0.展示PTA总分


{kind=link}
{kind=link}
1.本章学习总结
1.1 学习内容总结
1.while语句和do while 语句
- 构成:
- 表达式:是进行循环的条件,可以是任意合法的表达式;
- 循环体语句:循环体语句只能是一条语句,是每次进入循环要做的操作,其中必须包含能最终改变循环条件真假的操作。
- 一般形式:
- while语句
while(表达式)
循环体语句;
- do while语句
do{
循环体语句;
} while(表达式);
- while和do while语句的异同:
- 异:while语句是先判断是否符合循环条件,如果符合则进入循环,否则则不进入循环;do while语句是先进入一次循环,再判断是否符合循环条件,符合则继续循环,不符合则退出循环;do while至少进行一次循环,while可能循环一次也不进行。如果第一次循环条件不同时,while语句不循环,而do while循环执行一次。
- 同:如果第一次循环条件相同则执行的循环次数相同。
- 三种循环语句使用:
- for语句:当循环的次数可以确定时,用for语句比较清晰简便,循环4个组成成分(初始化,条件控制,重复的操作以及通过改变循环变量的值最终改变条件真假性,使循环能够结束)一目了然;例如:计算n的阶乘;
- while 语句和do while语句:当循环次数不明确的时候,而是由某一项的值来控制循环或者需要设置一个伪数据来作为循环结束的标志时,用while语句和do while语句比较方便;例:用格雷戈里公式求π的近似值;当循环条件需要在循环体中明确时,用do while语句,当循环条件在进入循环时明确,则使用while。
2.break语句和continue语句
