一 概论
1.基本概念
编译器是将一种语言翻译为另一种语言的计算机程序。
过程描述如下:
源程序→ 编译器→ 目标程序。
基础知识:
自动机原理
数据结构
离散数学
编译器的发展:
冯诺依曼体系结构计算机 --> 机器语言程序 --> 汇编语言程序 --> FORTRAN语言及其编译器/ Noam Chomsky自然语言研究 --> 优化技术(生成有效目标代码)--> 编译器的自动构造(分析程序生成器,如Yacc)/有穷自动机的研究 --> IDE整合
注释:
汇编语言不易编写,依赖特定的机器。因此需要一种数学定义或自然语言的简洁形式编写程序操作。
首先解决的是分析问题,用于限定上下文无关语言的识别的有效算法。对应乔姆斯基2型结构。具体解决方案有有穷自动机和正则表达式。
然后深化了生成有效的目标代码方法。到此以构成最初的编译器。
接下来解决的问题是编译器的自动构造,分析程序生成器。
2.Chomsky hierarchy 乔姆斯基分类结构
参考:https://mjbin888.iteye.com/blog/1511207
https://blog.csdn.net/Dongle_74/article/details/52745859
Noam Chomsky的自然语言结构的研究,使得编译器结构异常简单,甚至还带有了一些自动化。Chomsky的
研究导致了根据语言文法( grammar,指定其结构的规则)的难易程度以及识别它们所需的算法来为语言分类。
乔姆斯基分类结构( Chomsky hierarchy)包括了文法的4个层次:0型、1型、2型和3型文法,且其中的每一个都是其前者的专门化。2型(或上下文无关文法( context-free grammar))被证明是程序设计语言中最有用的,而且今天它已代表着程序设计语言结构的标准方式。
终结符:语言的组成成分,是最后的内容
非终结符:不是语言的组成成分,而是在推到过程中的占位符,最终要替换终结符。
产生式:用终结符替代非终结符的规则。
终结符,通俗的说就是不能单独出现在推导式左边的符号,也就是说终结符不能再进行推导。不是终结符的都是非终结符。非终结符可理解为一个可拆分元素,而终结符是不可拆分的最小元素。如:有α → β ,则α 必然是个非终结符。一般书上把非终结符用大写字母表示,而终结符用小写字母表示。识别符号就是开始符。由文法产生语言句子的基本思想是:从识别符号开始,把当前产生的符号串中的非终结符号替换为相应规则右部的符号串,直到最终全由终结符号组成。这种替换过程称为推导或产生句子的过程,每一步成为直接推导或直接产生。
(非终结符:A,B,C,D,终结符:a,b,c,d)
0型文法,产生式左右部可以使用"非终结符"和"终结符"随意组合,但左部不能为空,如DAaBb->CcdD;
1型文法,在0型文法的基础上,要求右部的符号长度大于左部(空除外),如AaBb->CcddDd
1<=|AaBb|<=|CcddDd|
2型文法,在1型文法的基础上,要求左部必须由非终结符号组成,如AB->CcdddDd
3型文法,在2型文法的基础上,产生式必须型如:A->Aa|a或A->aA|a,比如:A->AA,A->aa,这些都不是
3型文法也许是大家最难理解的,下面为大家举几个例子来说明:
3型文法也叫正规文法,它对应于有限状态自动机。它是在2型文法的基础上满足:A→α|αB(右线性)或 A→α|Bα(左线性)。
如有:A->a,A->aB,B->a,B->cB,则符合3型文法的要求。但如果推导为:A->ab,A->aB,B->a,B->cB或推导 为:A->a,A->Ba,B->a,B->cB则不符合3型方法的要求了。具体的说,例子A->ab,A->aB,B->a,B->cB中的A->ab 不符合3型文法的定义,如果把后面的ab,改成“一个非终结符+一个终结符”的形式(即为aB)就对了。例子 A->a,A->Ba,B->a,B->cB中如果把B->cB改为B->Bc的形式就对了,因为A→α|αB(右线性)和A→α|Bα(左线 性)两套规则不能同时出现在一个语法中,只能完全满足其中的一个,才能算3型文法。
注意:上面例子中的大写字母表示的是非终结符,而小写字母表示的是终结符
有穷自动机( finite automata)和正则表达式(regular expression)同上下文无关文法紧密
相关,它们与乔姆斯基的3型文法相对应。
3.与编译器相关的程序
- 解释程序
- 汇编程序
- 连接程序
- 装入程序
- 预处理器
- 编辑器
- 调试程序
- 描述器
- 项目管理程序
4.翻译步骤
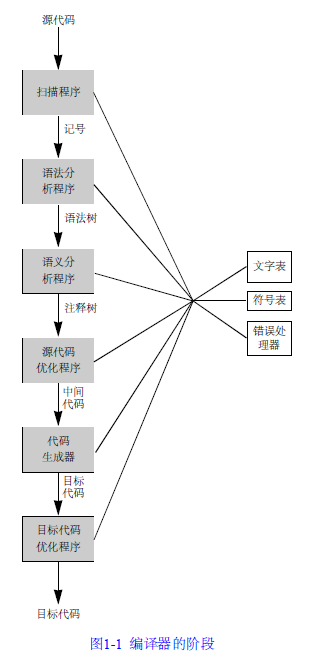
(1) 扫描程序(scanner)
在这个阶段编译器实际阅读源程序(通常以字符流的形式表示)。扫描程序执行词法分析(Lexical analysis):它将字符序列收集到称作记号(token)的有意义单元中,记号同自然语言,如英语中的字词相似。因此可以认为扫描程序执行与拼写相似的任务。
(2) 语法分析程序(parser)
语法分析程序从扫描程序中获取记号形式的源代码,并完成定义程序结构的语法分析(syntax analysis),这与自然语言中句子的语法分析类似。语法分析定义了程序的结构元素及其关系。通常将语法分析的结果表示为分析树( parse tree)或语法树(syntax tree)。
