一、访问ES方法:http://IP:PORT/
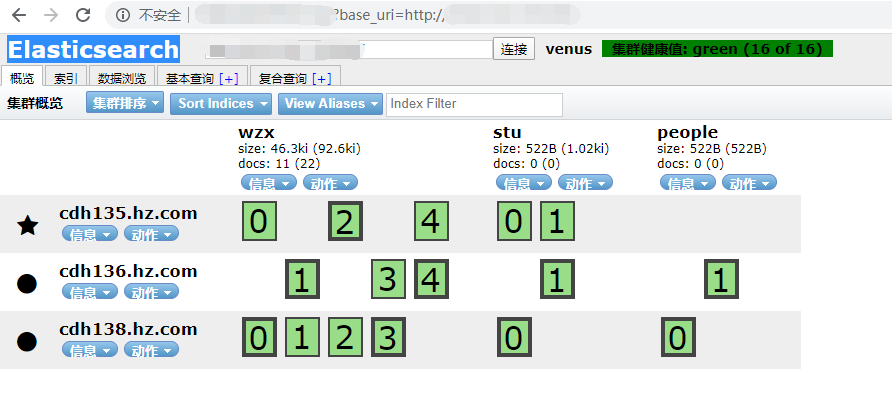
一、创建索引:head插件创建索引的实例:在”索引“-”新建索引“中创建索引名称,默认了分片与副本情况:
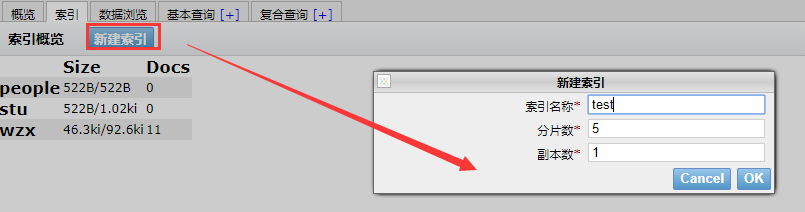
直接确认即可:
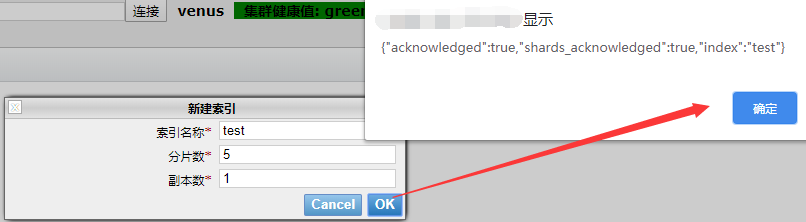
刷新即可看见成功的索引:
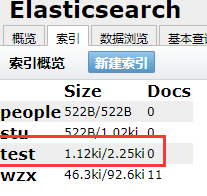
创建索引方式2:利用符合查询的PUT方式:
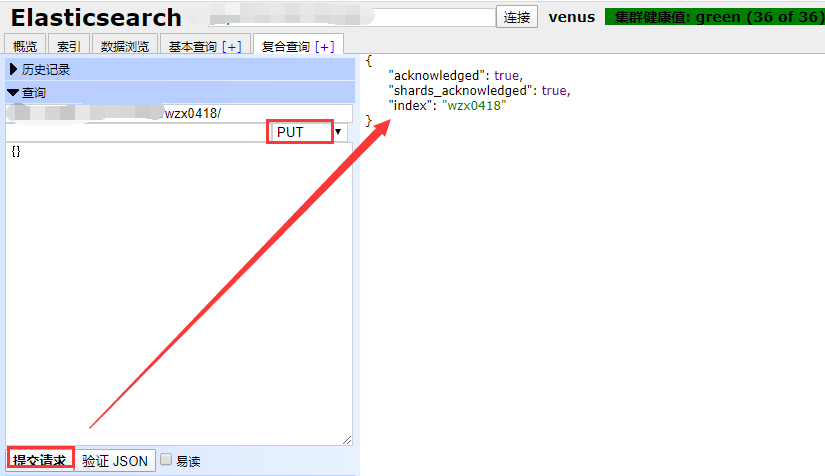
刷新即可看到索引:

删除索引:在概览-动作-删除即可:
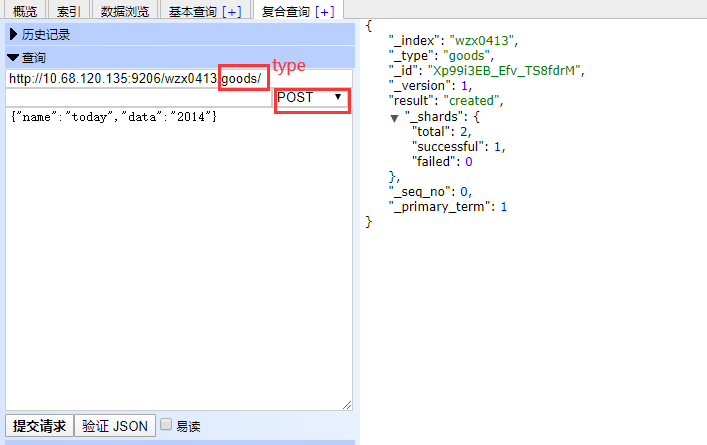