- break语句:作用是强制循环结束,一般和if语句配合使用,即条件满足时,才执行break跳出循环;否则若break无条件执行,意味着永远不会执行循环语句break语句后面的其他语句;break除了可以终止循环,还用于switch语句;
- continue语句:作用是跳过循环体重continue后面语句,继续进行下一次循环,一般也是和if配套使用,continue只能作用于循环;
- 区别:break是结束循环,continue是跳过后面的语句继续循环。
3.嵌套循环
- 要注意外层循环和内层循环的条件初始化,如果放错了位置,得到的结果很可能不会是你想要的;
- break可以跳出循环,但是break只能跳出break当前所在的这层循环,如果要跳出多层循环需要用多个break语句,也可以用goto语句,但是goto容易破坏程序流程结果,可读性差,也可能会使程序难以维护,所以大部分情况下不建议用goto。
4.课堂拓展
- 造scanf函数吸收空格和换行符:因为空格和换行也是字符,在读入一个字符时要注意不可以随意的输入空格和换行符,因为输入一串字符,getchar一次只能接收一个字符,scanf函数中的一个%c也只能接收一个字符,剩下的要放在键盘缓冲区中,等待下一个getchar或者scanf的读入。当我们不需要读入空格或者换行符时,我们可以造一个
scanf(" %c",&c)(%c前面有一个空格),这样可以过滤键盘缓冲区留下的空格和回车,或者我们可以多造一个getchar来读入空格和回车,也可以用函数fflush(stdin)来清除缓冲区的字符。 - 在阅读网站上别人优秀的代码时,我们经常会看到作者运用这样的一个模板:
int main()
{
while(i)
{
...
}
return 0;
}
好处是:这样可以防止某非法数据进入下面的数据处理。
