一、实验目标
理解数据挖掘的基本概念,掌握基于Weka工具的基本数据挖掘(分类、回归、聚类、关联规则分析)过程。
二、实验内容
- 下载并安装Java环境(JDK 7.0 64位)。
- 下载并安装Weka 3.7版。
- 基于Weka的数据分类。
- 基于Weka的数据回归。
- 基于Weka的数据聚类。
- 基于Weka的关联规则分析。
三、实验步骤
1.下载并安装Java环境(JDK 7.0 64位)
(1)搜索JDK 7.0 64位版的下载,下载到本地磁盘并安装。
(2)配置系统环境变量PATH,在末尾补充JDK安装目录的bin子目录,以便于在任意位置都能执行Java程序。
2.下载并安装Weka 3.7版
3.基于Weka的数据分类
(1)读取“电费回收数据.csv”(逗号分隔列),作为原始数据。
读取文件后,将一些对数据分析无用的属性删除。
首先,删除CONS_NO(用户编号),用户编号是用来标识用户的,对数据分析没用。
然后,发现TQSC(欠费时长)为YMD(年月日)与RCVED_DATE(实收日期)之差,故删去YMD与RCVED_DATE。
其次,CUISHOU_COUNT(催收次数)全为0,删去;YM(年月)对数据分析无用,删去。
(2) 数据预处理:
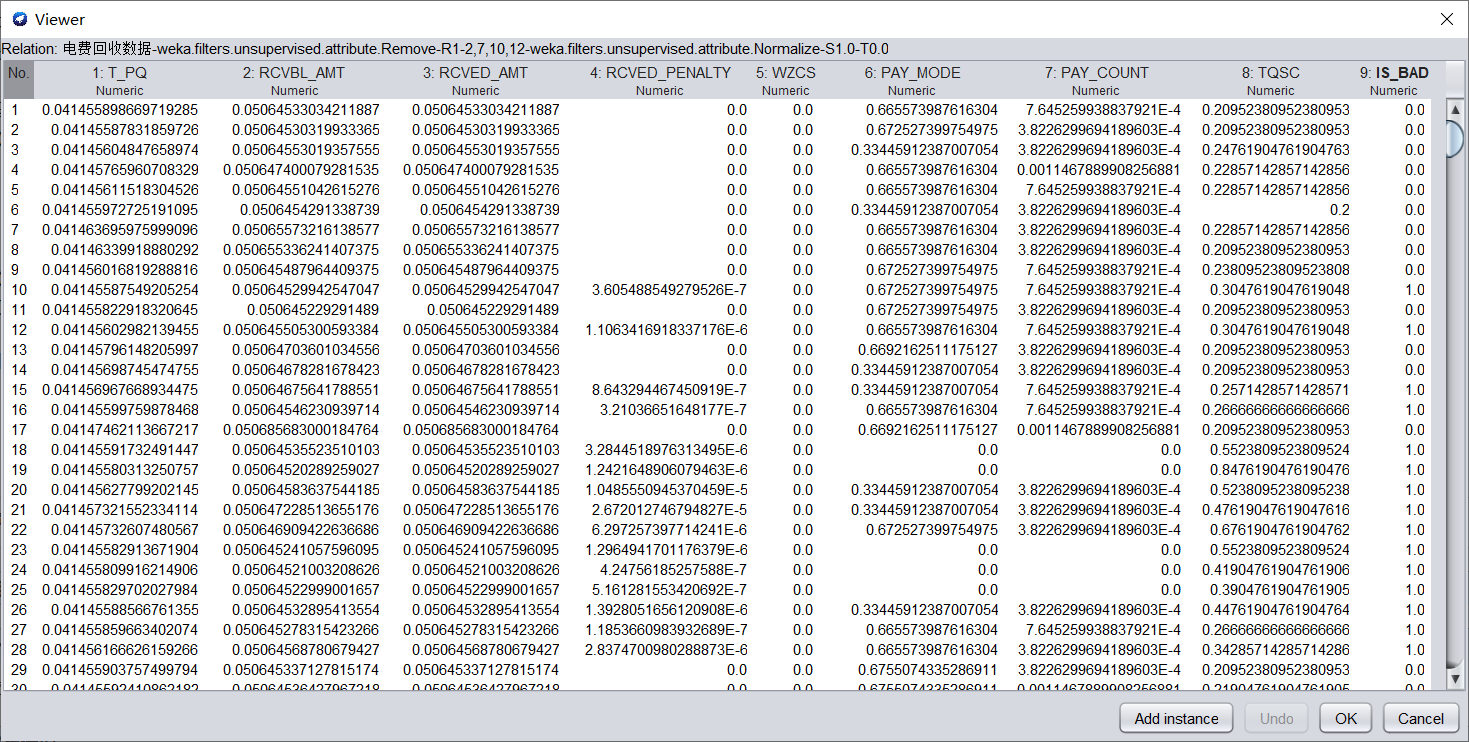
a)将数值型字段规范化至[0,1]区间。
在Filter中选择weka.filters.unsupervised.attribute.Normalize,进行归一化。归一化的数据如下图所示。
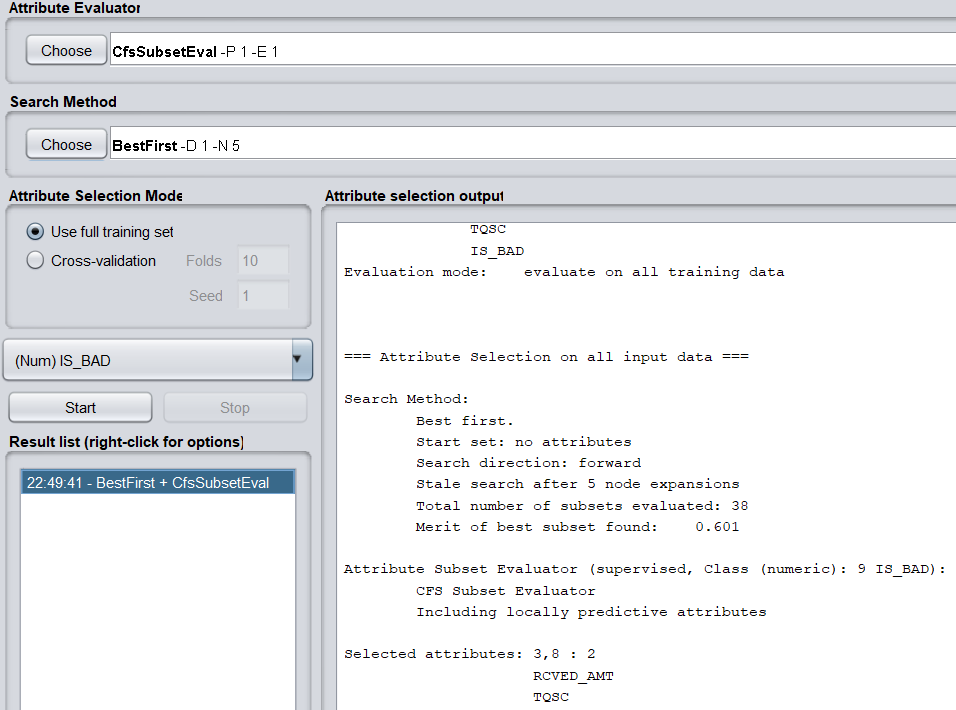
b)调用特征选择算法(Select attributes),选择关键特征。
评价策略使用CfsSubsetEval,它根据属性子集中每一个特征的预测能力以及它们之间的关联性进行评估。
搜索方法使用BestFirst。
得到两个关键特征,分别为RCVED_AMT(实收金额)与TQSC(欠费时长)。
(3)分别使用决策树(J48)、随机森林(RandomForest)、神经网络(MultilayerPerceptron)、朴素贝叶斯(NaiveBayes)等算法对数据进行分类,取60%作为训练集,记录各算法的查准率(precision)、查全率(recall)、混淆矩阵与运行时间。