新增数据:{"name":"today","data":"2014"}
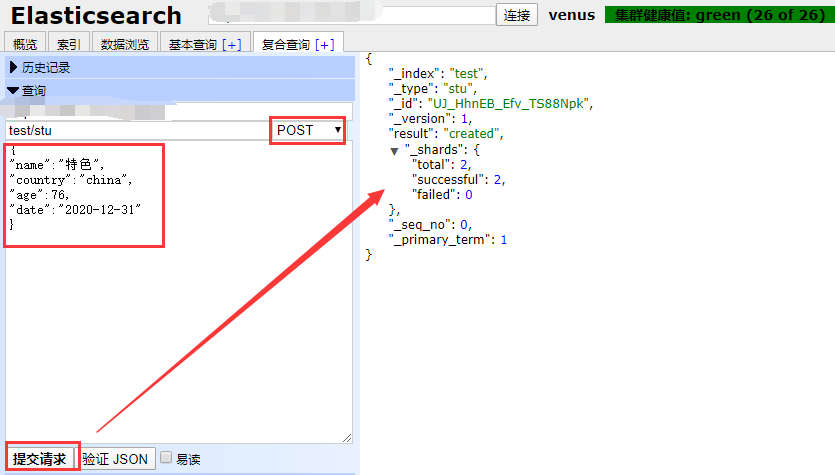
新增数据:在复合查询中,然后构建json串,就可以增加数据 :
{
"name":"特色",
"country":"china",
"age":76,
"date":"2020-12-31"
}
刷新即可看见新增数据:
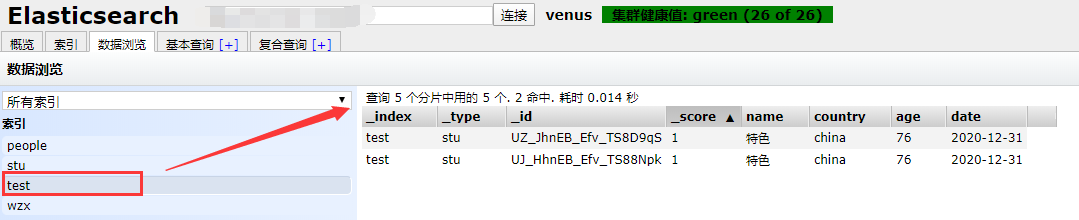
修改内容:{"name":"今天儿童","data":"2014"}
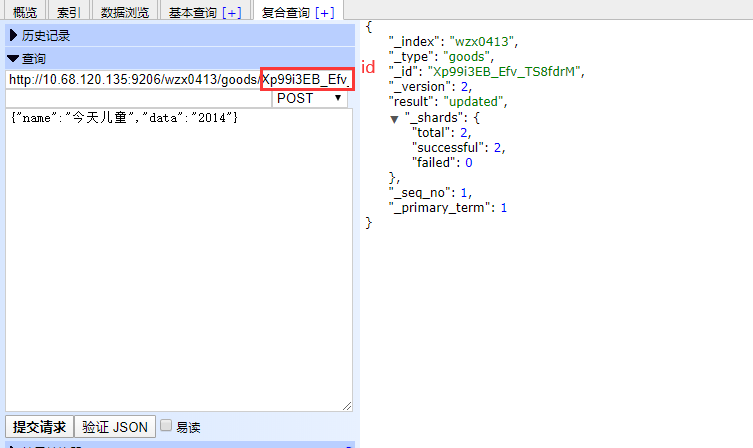
添加字段:
{
"stu":{
"describ":{
"type":"text"
}
}
}
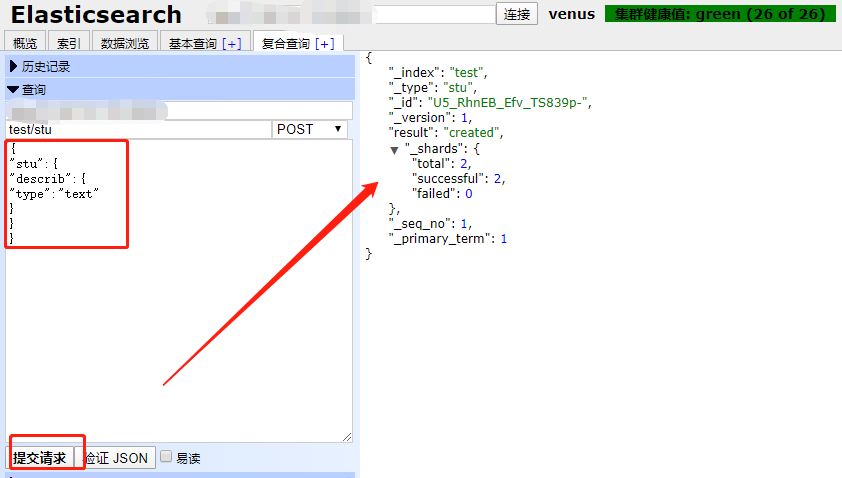