1.2 本章学习体会
- 1.关于循环条件的设置,刚开始有点晕头转向的,后来通过多练pta的题型,现在已经基本掌握了应该如何设置循环条件;
- 2.起初刷单循环的题目时,就觉得循环这一块有点难度,后来更令人头秃的嵌套循环出现了...

- 3.语言表达能力差,应该是预习做的不够,对定理和作用了解的不够充分,这点还是需要改进;
- 4.这两周的代码量为1328,代码量还可以再多一些。
2.PTA实验作业
2.17-6 水仙花数 (20 分)
2.1.1 伪代码
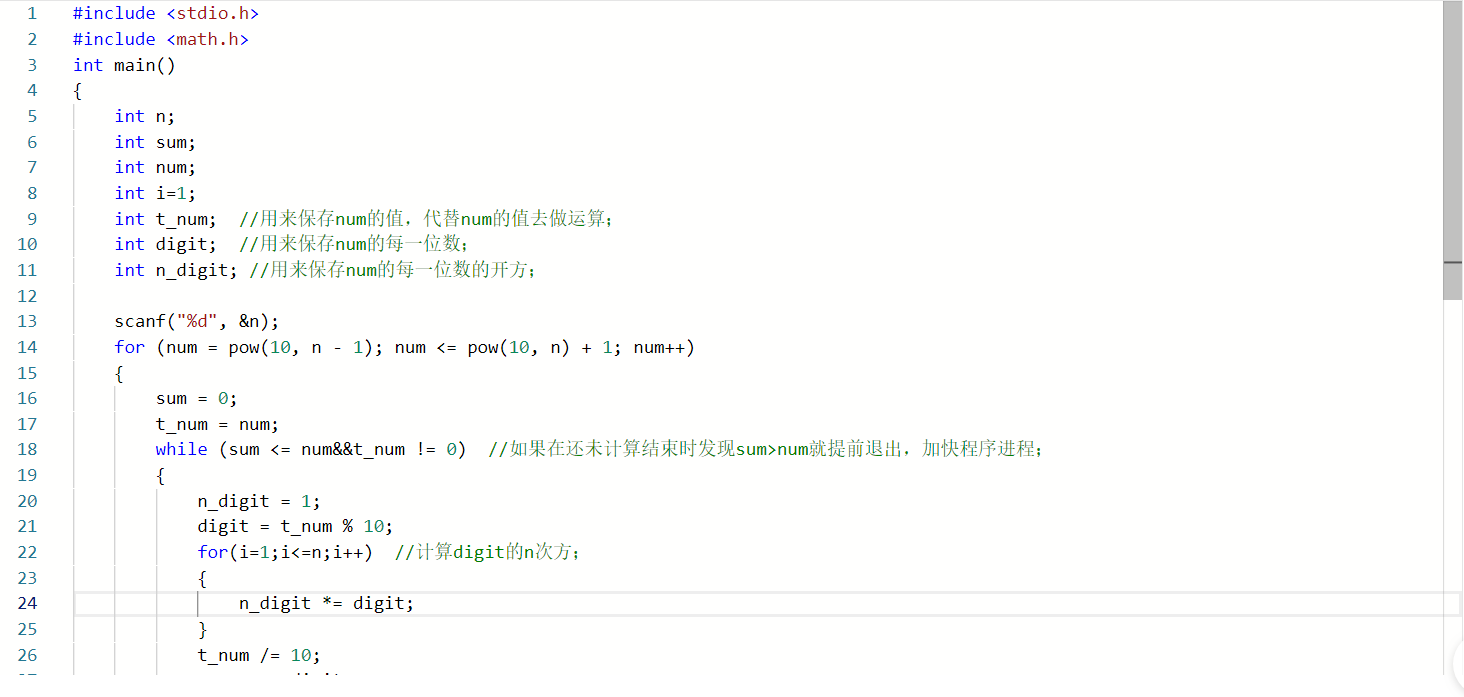
定义变量n来放整数的位数,sum来放整数每位数的n次方相加的和,num来放每个整数,t_num放num的值,digit放整数的每一位上的数,n_digit放digit的n次方的值。
输入位数
for num=pow(10,n-1) to pow(10,n)+1
每次新取一个整数来判断是否为水仙花数时,对sum初始化为0
将新的num赋给t_num;
while(sum<=num&&t_num!=0)
对n_digit初始化为1
取t_num最后一位数,赋值给digit
for i=1 to n
对n_digit乘以digit并赋值给n_digit
end for
t_num除以10,去掉t_num的最后一位数
sum加上每一位数的n次方
end while
if sum=num then
输出水仙花数
end for
2.1.2 代码截图

2.1.3 造测试数据
| 输入数据 | 输出数据 | 说明 |
|---|---|---|
| 3 | 153 370 371 407 | 最小范围 |
| 7 | 1741725 4210818 9800817 9926315 | 最大范围 |