对数据进行分类,首先要对其进行离散化。
在Filter中选择weka.filters.unsupervised.attribute.Discretize,进行离散化。
对数据分类,需要数据为Nominal类型,但此时IS_BAD还是Number类型,在Filter中选择weka.filters.unsupervised.attribute.NumericToNominal进行类型转换。
(a)决策树(J48)
查准率:0.838
查全率:0.807
混淆矩阵:
运行时间:2.27s
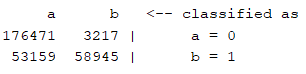
(b)随机森林(RandomForest)
查准率:0.837
查全率:0.807
混淆矩阵:
运行时间:67.04s
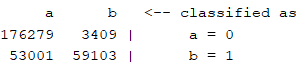
(c)神经网络(MultilayerPerceptron)
查准率:0.837
查全率:0.807
混淆矩阵:
运行时间:14713.98s

(d)朴素贝叶斯(NaiveBayes)
查准率:0.837
查全率:0.807
混淆矩阵:
运行时间:0.57s

4.基于Weka的回归分析
(1)读取“配网抢修数据.csv”,作为原始数据。
读取文件后,将一些对数据分析无用的属性删除,如:YMD(年月日)、REGION_ID(地区编号)
(2)数据预处理:
a)将数值型字段规范化至[0,1]区间。
在Filter中选择weka.filters.unsupervised.attribute.Normalize,进行归一化。归一化的数据如下图所示。
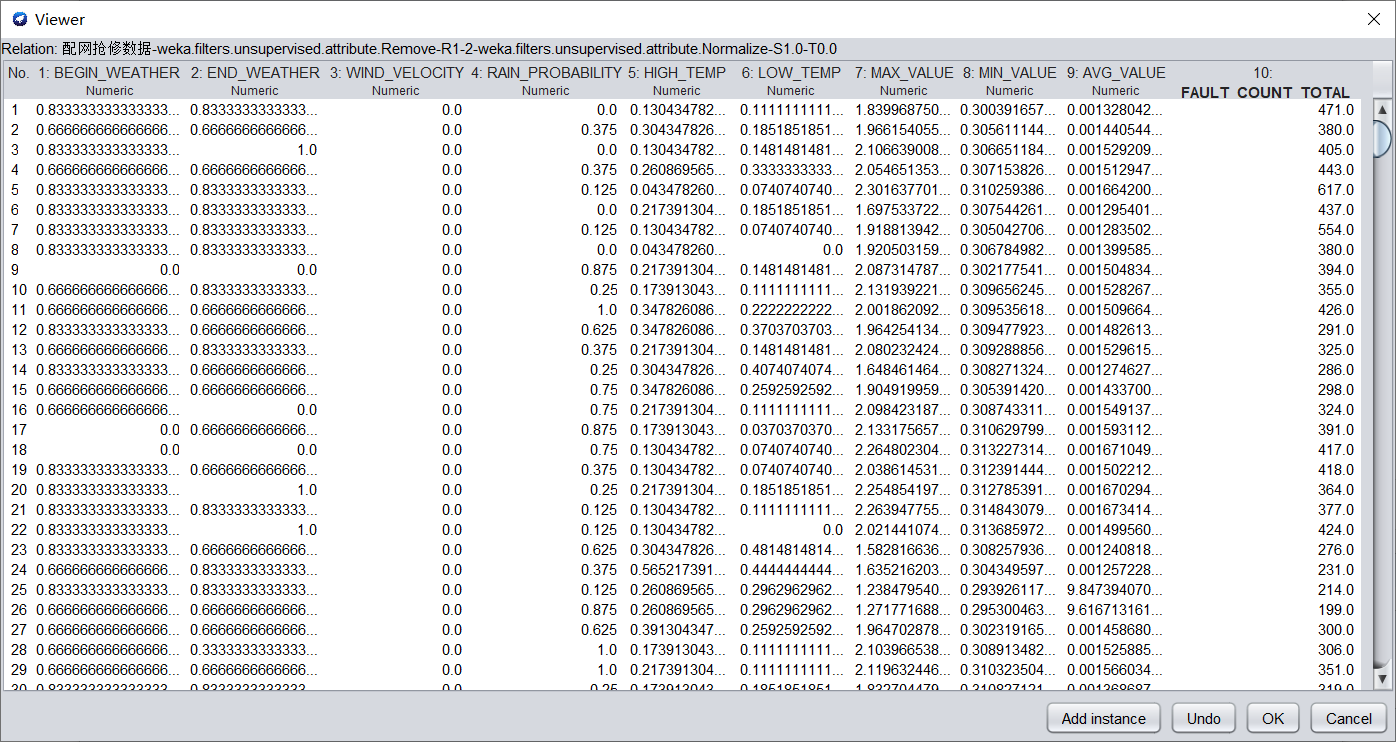
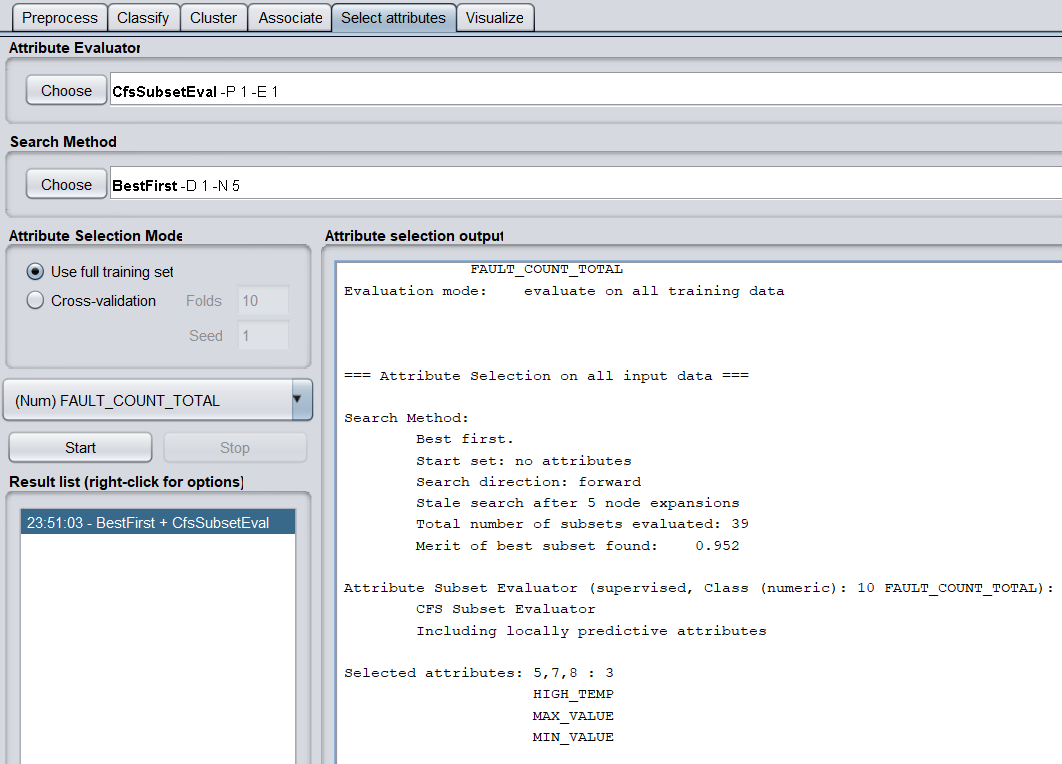
b)调用特征选择算法(Select attributes),选择关键特征。
评价策略使用CfsSubsetEval,搜索方法使用BestFirst。
