用途
Kruskal重构树可以维护诸如“查询从某个点出发经过边权不超过w的边最远所能到达的节点”或“从某点到某点所有路径的最长(短)边的最小(大)值”(即最小(大)瓶颈路)之类的问题。
总之,算法处理范围有限,且多为同时包含“最大最小”、离线可二分的题目。
可与数据结构结合,以维护更复杂的数据结构。
支持在线,单次复杂度为(O(log n))。
构造方法
按照Kruskal的传统步骤,先排序,按顺序枚举两个非连通块,合并后, 建一个点权为两点之间边权的父节点 。这样建出来的一棵树称为Kruskal重构树。
e.g. 假设原图(盗的)长这样:
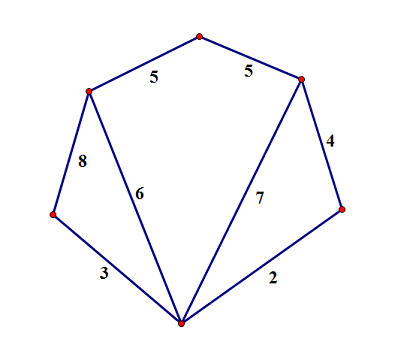
建成树后就是这样(蓝色实线为最小生成树):
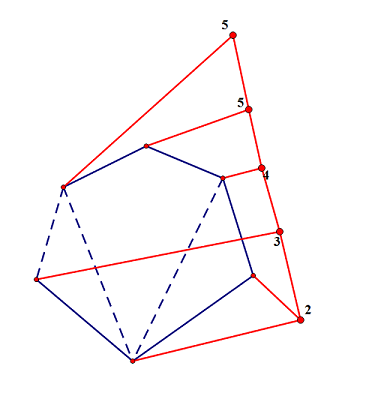
性质
按照上述方法建出来的树有一些非常好的性质。
1.树上除叶子结点以外的点都对应着原来生成树中的边,叶子结点就是原来生成树上的节点。
2.由于新点的创建顺序与原来生成树上边权的大小有关,可以发现,从每个点到根节点上除叶子结点外按顺序访问到的点的点权是单调的。
3.出于Kruskal算法贪心的性质,两个点u和v的LCA的点权就对应着它们最小生成树上的瓶颈。
4.实际上这棵树就是一个二叉堆。
例题
[简单]NOIp2013 货车运输
Solution:先bb一句,最大值最小叫最小瓶颈路,但这题是最小值最大,干脆叫最大瓶颈路吧(口胡中
那这题就是最大瓶颈路果题了。
当然虽然是果题,第一次写还是要注意一些细节的。首先在原图基础上建树,那么数组得开两倍大。其次需要开一个tot来标新建的根节点(不过好像也可以直接用n),然后遍历时直接从tot开始。再次是题目给的有可能是个森林,所以得全遍历一遍。
然后LCA别写错是我没错了。
然后以后再也不卡常了,浪费时间浪费评测资源
#include <cstdio>
#include <cctype>
#include <cmath>
#include <algorithm>
using namespace std;
const int N=20005;
struct Edge2{int u,v,w;}t[50005];
struct Edge{int to,nxt;}e[200005];
int n,m,q,head[N],cnt,fa[N],dep[N],lca[N][22],val[N],tot;
inline int read()
{
register int x=0,ch=getchar();
while(!isdigit(ch)) ch=getchar();
while(isdigit(ch)) x=(x<<1)+(x<<3)+ch-'0', ch=getchar();
return x;
}
inline bool cmp(Edge2 a,Edge2 b) {return a.w>b.w;}
inline void add(int u,int v) {e[++cnt]=(Edge){v,head[u]},head[u]=cnt;}
int find(int x) {return fa[x]==x?x:fa[x]=find(fa[x]);}
void kruskal()
{
tot=n;
sort(t+1,t+m+1,cmp);
for(int i=1;i<=n;++i) fa[i]=i;
for(int i=1;i<=m;++i)
{
int x=find(t[i].u),y=find(t[i].v);
if(x==y) continue;
val[++tot]=t[i].w;
fa[x]=fa[y]=fa[tot]=tot;
add(x,tot); add(tot,x);
add(y,tot); add(tot,y);
}
}
void dfs(int u,int fa)
{
dep[u]=dep[fa]+1,lca[u][0]=fa;
for(int i=1;1<<i<=dep[u];++i)
lca[u][i]=lca[lca[u][i-1]][i-1];
for(int i=head[u];i;i=e[i].nxt)
if(!dep[e[i].to]) dfs(e[i].to,u);
}
int LCA(int x,int y)
{
if(dep[x]<dep[y]) swap(x,y);
while(dep[x]>dep[y]) x=lca[x][(int)log2(dep[x]-dep[y])];
if(x==y) return val[x];
for(int i=log2(dep[x])+1;i>=0;--i)
if(lca[x][i]!=lca[y][i]) x=lca[x][i],y=lca[y][i];
return val[lca[x][0]];
}
int main()
{
n=read(),m=read();
for(int i=1;i<=m;++i) t[i].u=read(),t[i].v=read(),t[i].w=read();
kruskal();
for(int i=tot;i>n;--i) if(!dep[i]) dfs(i,i);
q=read();
for(int i=1,x,y;i<=q;++i)
{
x=read(),y=read();
if(find(x)!=find(y)) puts("-1");
else printf("%d
",LCA(x,y));
}
return 0;
}
[较难]NOI2018 归程
别想了我还会写这题?