| 5 | 54748 92727 93084 | 中间数据 |
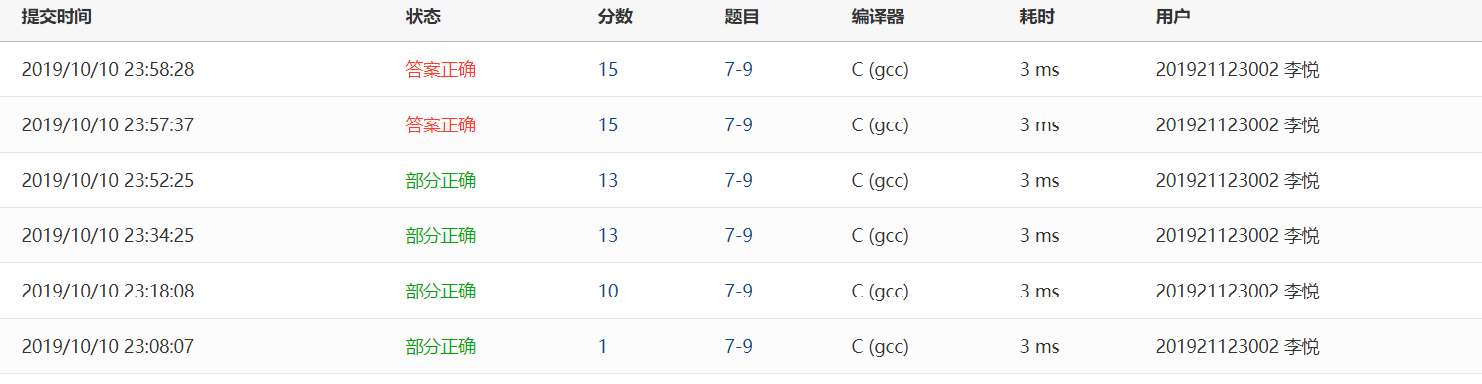
2.1.4 PTA提交列表及说明
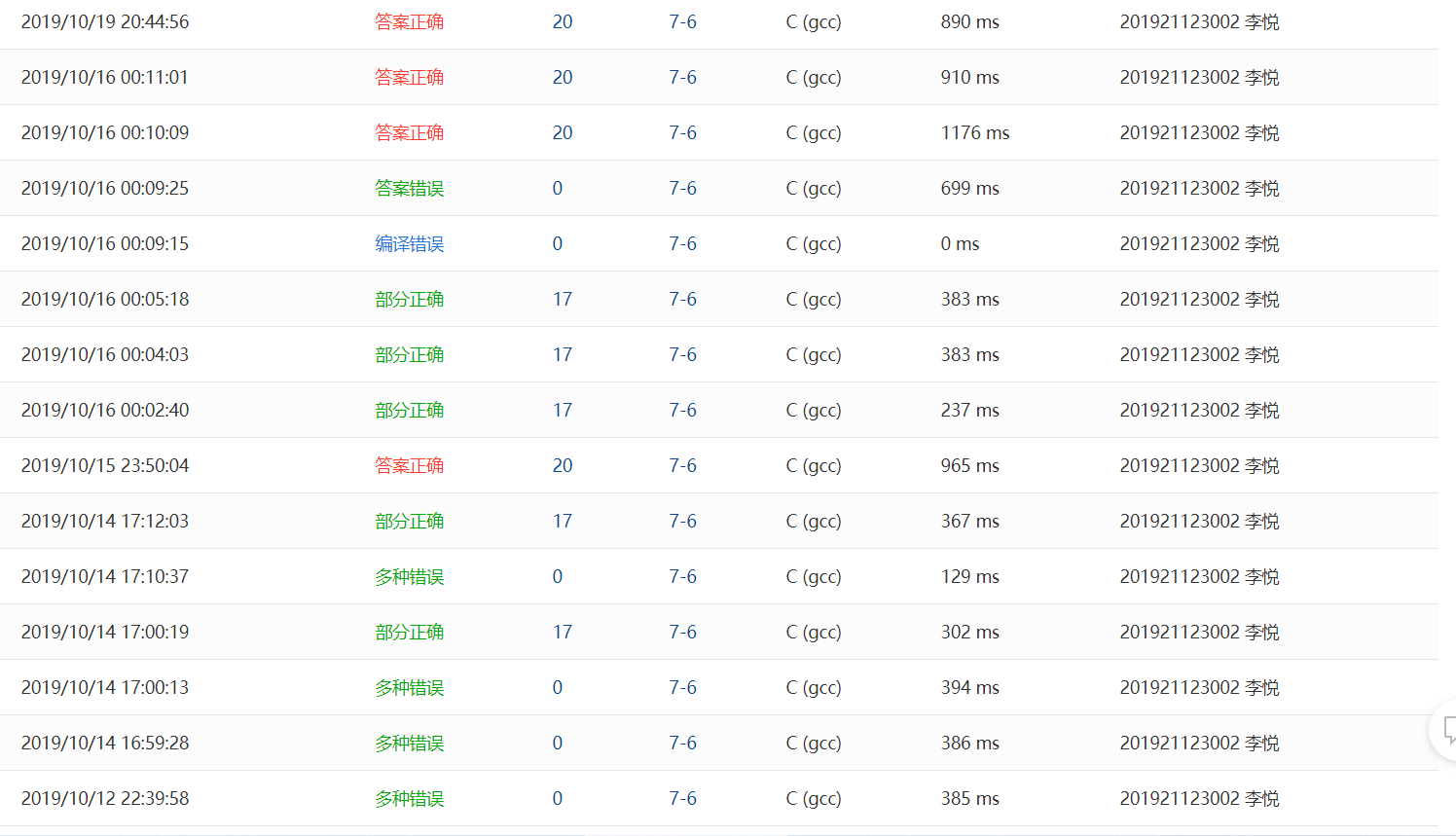
提交列表说明:
1.多种错误:在输出的语句中,给num前面加上了读地址的符号'&',导致最后输出num的值是num的地址;
2.部分正确:当n为7时,运行超时,原因是自己写的代码做的运算太多了,需要给计算机减轻一些负担,借鉴了一下网上的代码,发现在计算sum的值时,如果在计算过程sum的值已经大于num的话就直接退出,判断下一个数,而且用for语句计算digit的n次方比调用pow函数,运行效率更快;
3.编译错误:第24行表达式后面的分号忘记打了。
2.2 龟兔赛跑 (20 分)
2.2.1 伪代码
定义变量rabbit来放兔子跑的路程,turtle放乌龟跑的路程,time放输入的总时间,i放已经经过的时间。
输入时间
for i=1 to time
乌龟跑的路程每分钟加3
兔子跑的路程每分钟加9
if i%10=0 then
if 兔子跑的路程>乌龟跑的路程
if 如果经过的时间+30<总时间 then
乌龟跑的路程加上90
经过的时间再加上30
end if
else
乌龟跑的路程加上剩下的时间能跑的路程
退出循环
end else
end if
end if
end for
if 兔子跑的路程大于乌龟跑的路程 then
输出^_^和兔子的路程
end if
else if 兔子跑的路程小于乌龟跑的路程 then
输出@_@和乌龟的路程
end else if
else 就是兔子和乌龟跑的路程一样多 then