得到三个关键特征,分别为HIGH_TEMP(开始气温)、MAX_VALUE(负荷最大值)和MIN_VALUE(负荷最小值)。
(3)分别使用随机森林(RandomForest)、神经网络(MultilayerPerceptron)、线性回归(LinearRegression)等算法对数据进行回归分析,取60%作为训练集,记录各算法的均方根误差(RMSE,Root Mean Squared Error)、相对误差(relative absolute error)与运行时间。
对数据进行回归分析前,先进行离散化。
在Filter中选择weka.filters.unsupervised.attribute.Discretize,进行离散化。
(a)随机森林(RandomForest)
均方根误差:152.2666
相对误差:27.9604%
运行时间:0.26s
(b)神经网络(MultilayerPerceptron)
均方根误差:185.7892
相对误差:41.9412%
运行时间:33.85s
(c)线性回归(LinearRegression)
均方根误差:141.7254
相对误差:26.9541 %
运行时间:0.19s
5.基于Weka的数据聚类
(1)读取“移动客户数据.tsv”(TAB符分隔列),作为原始数据。
删除无关属性,SUM_MONTH、USER_ID、MSISDN、CUS_ID。
(2)数据预处理:
(a)将数值型字段规范化至[0,1]区间。
在Filter中选择weka.filters.unsupervised.attribute.Normalize,进行归一化。归一化的数据如下图所示。
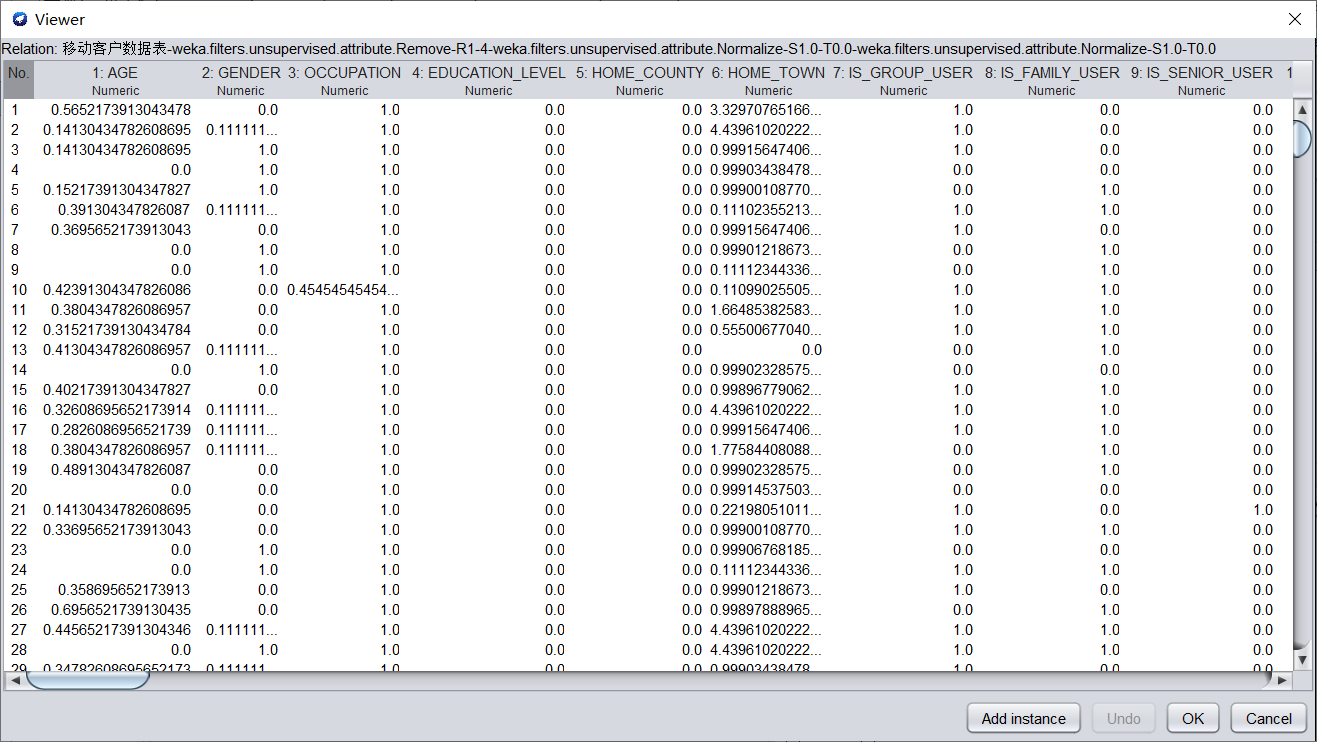
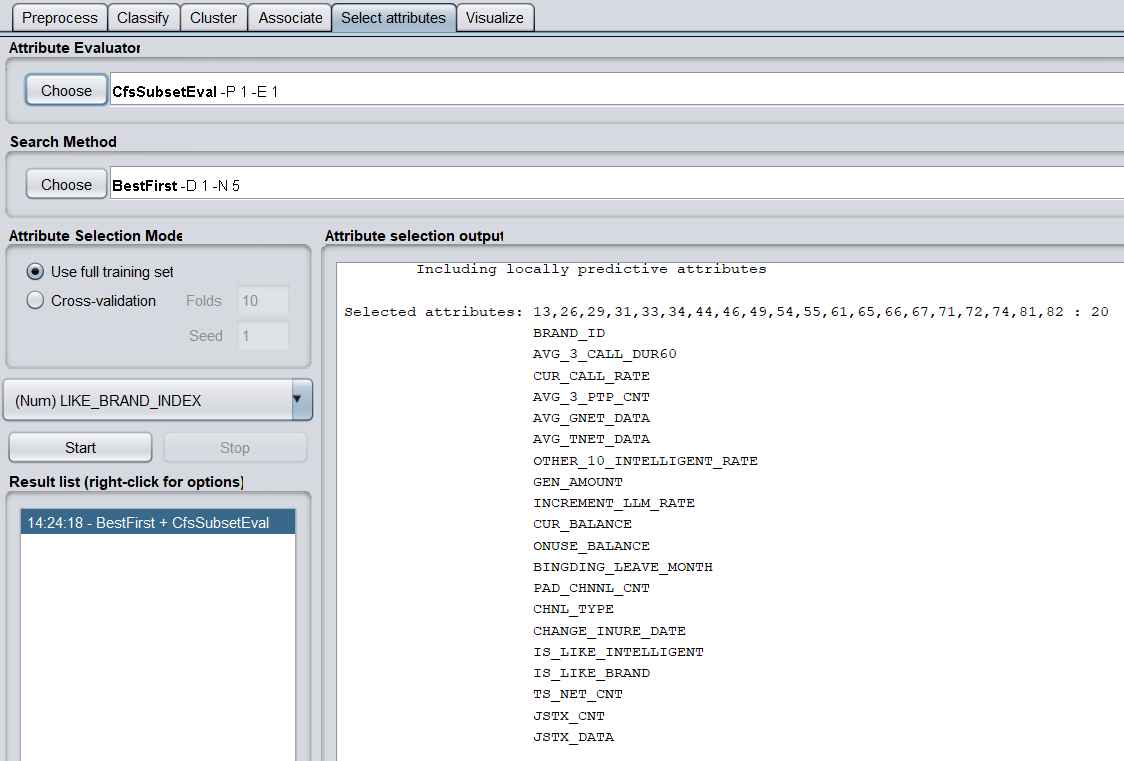
(b)调用特征选择算法(Select attributes),选择关键特征。
选择特征前,还要把数据中的2个string属性的删掉,才能使用CfsSubsetEval成功选择特征
评价策略使用CfsSubsetEval,搜索方法使用BestFirst。
共有20个关键特征,分别为
BRAND_ID
AVG_3_CALL_DUR60
CUR_CALL_RATE
