一:模式匹配中的特殊字符
1: 点号 .
匹配任何单个字符(换行符 除外)
2: 反斜线
转义字符,用于特殊符号前,使其失去特殊字符的作用变成普通字符
3: +
匹配该字符前面的字符(单个)至少一次;1次,2次...n次
4: *
匹配该字符前面的字符任意次:0次,1次...n次
5: ?
匹配该字符前面的字符0次或者一次
6: .*
匹配任意字符任意次(换行符除外)
7: {count}
匹配前面的字符count次
8: {min,}
匹配前面的字符至少min次
9: {min,max}
匹配至少min,至多max
10: *?
匹配该字符前面的字符任意次:0次,1次...n次,倾向于短字符,非贪婪量词
11: +?
匹配该字符前面的字符(单个)至少一次;1次,2次...n次,倾向于短字符,非贪婪量词
12: ()
模式分组字符 eg:/(perl)+/ #有()匹配模式是perl,没有括号,匹配模式是单个字符l;
1)借助模式分组,可以使用 umber的方向引用来引用括号内匹配的内容,n和括号内的组号匹配

2)perl 5.10可以使用g{number}这种形式的反向引用,n可以为负数

输出:
13: |
或,即匹配左右都可
14: 例子

输出:
二: 字符集
字符集是指一串可能出现的字符集合。通过写在方括号([ ])内来表示。只能用来匹配单个字符,但可以是方括号内列出的任意一个

输出:
1: 可以使用字符 - 进行简写; [0-9]表示0到9十个数字
2: 可以使用脱字符 ^ 匹配字符集外的字符
3: 字符集简写

说明:d 匹配任意的数字, w匹配任意的字母数字下划线 ,s匹配任意的空格,

4: 例子

输出: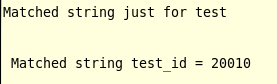
问题:test_id = 20010的ws+匹配一个字符多个空格;按道理匹配不了啊,但输出匹配成功
5: 常用字符集
/[dA-Fa-f]+/ :匹配16进制数
/dD/ :匹配任意字符
/^dD/ :什么字符都不匹配
四: 模式匹配操作符与修饰符
1: 操作符
在前面的介绍与例子中,我们使用 // 来进行匹配(实际上是m//);
模式匹配操作符可以使用任意成对的定界符,当使用斜线作为定界符时,开头的m可以省略
eg:m(fred),m<fred>,m{fred},m[fred]
m%http://%
2: 修饰符(在操作符后面,其实与操作符的/符号合用)
1)/i
进行模式匹配时,将不区分大小写
2)/s
模式中的点号将匹配包括换行符在内的任意字符(注意与s区分开来,s是字符集里匹配任意的空格的简写)
3)/x
忽略空白符,使用/x修饰符可以在模式里面随意加上空白,使其更容易阅读。
五: 锚位
1: ^
标志字符串的开头
2: $
标志字符串的末尾,eg:/^s*$/
3: /b 指定特定的单词
单词(w+)锚位,匹配任何单词的收尾
4: /B
非单词锚位,匹配所有/b不能匹配的位置
5: 例子

输出:
六: 绑定操作符=~
默认情况下,模式匹配的对象的$_,绑定操作符=~用于告诉perl拿右边的模式匹配左边的字符串,而不是匹配$_变量中的字符串

七: 模式串中的变量内插
例如:
my $val = "just";
my $val2 = "This is just a test example";
if ($val2 =~ /($val)/) { .... } #正则表达式中的变量内插,if ($val2 =~ /$(val)/)也可。
八: 捕获
把圆括号内的字符串暂时记忆下来的能力,如果有多个圆括号,就有多个捕获。捕获变量都是标量变量,依次为$1,$2...$n
1: 捕获周期
捕获变量通常能存活到下次成功的模式匹配为止,即失败的匹配不会改动上次工程匹配时捕获的内容,而成功时会将它们重置。如果在数行之外使用捕获变量,最好将捕获变量的值复 制到一个一般的变量里

输出:
2: 不匹配模式
一般情况下,模式使用的圆括号都会捕获部分的匹配串到捕获变量中,但若perl正则表达式允许使用括号但不做捕获(不捕获括号),需要在左括号的后面加上问号和冒号(?:)。
3: 命名捕获
管理$1,$2...是比较困难的,尤其是对比较复杂的正则表达式而言。Perl5.10引入了正则表达式命名捕获的概念。
在命名捕获中,捕获结果保存在%+的特殊哈希中;模式加标签的写法是(?<LABEL>PATTERN),访问为$+{LABEL},可使用g{LABEL}或k{LABEL}反向引用。
例子:

输出: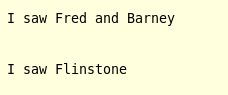
4: 自动匹配变量
$&:匹配括号的内容;$`:匹配内容前的字符;$’:匹配内容后的值(包括空格逗号等)
九: 替换
1: s///
前两个//里是要替换的字符,后两个//里是替换的字符;返回布尔值,替换成功时为真;只替换一个值
2: /g
全局替换;常写在s///后面,/g的斜线省略

输出:

3: 不同的替换界定符
和m//一样,s///操作符也可以使用其他的定界符
1)使用没有左右之分的非成对符号,跟s///一样,只需重复三次即可;eg:s#Barney#Fred#
2)使用有左右之分的成对符号,必须使用两对,一对圈引模式,一对圈引替换模式。圈引模式与圈引替换模式不一定要相同
eg:s{barney}{fred};s[barney][fred];s<fred>#barney#
4: 替换修饰符
/g(全局替换)
/i,/s,/x (四(2)同)
/m 使模式匹配字符串内的换行符
5: 大小写转换

例子:

输出:
十: split操作符
根据指定的分隔符拆开一个字符串,返回子串的列表(即将一个字符串分解为多个)。尤其适用于处理被制表符,冒号,空白或其他符号分割的数据
1: 语法规则
@split = split /separator/,$string or @split = split( /separator/,$string)
split会保留开头处的空字段,并省略结尾处的空字段
2: 例子

输出: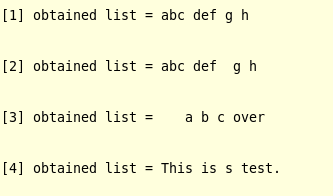
说明:多余的冒号会被当成空字符
十一: join函数
将多个字符串片段合并成一个字符串
my $result = join $glue,@pieces; or my $result = join ($glue,@pieces)

输出:
十二: 列表上下文中的m//
一般情况下,模式匹配操作符m//返回的是布尔值,如果在列表上下文中使用模式匹配操作符,将返回所有捕获变量的列表
eg:my $test = "hello,there,neighbor";
my ($first,$second,$third) = ($test = ~ /(S+) (S+), (S+)/); 大写S是小写s补集。
十三: 命令行执行perl
perl -p -i.bak -w -e 's/Randall/Randal/g' fred*.dat

十四:debug perl脚本
1)在程序头添加-d或者在终端perl -d filename.pl;打开debug模式
2)DB<1> l :list the next few lines;p $variable name: 输出变量值; q:quit;
r:从子函数中返回; R:再次运行; n:单步执行,不进入子函数(F10)
s:单步执行(F11),进入子函数;
b:放断点,如b 20 在第二十行放断点 ; c:运行到第一个断点处