输出-_-和乌龟或者兔子跑的路程
end else
2.2.2 代码截图
借鉴老师的代码:


自己之前打的:



2.2.3 造测试数据
| 输入数据 | 输出数据 | 说明 |
|---|---|---|
| 30 | -_- 90 | 兔子休息时,兔子和乌龟平局 |
| 90 | -_- 270 | 兔子奔跑时,兔子和乌龟平局 |
| 96 | ^_^ 324 | 兔子奔跑时,兔子赢了 |
| 111 | ^_^ 360 | 兔子在休息时,兔子赢了 |
| 82 | @_@ 246 | 兔子在奔跑时,乌龟赢了 |
| 129 | @_@ 387 | 兔子在休息时,乌龟赢了 |
| 0 | -_- 0 | 比赛还未开始,兔子和乌龟还未开始跑 |
2.2.4 PTA提交列表及说明
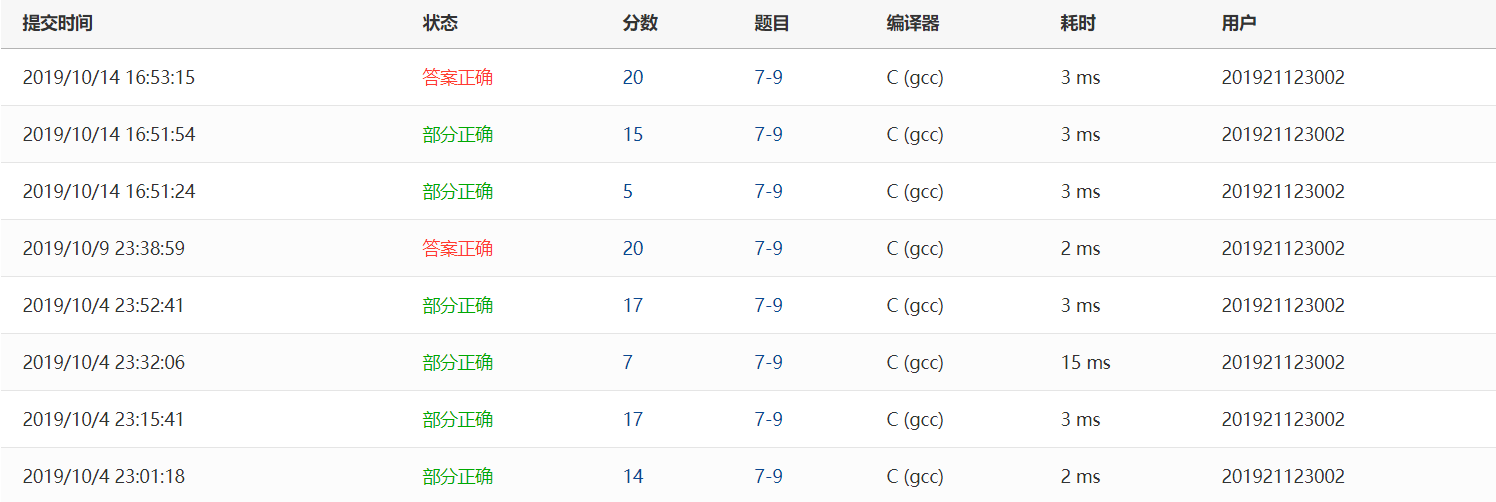
提交列表说明:
部分正确:
1.在下面的答案正确是我自己思考的代码,之前的部分正确是因为思路错误,计算总共过了几个40分钟,误以为每40分钟是一个循环;然后在纸上重新写了一遍过程,发现兔子不是每次只要跑10分钟就一定会追上乌龟;于是我把时间分为n个10分钟,用count来保存n,用count来做循环;
2.在上面那个答案正确的是借鉴老师的代码,在借鉴过程中出现的部分正确是因为少了一个兔子跑的比乌龟快的条件和计算乌龟路程的表达式错误;
对比:两个代码相比较,自己写的代码思路比较复杂,将问题分成了多个部分来分别讨论,代码量较多,可读性较差。
2.3单词长度 (15 分)
2.3.1 数据处理
定义变量ch保存读入的字符,length保存每一个单词的长度,count计算空格的个数,flag判断是否要输出,one计算单词个数
while ((ch=getchar())!='.')