AVG_3_PTP_CNT
AVG_GNET_DATA
AVG_TNET_DATA
OTHER_10_INTELLIGENT_RATE
GEN_AMOUNT
INCREMENT_LLM_RATE
CUR_BALANCE
ONUSE_BALANCE
BINGDING_LEAVE_MONTH
PAD_CHNNL_CNT
CHNL_TYPE
CHANGE_INURE_DATE
IS_LIKE_INTELLIGENT
IS_LIKE_BRAND
TS_NET_CNT
JSTX_CNT
JSTX_DATA
(3)分别使用K均值(SimpleKMeans)、期望值最大化(EM)、层次聚类(HierarchicalClusterer)等算法对数据进行聚类,记录各算法的聚类质量(sum of squared errors)与运行时间。
(a)K均值(SimpleKMeans)
聚类质量: 138999.20953835524
运行时间:1.18s
(b)期望值最大化(EM)
聚类质量:
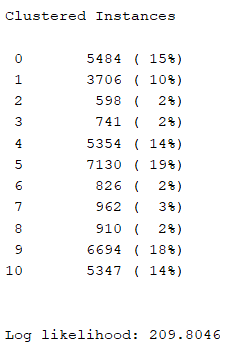
运行时间:6892.63s
(c)层次聚类(HierarchicalClusterer)
爆了内存,暂时找不到解决方法。
聚类质量:
运行时间:
6.基于Weka的关联规则分析
(1)读取“配网抢修数据.csv”,作为原始数据。
读取文件后,将一些对数据分析无用的属性删除,如:YMD(年月日)、REGION_ID(地区编号)
(2)数据预处理:
a)将数值型字段规范化至[0,1]区间。
在Filter中选择weka.filters.unsupervised.attribute.Normalize,进行归一化。归一化的数据如下图所示。
b)调用特征选择算法(Select attributes),选择关键特征。
评价策略使用CfsSubsetEval,搜索方法使用BestFirst。
得到三个关键特征,分别为HIGH_TEMP(开始气温)、MAX_VALUE(负荷最大值)和MIN_VALUE(负荷最小值)。
(3)使用Apriori算法对数值型字段进行关联规则分析,记录不同置信度(confidence)下算法生成的规则集。
(a)置信度为0.9