(3) 语义分析程序(semantic analyzer)
程序的语义就是它的“意思”,它与语法或结构不同。程序的语义确定程序的运行,但是大多数的程序设计语言都具有在执行之前被确定而不易由语法表示和由分析程序分析的特征。这些特征被称作静态语义( static semantic),而语义分析程序的任务就是分析这样的语义(程序的“动态”语义具有只有在程序执行时才能确定的特性,由于编译器不能执行程序,所以它不能由编译器来确定)。一般的程序设计语言的典型静态语义包括声明和类型检查。由语义分析程序计算的额外信息(诸如数据类型)被称为属性( attribute),它们通常是作为注释或“装饰”增加到树中(还可将属性添加到符号表中)。
(4) 源代码优化程序(source code optimizer)
编译器通常包括许多代码改进或优化步骤。绝大多数最早的优化步骤是在语义分析之后完成的,而此时代码改进可能只依赖于源代码。这种可能性是通过将这一操作提供为编译过程中的单独阶段指出的。每个编译器不论在已完成的优化种类方面还是在优化阶段的定位中都有很大的差异。
(5) 代码生成器(code generator)
代码生成器得到中间代码( I R),并生成目标机器的代码。尽管大多数编译器直接生成目标代码,但是为了便于理解,本书用汇编语言来编写目标代码。正是在编译的这个阶段中,目标机器的特性成为了主要因素。当它存在于目标机器时,使用指令不仅是必须的而且数据的形式表示也起着重要的作用。例如,整型数据类型的变量和浮点数据类型的变量在存储器中所占的字节数或字数也很重要。
(6) 目标代码优化程序(target code optimizer)
在这个阶段中,编译器尝试着改进由代码生成器生成的目标代码。这种改进包括选择编址模式以提高性能、将速度慢的指令更换成速度快的,以及删除多余的操作。
5.编译器中的主要数据结构
(1)记号
当扫描程序将字符收集到一个记号中时,它通常是以符号表示这个记号;这也就是说,作为一个枚举数据类型的值来表示源程序的记号集。
(2)语法树
如果分析程序确实生成了语法树,它的构造通常为基于指针的标准结构,在进行分析时动态分配该结构,则整棵树可作为一个指向根节点的单个变量保存。结构中的每一个节点都是一个记录,它的域表示由分析程序和之后的语义分析程序收集的信息。
(3)符号表
这个数据结构中的信息与标识符有关:函数、变量、常量以及数据类型。符号表几乎与编译器的所有阶段交互:扫描程序、分析程序或将标识符输入到表格中的语义分析程序;语义分析程序将增加数据类型和其他信息;优化阶段和代码生成阶段也将利用由符号表提供的信息选出恰当的代码。因为对符号表的访问如此频繁,所以插入、删除和访问操作都必须比常规操作更有效。尽管可以使用各种树的结构,但杂凑表却是达到这一要求的标准数据结构。有时在一个列表或栈中可使用若干个表格。
(4)常数表
常数表的功能是存放在程序中用到的常量和字符串,因此快速插入和查找在常数表中也十分重要。但是,在其中却无需删除,这是因为它的数据全程应用于程序而且常量或字符串在该表中只出现一次。通过允许重复使用常量和字符串,常数表对于缩小程序在存储器中的大小显得非常重要。在代码生成器中也需要常数表来构造用于常数和在目标代码文件中输入数据定义的符号地址。
(5)中间代码
根据中间代码的类型(例如三元式代码和P -代码)和优化的类型,该代码可以是文本串
的数组、临时文本文件或是结构的连接列表。对于进行复杂优化的编译器,应特别注意选择允
许简单重组的表示。
(6)临时文件
计算机过去一直未能在编译器时将整个程序保留在存储器中。这一问题已经通过使用临时文件来保存翻译时中间步骤的结果或通过“匆忙地”编译(也就是只保留源程序早期部分的足够信息用以处理翻译)解决了。存储器的限制现在也只是一个小问题了,现在可以将整个编译单元放在存储器之中,特别是在可以分别编译的语言中时。但是偶尔还是会发现需要在某些运行步骤中生成中间文件。
6.编译器结构中的其他问题

(1)分析和综合
将分析源程序以计算其特性的编译器操作归为编译器的分析部分,而将生成翻译代码时所涉及到的操作称作编译器的综合部分。当然,词法分析、语法分析和语义分析均属于分析部分,而代码生成却是综合部分。在优化步骤中,分析和综合都有。分析正趋向于易懂和更具有数学性,而综合则要求更深的专业技术。因此,将分析步骤和综合步骤两者区分开来以便发生变化时互不影响是很有用的。
(2)前端和后端
扫描程序、分析程序和语义分析程序是前端,代码生成器是后端。但是一些优化分析可以依赖于目标语言,这样就是属于后端了,然而中间代码的综合却经常与目标语言无关,因此也就属于前端了。在理想情况下,编译器被严格地分成这两部分,而中间表示则作为其间的交流媒介。
这一结构对于编译器的可移植性十分重要,此时设计的编译器既能改变源代码(它涉及到重写前端),又能改变目标代码(它还涉及到重写后端)。在实际中,这是很难做到的,而且称作可移植的编译器仍旧依赖于源语言和目标语言。
(3)遍
编译器发现,在生成代码之前多次处理整个源程序很方便。这些重复就是遍( pass)。
(4)语言定义和编译器
(5)编译器的选项和界面
(6)出错处理