if 输入的字符不为空格 then
单词长度加1
flag变为1表示可以输出单词长度
把保存空格个数count的值归零
end if
else
计算空格的个数
if 空格个数为1并且可以输出单词长度 then
计算单词个数
if 单词个数为1 then
输出单词长度,前面不带空格
end if
else
输出单词长度,前面带空格
end else
输出一个单词长度后,把flag归0,变为不输出状态
end if
把length归为0
end else
if 为可输出状态并且空格个数为0 then
if 单词个数不为0 then
输出单词长度,前面带空格
end if
else
输出单词长度,不带空格
end else
end if
2.3.2 代码截图


2.3.3 造测试数据
| 输入数据 | 输出数据 | 说明 |
|---|---|---|
| it. | 2 | 只有一个单词,左右中间没有多余的空格 |
| it . | 2 | 只有一个单词,左右中间有多余的空格 |
| it is a good day. | 2 2 1 4 3 | 一条完整的语句,左右中间没有多余的空格 |
| it is a good day . | 2 2 1 4 3 | 左右中间没有多余的空格 |
| it's a good day. | 4 1 4 3 | 有其他的符号,左右中间没有多余的空格 |
| it's a good day. | 4 1 4 3 | 有其他符号,左右中间有多余的空格 |
2.3.4 PTA提交列表及说明
提交列表说明:
部分正确:没有考虑到语句左右两边和中间如果有多个空格的可能性,还有如果只有一个单词,输出的数据末尾不能带空格的问题。
3.代码互评
