Paper: https://arxiv.org/pdf/1512.02325.pdf
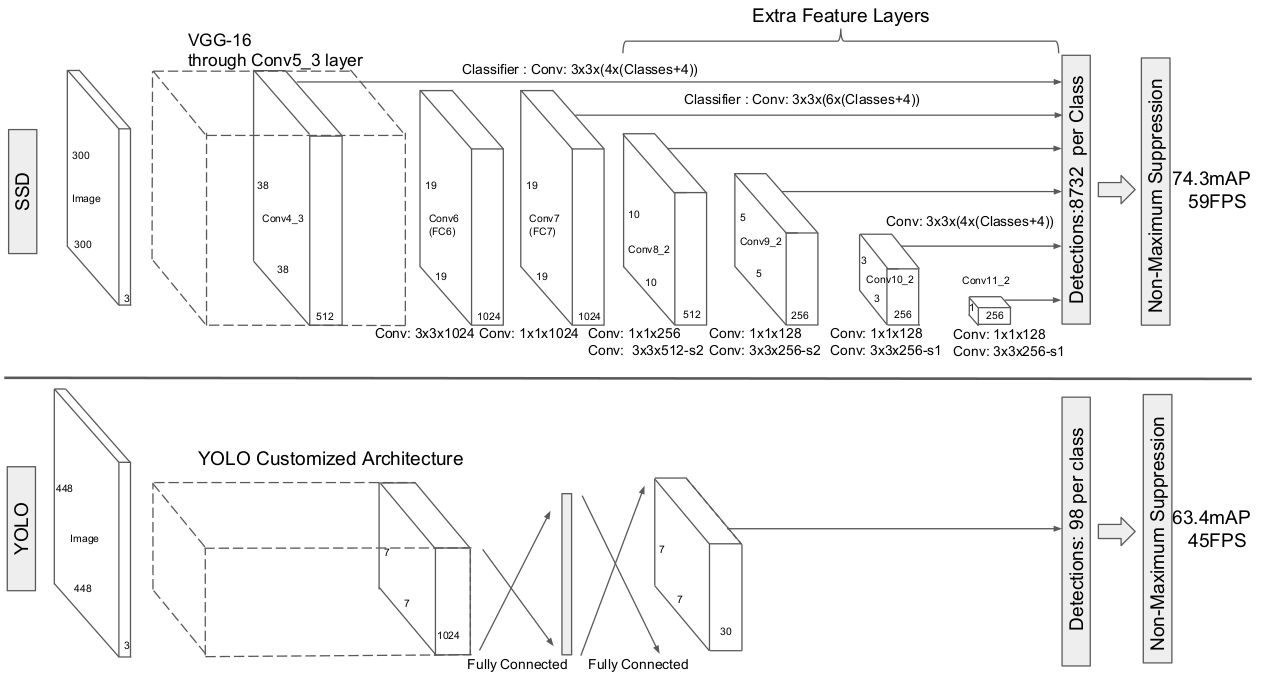
SSD用神经网络(VGG)提取多层feature map ,来实现对不同大小物体的检测。如下图所示:
We use the VGG-16 network as a base, but other networks should also produce good results.
Train:
损失函数=位置误差(locatization loss, loc)+alpha*置信度误差(confidence loss, conf)
其中:
- 解决负样本过多的问题,仅保留损失函数最大的K个FPs,即只保留K个最像正阳本的背景。
- 运用Data augmentation技术,提高鲁棒性。
Detect/Predict:
- 对于每个预测框,根据类别置信度确定其类别(置信度最大者)与置信度值。
- 根据置信度阈值(如0.5)过滤掉阈值较低的预测框。
- 对于留下的预测框进行解码,根据先验框得到其真实的位置参数(解码后一般还需要做clip,防止预测框位置超出图片)。
- 解码之后,一般需要根据置信度进行降序排列,然后仅保留top-k(如400)个预测框。
- 最后就是进行NMS算法,过滤掉那些重叠度较大的预测框。最后剩余的预测框就是检测结果了。
本文参考了下面两篇文章:
https://zhuanlan.zhihu.com/p/33544892
https://blog.csdn.net/remanented/article/details/79943418