Best rules found:
1.BEGIN_WEATHER=0.833333 WIND_VELOCITY=1 RAIN_PROBABILITY=0 230 ==> END_WEATHER=0.833333 220 conf:(0.96) lift:(2.03) lev:(0.06) [111] conv:(11.06)
2.BEGIN_WEATHER=0.833333 RAIN_PROBABILITY=0 300 ==> END_WEATHER=0.833333 280 conf:(0.93) lift:(1.98) lev:(0.08) [138] conv:(7.56)
3.BEGIN_WEATHER=0.833333 RAIN_PROBABILITY=0.125 230 ==> END_WEATHER=0.833333 210 conf:(0.91) lift:(1.94) lev:(0.06) [101] conv:(5.79)
4.WIND_VELOCITY=1 RAIN_PROBABILITY=0.125 220 ==> END_WEATHER=0.833333 200 conf:(0.91) lift:(1.93) lev:(0.06) [96] conv:(5.54)
(b)置信度为0.6
Best rules found:
1.END_WEATHER=0.833333 WIND_VELOCITY=1 600 ==> BEGIN_WEATHER=0.833333 480 conf:(0.8) lift:(1.55) lev:(0.1) [169] conv:(2.39)
2.BEGIN_WEATHER=0.833333 END_WEATHER=0.833333 620 ==> WIND_VELOCITY=1 480 conf:(0.77) lift:(1.12) lev:(0.03) [51] conv:(1.35)
3.BEGIN_WEATHER=0.666667 660 ==> END_WEATHER=0.666667 510 conf:(0.77) lift:(1.82) lev:(0.13) [229] conv:(2.52)