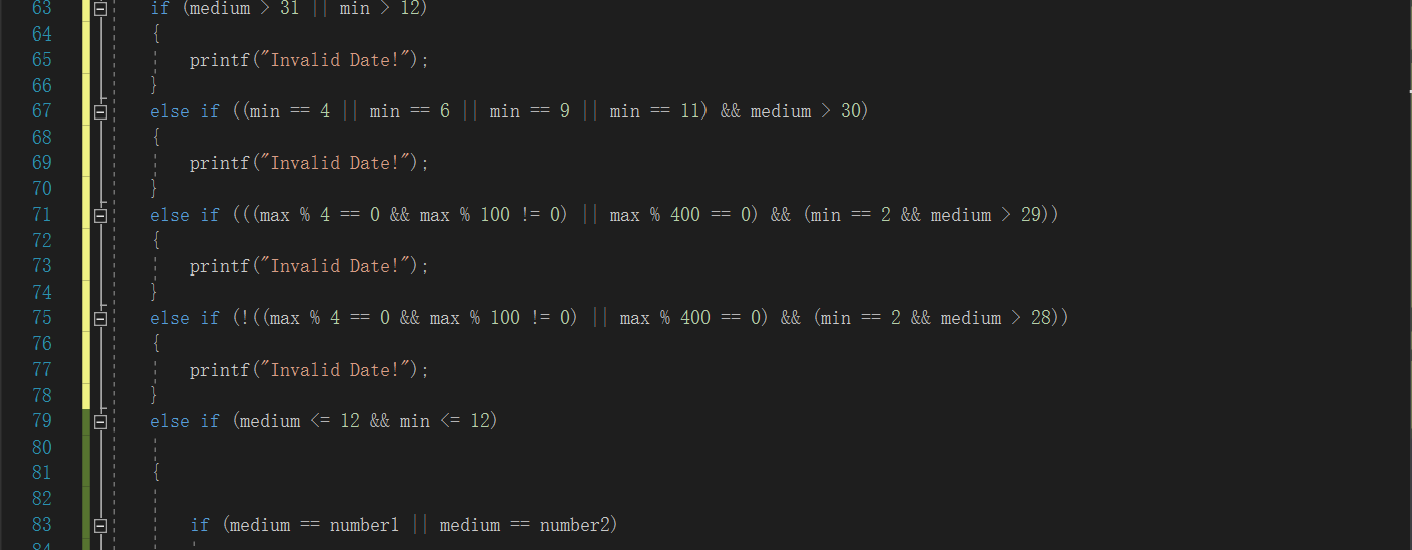
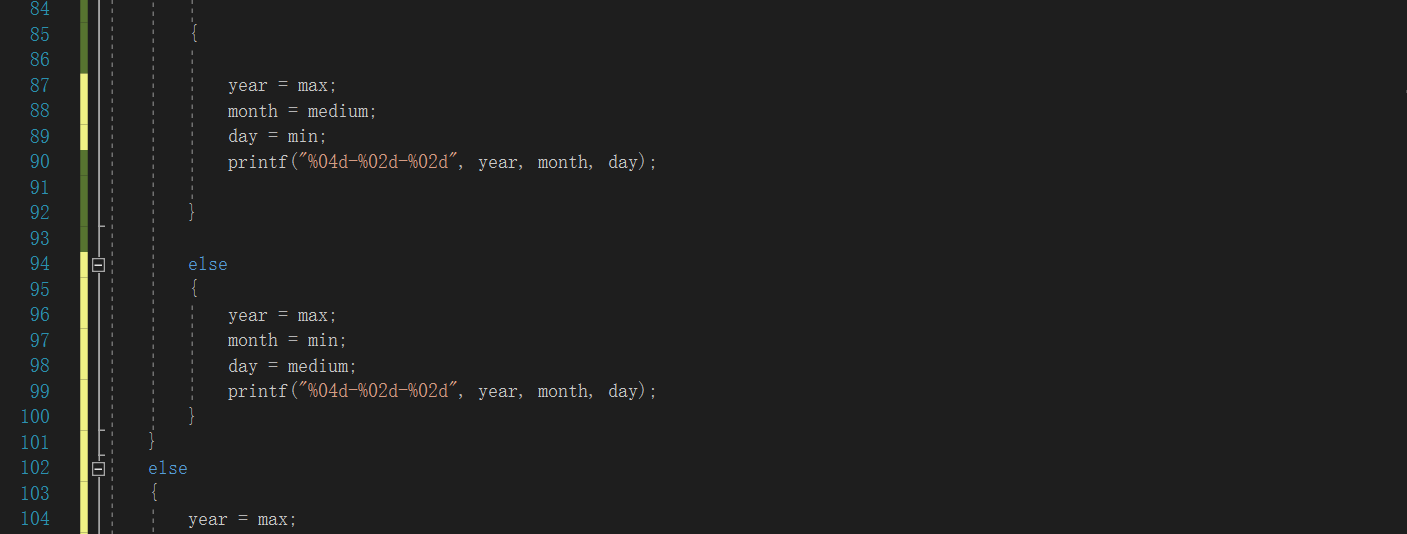
3.1任务06-02-01 于龙遇见日期,又哭了!
3.1.1d代码截图
同学代码:



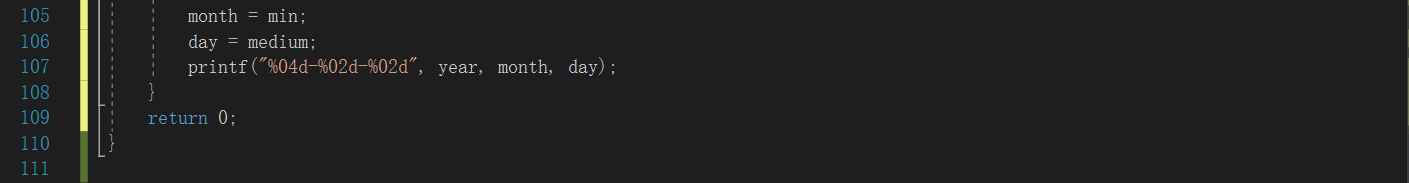
我的代码:


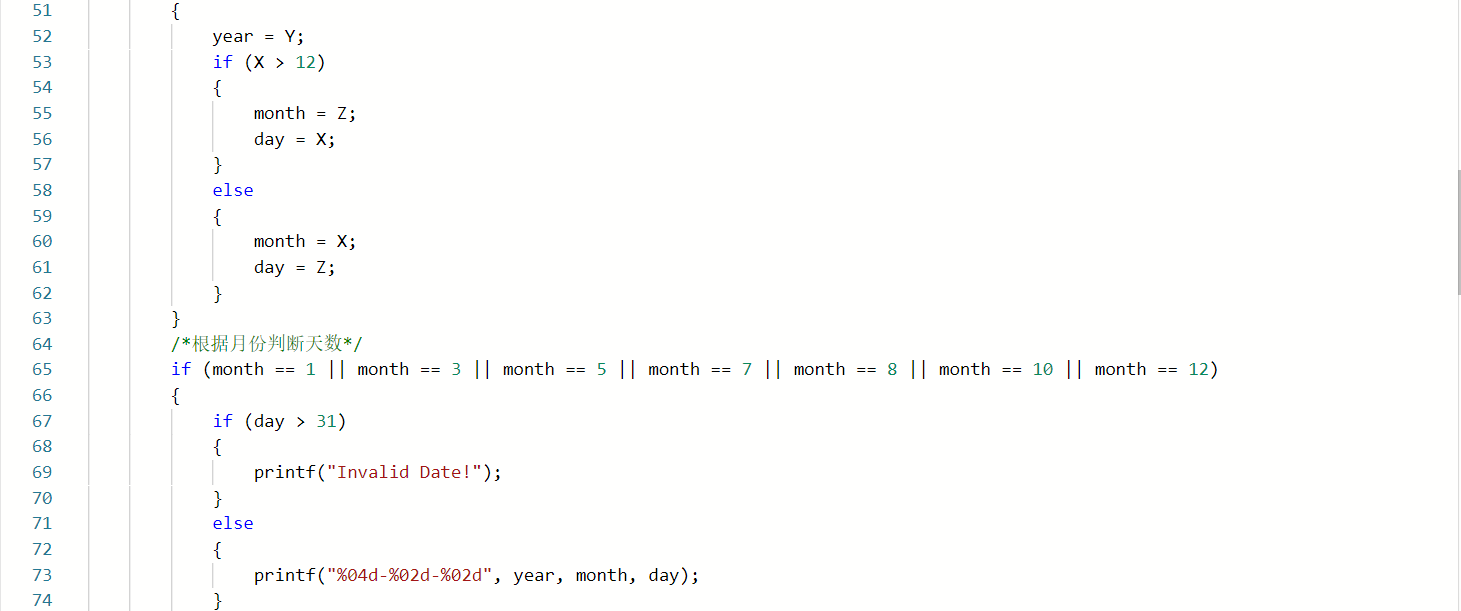
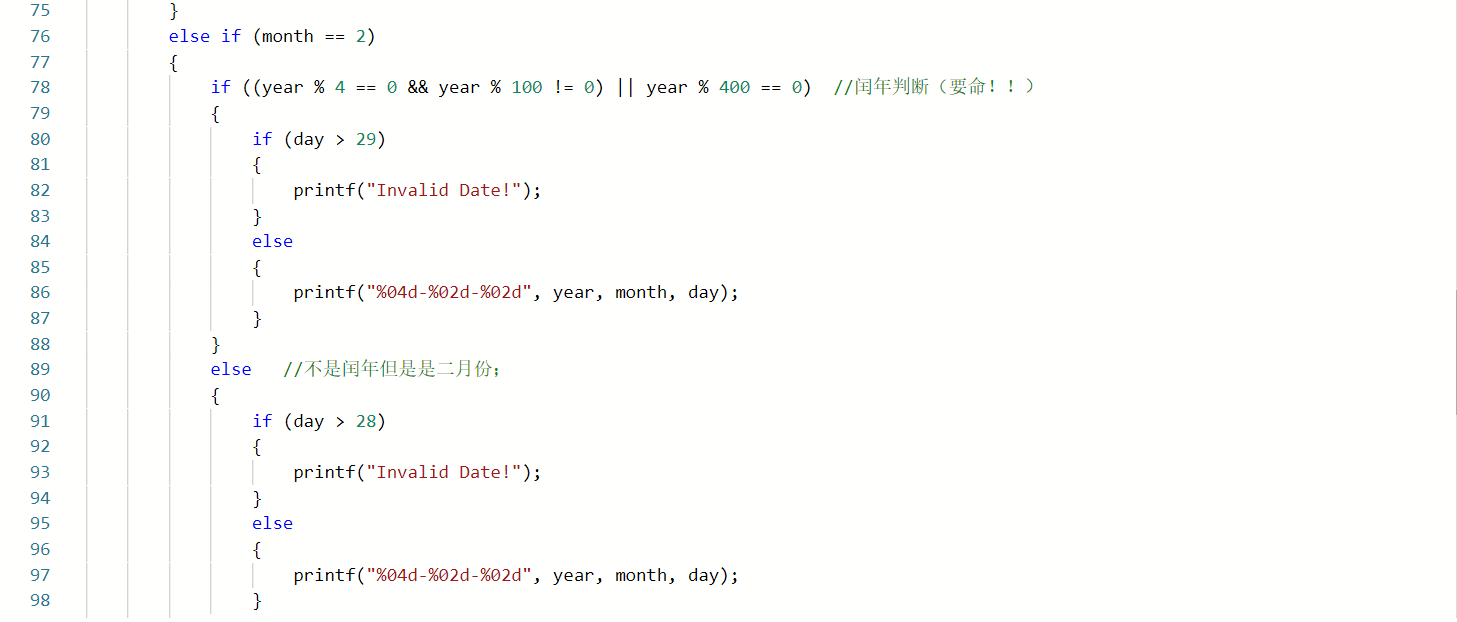
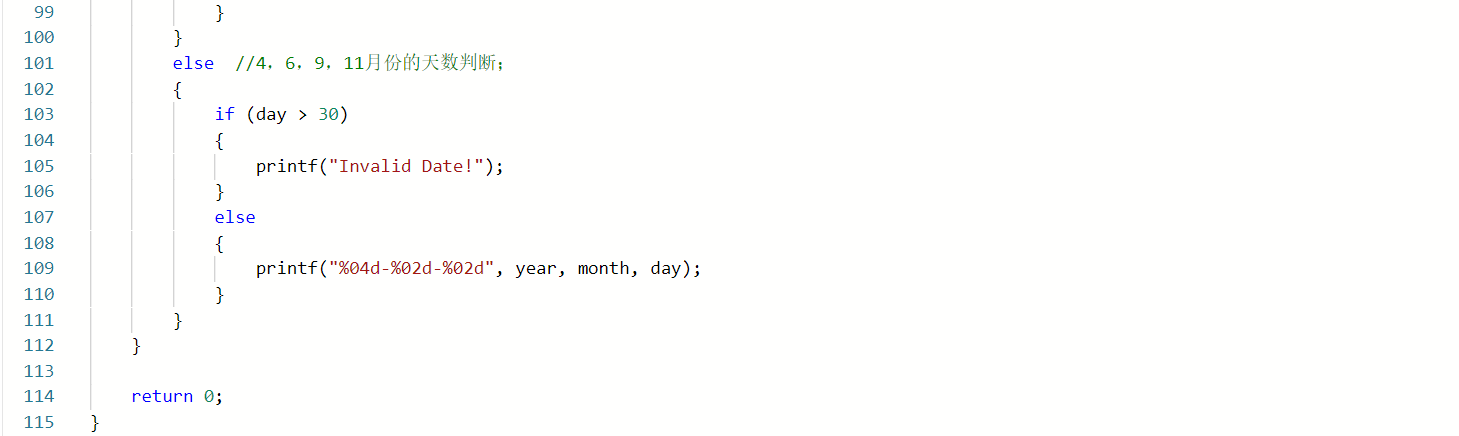
3.1.2代码对比
- 1.相同:
- 都运用了二分支和多分支的结构(if语句,if else语句,else if语句),还有分支的嵌套;
- 我们都对三个数字大小进行判断,并且将x,y,z的值赋给year,month,day,然后开始判断是否为合法的数据。
- 2.不同:
- 判断非法日期的方法不同,我的代码是先把三个数都大于12的情况排除掉,因为如果三个数都大于12,一定非法,然后再判断其他闰年,月份,天数等不符合的非法的情况,而这位同学则是按照数据的大小,然后再判断闰年,月份,天数等不符合的情况;所以两端代码相比,这位同学代码中使用的else if语句比较多;
- 我们对输入三位数大小判断处理不一样,我的是先找出三个数中的最大值,赋值给year,然后依次判断较小的两位数应该赋给day还是month;而这位同学是把三个数据排序完,然后赋值给year,month,day;
- 相比较来说,这位同学的代码将非法和合法的日期分成两部分,看起来比较清晰,思路明了,而自己的代码在思路上有些跳脱,读起来可能没有这位同学清晰。
3.2 单词长度
3.2.1d代码截图
同学代码:
