安装
windows
1. pip3 install wheel #安装后,便支持通过wheel文件安装软件,wheel文件官网:https://www.lfd.uci.edu/~gohlke/pythonlibs 2. pip3 install lxml 3. 安装pyOpenSSL https://pypi.org/project/pyOpenSSL/#downloads 下载后利用 Pip 安装即可: C:Usersjingjing>pip install pyOpenSSL-17.5.0-py2.py3-none-any.whl
4.安装PyWin32 https://sourceforge.net/projects/pywin32/files/pywin32/Build%20221/ 如 Python 3.6 版本可以选择下载 pywin32-221.win-amd64-py3.6.exe,下载完毕之后双击安装即可
5 下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted Twisted-18.4.0-cp36-cp36m-win_amd64.whl 安装 C:Usersjingjing>pip install Twisted-18.4.0-cp36-cp36m-win_amd64.whl Processing c:usersjingjing wisted-18.4.0-cp36-cp36m-win_amd64.whl ……
安装好了以上的依赖库,最后安装 Scrapy,依然使用 Pip 6、pip3 install scrapy C:Usersjingjing>pip install scrapy Collecting scrapy Downloading https://files.pythonhosted.org/packages/db/9c/cb15b2dc6003a805afd2 ……
linux安装
sudo pip install -i http://pypi.douban.com/simple/ scrapy --trusted-host pypi.douban.com
Scrapy框架介绍
Scrapy是一个基于Twisted的异步处理框架,是纯Python实现的爬虫框架,其架构清晰,模块之间的耦合程度低,可扩展性极强,可以灵活完成各种需要。我们只需要定制开发几个模块就可以轻松实现一个爬虫。
文档
http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/overview.html
https://doc.scrapy.org/en/latest/intro/overview.html(英文)
1. 架构介绍:
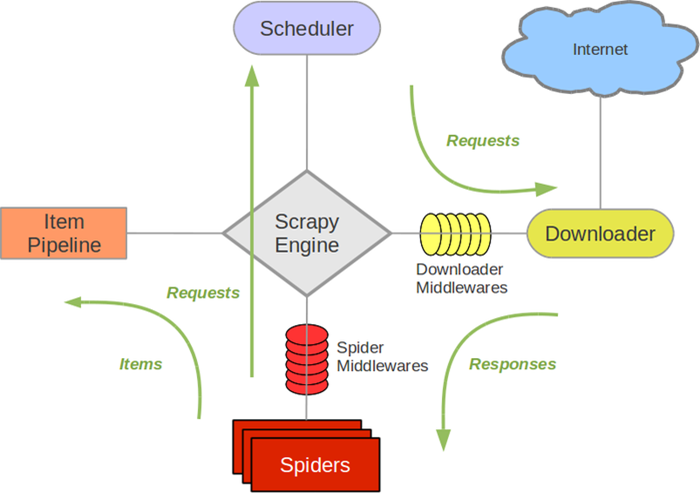
1、引擎(EGINE)
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。
2、调度器(SCHEDULER)
用来接受引擎发过来的请求, 加入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
3、下载器(DOWLOADER)
负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
4、爬虫(SPIDERS)
它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)
5、项目管道(ITEM PIPLINES)
它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
6、下载器中间件(Downloader Middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 下载器中间件(Downloader Middleware) 。
7、爬虫中间件(Spider Middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 Spider中间件(Middleware) 。
2. 数据流
Scrapy中的数据流有引擎控制,数据流的过程如下
- 1、spiders获取request请求,将请求交给引擎。
- 2、引擎(EGINE)把处理好的请求交给了调度器,通过队列把这些请求保存起来,调度一个出来再传给引擎。
- 3、调度器(SCHEDULER)返回给引擎一个要爬取的url。
- 4、引擎把调度好的请求发送给download,通过中间件发送(这个中间件至少有 两个方法,一个请求的,一个返回的),
- 5、download完成下载就返回一个response对象,通过下载器中间件返回给引擎。
- 6、引擎从下载器中收到response对象,传给了spiders(spiders里面做两件事,1、产生request请求,2、为request请求绑定一个回调函数),spiders只负责解析爬取的任务。不做存储,
- 7、解析完成之后返回一个解析之后的结果items对象及(跟进的)新的Request给引擎就被ITEM PIPELUMES处理了
- 8、引擎将(Spider返回的)爬取到的Item给Item Pipeline,存入数据库,持久化,如果数据不对,可重新封装成一个request请求,传给调度器。
- 9、(从第二步)重复直到调度器中没有更多地request,引擎关闭该网站
创建Scrapy项目
创建项目

C:Usersjingjing>scrapy startproject Myproject New Scrapy project 'Myproject', using template directory 'c:\program files\pyt hon36\lib\site-packages\scrapy\templates\project', created in: C:UsersjingjingMyproject You can start your first spider with: cd Myproject scrapy genspider example example.com
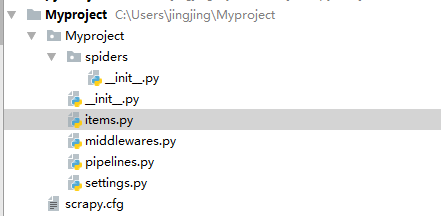
Myproject/ :项目的Python模块,将会从这里引用代码
Myproject/items.py :项目的目标文件,定义一些字段,这些字段用来临时存储你需要保存的数据。方便后面保存数据到其他地方
Myproject/pipelines.py :项目的管道文件,在pipelines.py中存储自己的数据
Myproject/settings.py :项目的设置文件
Myproject/spiders/ :存储爬虫代码目录,在spiders文件夹中编写自己的爬虫
创建item文件
item是保存爬取数据的容器,它的使用方法和字典类似。
# 创建爬取的数据 class MyprojectItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # # 课程金额 money = scrapy.Field() # 课程名称 title = scrapy.Field()
创建spider文件
