;
root@zytest 16:15>alter table A change user_name user_zyname float;
Query OK, 0 rows affected (0.10 sec)
4>修改增加字段
alter table 表名 ADD 属性名1 数据类型 [完整性约束条件] [FIRST |AFTER 属性名2]
v 增加没有约束条件的字段:
root@zytest 16:18>alter table A add phone varchar(20);
Query OK, 0 rows affected (0.13 sec)
v 增加有完整约束条件的字段:
root@zytest 16:42>alter table A add age int(4) not null;
Query OK, 0 rows affected (0.13 sec)
v 在表的第一个位置增加字段默认情况每次增加的字段。都在表的最后。
root@zytest 16:45>alter table tt add num int(8) primary key first;
Query OK, 1 row affected (0.12 sec)
Records: 1 Duplicates: 0 Warnings: 0
v 执行在那个位置插入新的字段,在phone后面增加
root@zytest 16:46>alter table A add address varchar(30) not null after phone;
Query OK, 0 rows affected (0.10 sec)
Records: 0 Duplicates: 0 Warnings: 0
总结:
(1) 默认ADD 增加字段是在最后面增加
(2) 如果想在表的最前端增加字段用first关键字
(3) 如果想在某一个字段后面增加的新的字段,使用after关键字
5>删除一个字段
alter table 表名DROP 属性名;
举例: 删除A 表的age字段
root@zytest 16:51>alter table A drop age;
Query OK, 0 rows affected (0.11 sec)
Records: 0 Duplicates: 0 Warnings: 0
6>更改表的存储引擎
alter table表名 engine=存储引擎
alter table A engine=MyISAM;
7>删除表的外键约束
alter table 表名drop foreign key 外键别名;
alter table yy2 drop foreign key y_fk;
4》删除表的方法
1>删除没有被关联的普通表
drop table 表名;
2>删除被其它表关联的父表
在数据库中某些表之间建立了一些关联关系。一些成为了父表,被其子表关联,要删除这些父表,就不是那么简单了。删除方法,先删除所关联的 子表的外键,在删除主表。