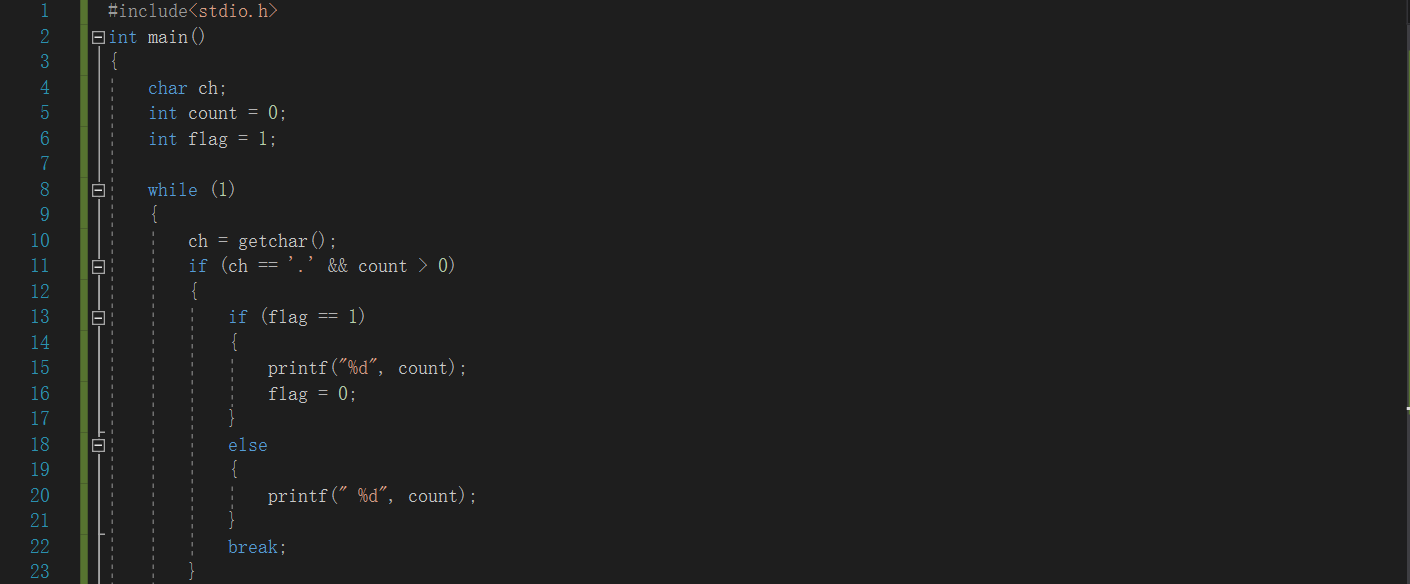
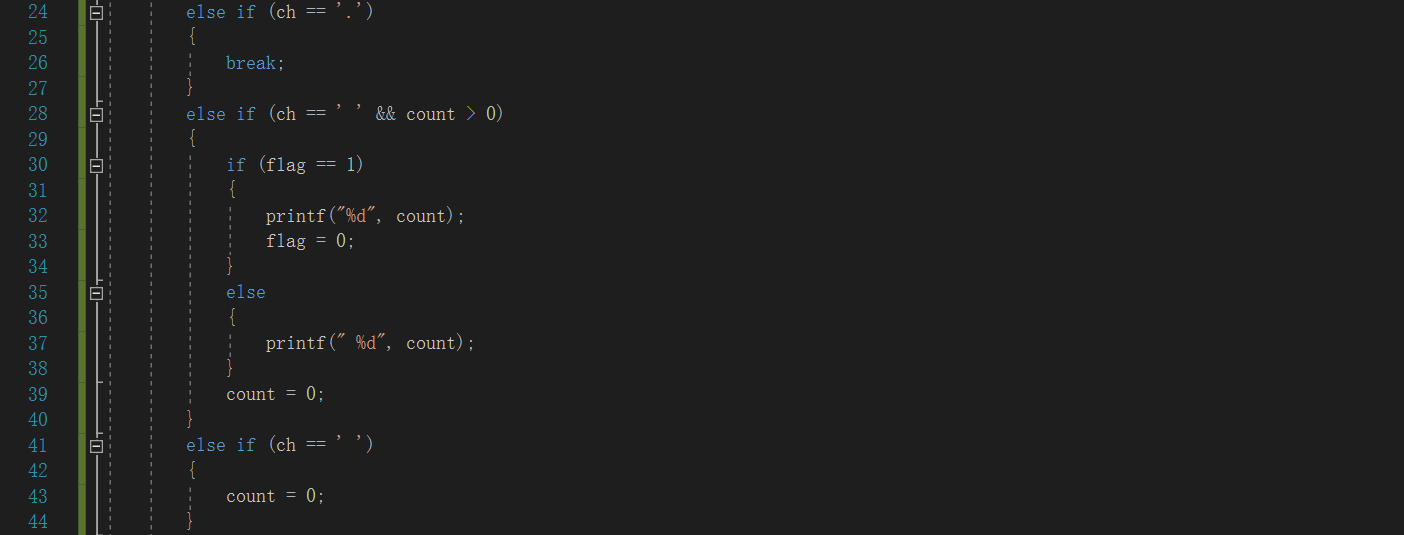

我的代码:
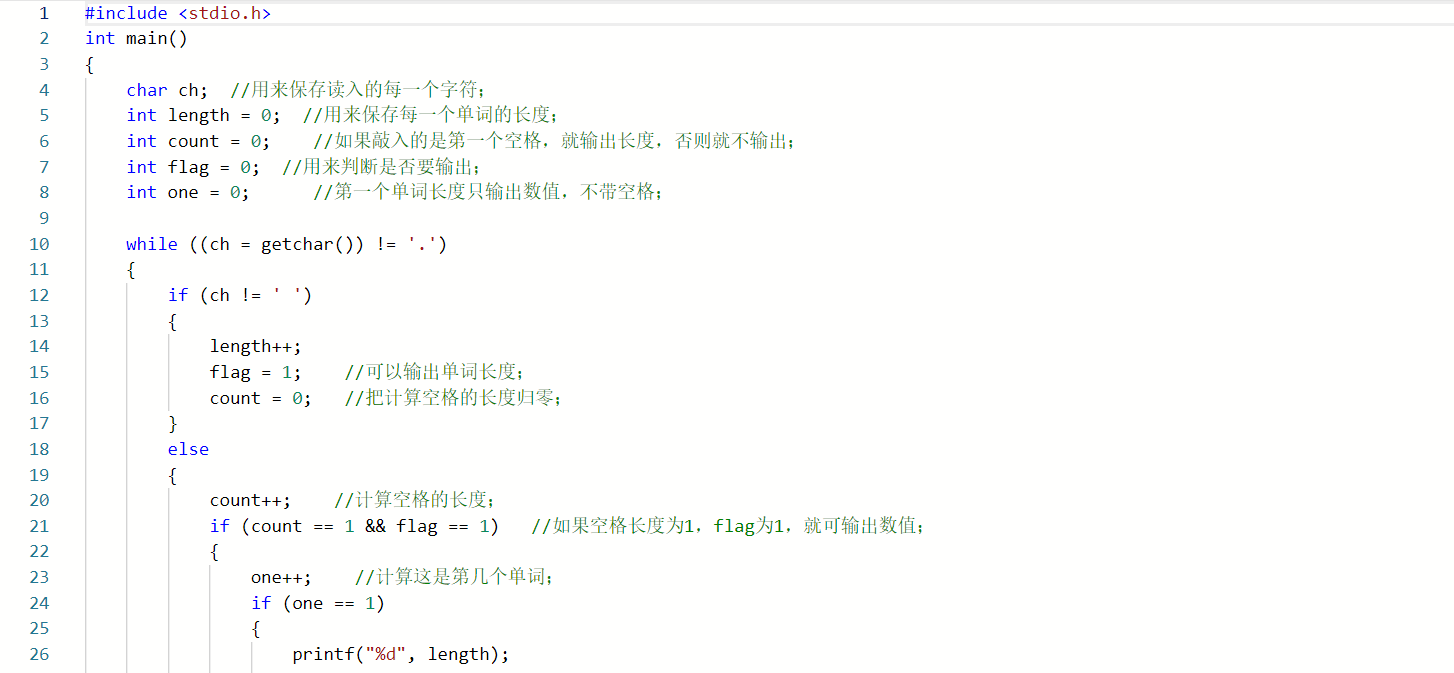

3.2.2代码对比
- 1.相同:
- 都是运用while和分支结构来设计程序。
- 2.不同
- 这位同学的开头使用一个恒真语句while(1),以此来进入循环,也就是说结束标志‘.’,也会进入循环,然后进行输出单词长度;而我的代码则是结束标志‘.’不进入循环,这样会导致最后一个单词的单词长度无法输出,于是我在循环外面又添上一个如果遇到结束标志,结束标志前没有空格,则输出单词长度的语句;
- 我设置了一个f变量lfag来判断是否要输出单词的数值,看了同学的代码以后我觉得好像没有必要设置flag,只要判断单词长度是否大于0就可以了,于是我把flag去掉,运行了一下:


是OK的!! - 这位同学用变量flag来判断输出的数是否为第一个,当第一次输出单词长度(不输出空格)时,改变flag的值,使他进入另外一个前面有输出空格的输出语句,而我则是设置了一个变量one来计算单词的个数,每遇到一个单词就加上1,如果one为1就进入不输出空格的输出语句,如果one为大于1的数则进入输出空格的输出语句;相比较而言,我的程序代码的运算量增加了,运算效率减慢了;
- 康康别人的代码和我的代码,感觉我的代码没有一个完整的思路,很多东西都是后来拼凑上去,像补丁一样的感觉,读起来有点费力,变量设置过多且有些赘余,思维较紊乱,而这位同学的代码,合理利用现有的变量设置条件,代码量较少,计算机做的运算也比较少,效率较高,且运用了while的恒真语句,这样可以过滤掉一些非法的数值。