抛出样例:
Integer a1 = new Integer(123);
Integer a2 = new Integer(123);
System.out.println(a1 == a2); //false 因为只要遇到new关键词,肯定会在堆里面重新分配空间给实例对象,所以两个地址肯定不同
a1 = 123;
a2 = 123;
System.out.println(a1 == a2); //true 因为Integer里面有个内部类,IntegerCache用来存放-128到127之间的数据,如果Integer定义的数据在这个里面,则指向的相同的位置数据
a1 = 234;
a2 = 234;
System.out.println(a1 == a2); //false Integer里面的内部类IntegerCache只能保存-128到127之间的数据,如果超过了这个限制,那么不能从缓存中得到结果,只能通过new来分配空间,所以指向的地址不同
int a3 = new Integer(123);
int a4 = new Integer(123);
System.out.println(a1 == a2); //false int是基本数据类型,同样遇到new也要重新分配空间,指向的地址不同
//下面int的理解也可以用常量池的方式来理解,存放到常量池中,指向常量池中相同的位置
a3 = 123;
a4 = 123;
System.out.println(a3 == a4); //true int作为基本数据类型,会把数据知己放到栈上进行操作,只是比较的两个数值是否相等,
a3 = 234;
a4 = 234;
System.out.println(a3 == a4); //true int作为基本数据类型,会把数据知己放到栈上进行操作,只是比较的两个数值是否相等,也不存在封装类的-128到127的范围问题
Integer a5 = new Integer(0);
System.out.println(a1 == a2 + a5); //true 进行加法运算时,首先将封装类进行拆箱操作,然后在栈上进行比较,所以只是比较的两个数值是否相等
Integer a6 = 1;
Integer a7 = 2;
Integer a8 = 3;
Long a9 = 3;
System.out.println(a8.equals(a6 + a7)); //true equals方法首先判断(a6 + a7)是不是Integer类型,如果是,然后只用判断a8的值与a6+a7的值是否相等就可以了。
比较的源码:
public boolean equals(Object obj) {
if (obj instanceof Integer) {
return value == ((Integer)obj).intValue();
}
return false;
}
System.out.println(a9.equals(a6 + a7)); //false equals方法首先判断(a6 + a7)是不是Long类型,(a6+a7)是Integer类型,不是Long类型,所以直接返回false,不用判断a8的值与a6+a7的值是否相等就可以了。
比较的源码:
public boolean equals(Object obj) {
if (obj instanceof Long) {
return value == ((Long)obj).longValue();
}
return false;
}
进一步延伸:
常量池其实也就是一个内存空间,不同于使用new关键字创建的对象所在的堆空间。
8种基本类型的包装类和对象池
java中基本类型的包装类的大部分都实现了常量池技术,这些类是 Boolean,Byte,Character,Short,Integer,Long另外两种浮点数类型的包装类则没有实现。另外 Byte,Short,Integer,Long,Character这5种整型的包装类也只是在对应值小于等于127时才可使用对象池,也即对象不负责 创建和管理大于127的这些类的对象。
具体的jdk1.7的源码:
Byte 实现的常量池源码:缓存的是[-128, 127]之间的数据
private static class ByteCache {
private ByteCache(){}
static final Byte cache[] = new Byte[-(-128) + 127 + 1];
static {
for(int i = 0; i < cache.length; i++)
cache[i] = new Byte((byte)(i - 128));
}
}
Character 实现的常量池源码:缓存的是[0, 127]之间的数据
private static class CharacterCache {
private CharacterCache(){}
static final Character cache[] = new Character[127 + 1];
static {
for (int i = 0; i < cache.length; i++)
cache[i] = new Character((char)i);
}
}
Short实现的常量池源码:缓存的是[-128, 127]之间的数据
private static class ShortCache {
private ShortCache(){}
static final Short cache[] = new Short[-(-128) + 127 + 1];
static {
for(int i = 0; i < cache.length; i++)
cache[i] = new Short((short)(i - 128));
}
}
Integer实现的常量池源码:缓存的是[-128, 127]之间的数据
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low));
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
}
private IntegerCache() {}
}
Long实现的常量池源码:缓存的是[-128, 127]之间的数据
private static class LongCache {
private LongCache(){}
static final Long cache[] = new Long[-(-128) + 127 + 1];
static {
for(int i = 0; i < cache.length; i++)
cache[i] = new Long(i - 128);
}
}
Boolean实现的常量池源码:boolean采用的静态类型且final来设置TRUE和FALSE,这样只需要在类加载的时候初始化一次,只会存放在方法区中一份数据
public static Boolean valueOf(boolean b) {
return (b ? TRUE : FALSE);
}
public static final Boolean TRUE = new Boolean(true);
/**
* The <code>Boolean</code> object corresponding to the primitive
* value <code>false</code>.