4.END_WEATHER=0.833333 810 ==> BEGIN_WEATHER=0.833333 620 conf:(0.77) lift:(1.48) lev:(0.12) [200] conv:(2.05)
5.BEGIN_WEATHER=0.833333 WIND_VELOCITY=1 640 ==> END_WEATHER=0.833333 480 conf:(0.75) lift:(1.59) lev:(0.1) [178] conv:(2.1)
6.END_WEATHER=0.833333 810 ==> WIND_VELOCITY=1 600 conf:(0.74) lift:(1.07) lev:(0.02) [39] conv:(1.18)
7.BEGIN_WEATHER=0.833333 890 ==> WIND_VELOCITY=1 640 conf:(0.72) lift:(1.04) lev:(0.01) [24] conv:(1.09)
8.END_WEATHER=0.666667 730 ==> BEGIN_WEATHER=0.666667 510 conf:(0.7) lift:(1.82) lev:(0.13) [229] conv:(2.04)
9.BEGIN_WEATHER=0.833333 890 ==> END_WEATHER=0.833333 620 conf:(0.7) lift:(1.48) lev:(0.12) [200] conv:(1.74)
10.END_WEATHER=0.666667 730 ==> WIND_VELOCITY=1 480 conf:(0.66) lift:(0.95) lev:(-0.01) [-25] conv:(0.9)
(c)置信度为0.4
Best rules found:
1.END_WEATHER=0.833333 WIND_VELOCITY=1 600 ==> BEGIN_WEATHER=0.833333 480 conf:(0.8) lift:(1.55) lev:(0.1) [169] conv:(2.39)