spider是自己定义的类,Scrapy用它来从网页里抓取内容,并解析抓取的结果。
进入spider文件夹
C:UsersjingjingMyprojectMyprojectspiders>scrapy genspider "tz" "www.tanzhouedu.com" Created spider 'tz' using template 'basic' in module: Myproject.spiders.tz
tz.py
import scrapy import time from Myproject.items import MyprojectItem class TzSpider(scrapy.Spider): name = 'tz' # 必须项,每个爬虫项目的唯一名字,不能重复 allowed_domains = ['www.tanzhouedu.com'] # 允许爬取的域名,如果初始或后续的请求链接不是这个域名下的,则请求链接会被过滤掉 start_urls = ['http://www.tanzhouedu.com/mall/course/initAllCourse'] # 包含了Spider在启动时爬取的url列表,初始请求是由它定义的 OFFSET = 0 # 偏移量 def parse(self, response): items = MyprojectItem() node_list = response.xpath('//*[@id="newCourse"]/div/div/ul/li') if node_list: for node in node_list: items['money'] = node.xpath('./div/span/text()').extract_first() # 获得span标签的内容(extra_first字符串,extra列表) items['title'] = node.xpath('./div/a/@title').extract_first() # 获得a标签的title属性(extra_first字符串,extra列表) yield items # -->提交到engin,发送管道文件 self.OFFSET += 20 # 翻页 yield scrapy.Request(url='http://www.tanzhouedu.com/mall/course/initAllCourse?params.offset={}¶ms.num=20&keyword=&_={}'.format(str(self.OFFSET),str(int(time.time()*1000))),callback=self.parse) # -->提交到engin,请求调度器入列
Selector有四个基本的方法(点击相应的方法可以看到详细的API文档):
xpath(): 传入xpath表达式,返回该表达式所对应的所有节点的selector list列表 。css(): 传入CSS表达式,返回该表达式所对应的所有节点的selector list列表.extract(): 序列化该节点为unicode字符串并返回list。re(): 根据传入的正则表达式对数据进行提取,返回unicode字符串list列表。
使用item Pipeline
item Pipeline为项目管道,当item生成后,他会自动被送到item Pipeline进行处理,过滤保存数据
import json class MyprojectPipeline(object): def open_spider(self, spider): """ # spider (Spider 对象) – 被开启的spider # 可选实现,当spider被开启时,这个方法被调用。 :param spider: :return: """ self.file = open('tanzhou.json','w',encoding='utf-8') json_header = '{ "tanzhou_course":[' self.count = 0 self.file.write(json_header) # 保存到文件 def close_spider(self,spider): """ # spider (Spider 对象) – 被关闭的spider # 可选实现,当spider被关闭时,这个方法被调用 :param spider: :return: """ json_tail = '] }' self.file.seek(self.file.tell()-1) # 定位到最后一个逗号 self.file.truncate() # 截断后面的字符 self.file.write(json_tail) # 添加终止符保存到文件 self.file.close() def process_item(self, item, spider): """ # item (Item 对象) – 被爬取的item # spider (Spider 对象) – 爬取该item的spider # 这个方法必须实现,每个item pipeline组件都需要调用该方法, # 这个方法必须返回一个 Item 对象,被丢弃的item将不会被之后的pipeline组件所处理。 :param item: :param spider: :return: """ content = json.dumps(dict(item), ensure_ascii=False, indent=2) + "," # 字典转换json字符串 self.count += 1 print('content',self.count) self.file.write(content) # 保存到文件
json文件


修改配置settings.py
# Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = '"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"' # 头部信息,反爬 ITEM_PIPELINES = { # 注册管道 'Myproject.pipelines.MyprojectPipeline': 300, # 优先级,数字越小,优先级越高 }
运行spider文件
C:UsersjingjingMyprojectMyprojectspiders>scrapy crawl tz
详细代码


import scrapy # 创建爬取的数据 class MyprojectItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # # 课程金额 money = scrapy.Field() # 课程名称 title = scrapy.Field()