*/
public static final Boolean FALSE = new Boolean(false);
String的常量池解析
Java中的常量池,实际上分为两种形态:静态常量池和运行时常量池。
所谓静态常量池,即*.class文件中的常量池,class文件中的常量池不仅仅包含字符串(数字)字面量,还包含类、方法的信息,占用class文件绝大部分空间。
而运行时常量池,则是jvm虚拟机在完成类装载操作后,将class文件中的常量池载入到内存中,并保存在方法区中,我们常说的常量池,就是指方法区中的运行时常量池。
接下来我们引用一些网络上流行的常量池例子,然后借以讲解。

1 String s1 = "Hello";
2 String s2 = "Hello";
3 String s3 = "Hel" + "lo";
4 String s4 = "Hel" + new String("lo");
5 String s5 = new String("Hello");
6 String s6 = s5.intern();
7 String s7 = "H";
8 String s8 = "ello";
9 String s9 = s7 + s8;
10
11 System.out.println(s1 == s2); // true
12 System.out.println(s1 == s3); // true
13 System.out.println(s1 == s4); // false
14 System.out.println(s1 == s9); // false
15 System.out.println(s4 == s5); // false
16 System.out.println(s1 == s6); // true
首先说明一点,在java 中,直接使用==操作符,比较的是两个字符串的引用地址,并不是比较内容,比较内容请用String.equals()。
s1 == s2这个非常好理解,s1、s2在赋值时,均使用的字符串字面量,说白话点,就是直接把字符串写死,在编译期间,这种字面量会直接放入class文件的常量池中,从而实现复用,载入运行时常量池后,s1、s2指向的是同一个内存地址,所以相等。
s1 == s3这个地方有个坑,s3虽然是动态拼接出来的字符串,但是所有参与拼接的部分都是已知的字面量,在编译期间,这种拼接会被优化,编译器直接帮你拼好,因 此String s3 = "Hel" + "lo";在class文件中被优化成String s3 = "Hello";,所以s1 == s3成立。
s1 == s4当然不相等,s4虽然也是拼接出来的,但new String("lo")这部分不是已知字面量,是一个不可预料的部分,编译器不会优化,必须等到运行时才可以确定结果,结合字符串不变定理,鬼知道s4被分配到哪去了,所以地址肯定不同。配上一张简图理清思路:
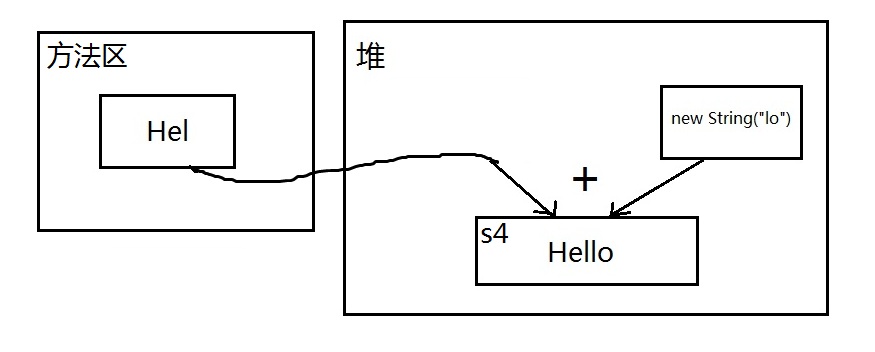 s1 == s9也不相等,道理差不多,虽然s7、s8在赋值的时候使用的字符串字面量,但是拼接成s9的时候,s7、s8作为两个变量,都是不可预料的,编译器毕竟 是编译器,不可能当解释器用,所以不做优化,等到运行时,s7、s8拼接成的新字符串,在堆中地址不确定,不可能与方法区常量池中的s1地址相同。
s1 == s9也不相等,道理差不多,虽然s7、s8在赋值的时候使用的字符串字面量,但是拼接成s9的时候,s7、s8作为两个变量,都是不可预料的,编译器毕竟 是编译器,不可能当解释器用,所以不做优化,等到运行时,s7、s8拼接成的新字符串,在堆中地址不确定,不可能与方法区常量池中的s1地址相同。
s4 == s5已经不用解释了,绝对不相等,二者都在堆中,但地址不同。
s1 == s6这两个相等完全归功于intern方法,s5在堆中,内容为Hello ,intern方法会尝试将Hello字符串添加到常量池中,并返回其在常量池中的地址,因为常量池中已经有了Hello字符串,所以intern方法直 接返回地址;而s1在编译期就已经指向常量池了,因此s1和s6指向同一地址,相等。