2.BEGIN_WEATHER=0.833333 END_WEATHER=0.833333 620 ==> WIND_VELOCITY=1 480 conf:(0.77) lift:(1.12) lev:(0.03) [51] conv:(1.35)
3.BEGIN_WEATHER=0.666667 660 ==> END_WEATHER=0.666667 510 conf:(0.77) lift:(1.82) lev:(0.13) [229] conv:(2.52)
4.END_WEATHER=0.833333 810 ==> BEGIN_WEATHER=0.833333 620 conf:(0.77) lift:(1.48) lev:(0.12) [200] conv:(2.05)
5.BEGIN_WEATHER=0.833333 WIND_VELOCITY=1 640 ==> END_WEATHER=0.833333 480 conf:(0.75) lift:(1.59) lev:(0.1) [178] conv:(2.1)
6.END_WEATHER=0.833333 810 ==> WIND_VELOCITY=1 600 conf:(0.74) lift:(1.07) lev:(0.02) [39] conv:(1.18)
7.BEGIN_WEATHER=0.833333 890 ==> WIND_VELOCITY=1 640 conf:(0.72) lift:(1.04) lev:(0.01) [24] conv:(1.09)
8.END_WEATHER=0.666667 730 ==> BEGIN_WEATHER=0.666667 510 conf:(0.7) lift:(1.82) lev:(0.13) [229] conv:(2.04)
9.BEGIN_WEATHER=0.833333 890 ==> END_WEATHER=0.833333 620 conf:(0.7) lift:(1.48) lev:(0.12) [200] conv:(1.74)
10.END_WEATHER=0.666667 730 ==> WIND_VELOCITY=1 480 conf:(0.66) lift:(0.95) lev:(-0.01) [-25] conv:(0.9)