# -*- coding: utf-8 -*- import scrapy import time from Myproject.items import MyprojectItem class TzSpider(scrapy.Spider): name = 'tz' # 必须项,每个爬虫项目的唯一名字,不能重复 allowed_domains = ['www.tanzhouedu.com'] # 允许爬取的域名,如果初始或后续的请求链接不是这个域名下的,则请求链接会被过滤掉 start_urls = ['http://www.tanzhouedu.com/mall/course/initAllCourse'] # 包含了Spider在启动时爬取的url列表,初始请求是由它定义的 OFFSET = 0 # 偏移量 def parse(self, response): items = MyprojectItem() node_list = response.xpath('//*[@id="newCourse"]/div/div/ul/li') if node_list: for node in node_list: items['money'] = node.xpath('./div/span/text()').extract_first() # 获得span标签的内容(extra_first字符串,extra列表) items['title'] = node.xpath('./div/a/@title').extract_first() # 获得a标签的title属性(extra_first字符串,extra列表) yield items # -->提交到engin,发送管道文件 self.OFFSET += 20 # 翻页 yield scrapy.Request(url='http://www.tanzhouedu.com/mall/course/initAllCourse?params.offset={}¶ms.num=20&keyword=&_={}'.format(str(self.OFFSET),str(int(time.time()*1000))),callback=self.parse) # -->提交到engin,请求调度器入列
# -*- coding: utf-8 -*- # Scrapy settings for Myproject project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://doc.scrapy.org/en/latest/topics/settings.html # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html # https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'Myproject' SPIDER_MODULES = ['Myproject.spiders'] NEWSPIDER_MODULE = 'Myproject.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = '"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"' # 头部信息,反爬 # Obey robots.txt rules ROBOTSTXT_OBEY = True # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs #DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', # 'Accept-Language': 'en', #} # Enable or disable spider middlewares # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # 'Myproject.middlewares.MyprojectSpiderMiddleware': 543, #} # Enable or disable downloader middlewares # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html #DOWNLOADER_MIDDLEWARES = { # 'Myproject.middlewares.MyprojectDownloaderMiddleware': 543, #} # Enable or disable extensions # See https://doc.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, #} # Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { # 注册管道 'Myproject.pipelines.MyprojectPipeline': 300, # 优先级,数字越小,优先级越高 } # Enable and configure the AutoThrottle extension (disabled by default) # See https://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = 'httpcache' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
import json class MyprojectPipeline(object): def open_spider(self, spider): """ # spider (Spider 对象) – 被开启的spider # 可选实现,当spider被开启时,这个方法被调用。 :param spider: :return: """ self.file = open('tanzhou.json','w',encoding='utf-8') json_header = '{ "tanzhou_course":[' self.count = 0 self.file.write(json_header) # 保存到文件 def close_spider(self,spider): """ # spider (Spider 对象) – 被关闭的spider # 可选实现,当spider被关闭时,这个方法被调用 :param spider: :return: """ json_tail = '] }' self.file.seek(self.file.tell()-1) # 定位到最后一个逗号 self.file.truncate() # 截断后面的字符 self.file.write(json_tail) # 添加终止符保存到文件 self.file.close() def process_item(self, item, spider): """ # item (Item 对象) – 被爬取的item # spider (Spider 对象) – 爬取该item的spider # 这个方法必须实现,每个item pipeline组件都需要调用该方法, # 这个方法必须返回一个 Item 对象,被丢弃的item将不会被之后的pipeline组件所处理。 :param item: :param spider: :return: """ content = json.dumps(dict(item), ensure_ascii=False, indent=2) + "," # 字典转换json字符串 self.count += 1 print('content',self.count) self.file.write(content) # 保存到文件