Title: DeepReID: Deep Filter Pairing Neural Network for Person Re-Identification
Authors: Wei Li, Rui Zhao, Tong Xiao, Xiaogang Wang*
Affiliation: The Chinese University of Hong Kong, Hong Kong
CVPR2014
Contribution
- 同时期两篇深度学习行人重识别的开山之作之一(另一篇),很巧的是也用的了类似于siamese的结构(虽然作者没有提到)
- 提出了CUHK03数据集
摘要
行人重识别是为了匹配行人探测器检测到的不相交的摄像头视图中的行人图像。主要挑战包括光线、姿势、视点、模糊效果、图像分辨率、相机设置、遮挡和相机视图中的背景杂波的复杂变化。此外,行人探测器的检测误差会影响大多数现有的行人重识别方法,所以这些方法往往使用手动裁剪的行人图像来假设完美的检测。
本文提出了一种新的滤波器对神经网络(filter pairing neural network, FPNN),用于联合处理错位(misalignment)、光度和几何变换(photometric and geometric transforms)、遮挡和背景杂波。所有关键component都进行联合优化,以在与其他component合作时最大限度地提高每个component的强度。与使用手工特征的现有方法相比,我们的方法自动从数据中学习最适合重识别任务的特征。学习的滤波器对对光度变换进行编码。它的深层结构使得它可以模拟出混合了复杂的光度变换和几何变换的模型。该文构建了最大的重识别benchmark数据集,其中包含1360名行人共13164张图像。与仅提供手动裁剪的行人图像的现有数据集不同,我们的数据集提供自动检测的边界框,用于接近实际应用的评估。在这个数据集上,该文的神经网络明显优于目前最先进的方法。
1. 介绍
第一段介绍行人重识别的概念及意义。以及存在的挑战。
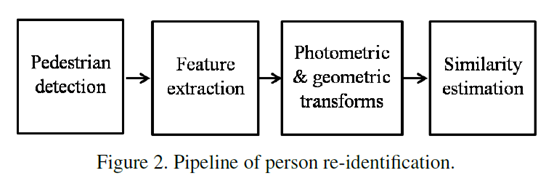
第二段讲行人重识别的一般步骤(图二)。其中,作者所述的光度变换和几何变换(photometric and geometric transforms)应该就是映射过程,作者应该是从重识别问题中的光照问题和几何变换问题的角度考虑的。
文本的贡献包括:
1. 提出了filter pairing neural network (FPNN[思考1] )的结构。其好处有三[思考2] :①可以联合处理错位、光度和几何变换、遮挡和背景杂波;②自动学习特征而不需要手动设计;③之前的方法都假设交叉视角(cross-view)是单一变换,而FPNN可以建模复杂的变换。
2. 使用了一些训练技巧,包括dropout,数据增强,数据平衡,Bootstrapping。
3. 建立了数据集CUHK03,包含手动裁剪和自动检测的行人样本。
[思考1]就是Siamese结构?
[思考2]感觉就是深度学习本身的优势
2. Related Work
略
3. Model
网络结构如图
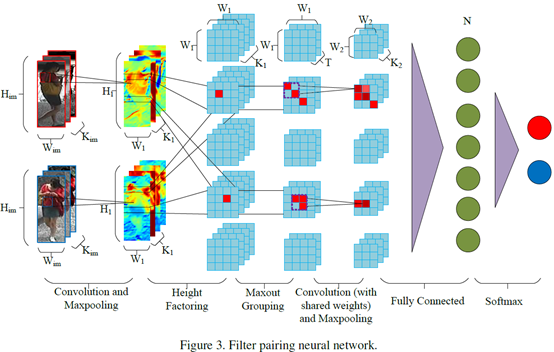
输入为尺寸 的RGB或LAB图像
的RGB或LAB图像
3.1. Feature extraction
作者用一层卷积层(+ReLU)和Max Pooling层做特征提取[思考3] 。输出尺寸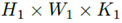
[思考3]特征提取仅用一层,高层语义特征提取不到
3.2. Patch matching
从3.1输出的feature map被划分成M个水平条带(图三中的height factoring),每个条带有W1个patch。两个feature map同一个条带的patch才会比较,那么两个条带分别有W1个patch,patch和patch计算[思考4] ,得到W1* W1的矩阵(称之为patch displacement matrices)。一共输出K1M W1×W1[思考5] 的patch matching layer。
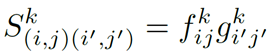
如果矩阵的某个元素的响应值很高,那说明patches (i, j) and (i′, j′) 在特定的特征上都有高响应。
[思考5]从图上看,输出是M个feature map,每个是M1*M1,K个通道
3.3. Modeling mixture of photometric transforms
即图三中的Maxout Grouping,对于K个通道,划分成T个组(group),每个组只输出最大的激活值[思考6] 。输出MT W1×W1,将其视为M张W1×W1[肖1] 的feature map,每张channel=T。
[思考6]是每个像素位置对应T个像素值的最大值,最后每组输出W1×W1,总共T个组?
3.4. Modeling part displacement
卷积层(+ReLU)和Max Pooling层。输出大小M个W2×W2×K2的特征层
3.5. Modeling pose and viewpoint transforms
全连接层FC。N个节点。
3.6. Identity Recognition
softmax层,输出1(两张图像匹配)或0(不匹配)。
LOSS函数: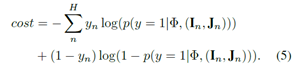
4. Training Strategies
dropout,Data Augmentation,Data balancing,Bootstrapping
5. Dataset
提出CUHK03
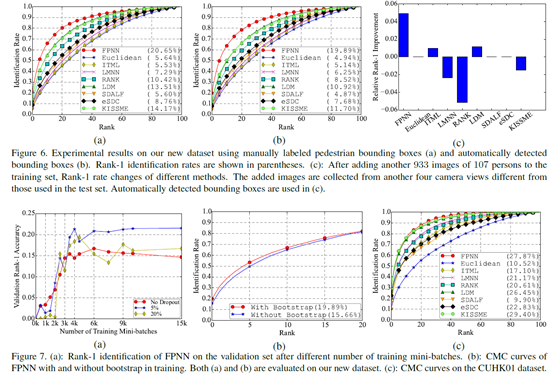
6. Experimental Results
比对了手动裁剪的图像的表现,自动检测出的图像的表现,以及添加额外照相机拍摄的训练样本之后测试集的表现(测试模型的泛化能力)