插入数据查看字段是否插入成功:
{
"name":"ytjy",
"country":"jyujuy",
"age":76,
"date":"2020-12-31",
"describ":"描述性的一句话的哦"
}
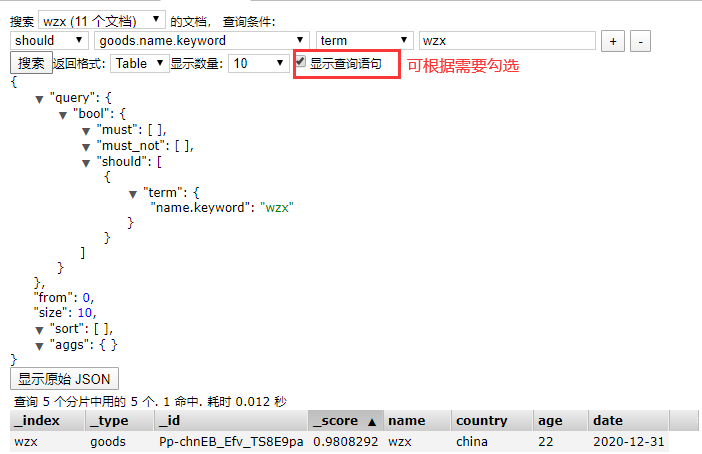
三、查询数据:利用”基本查询“:
方式2:查询表:
基本查询介绍:
基本查询:must, must not,should的区别
- must 返回的文档必须满足must子句的条件,类似于 == and
- must not返回的文档必须不满足must not 子句的条件 类似于!= not
- should 返回的文档只要满足should中的一个条件即可 类似于 || or
各类查询参数
- term 相当
- text 片段
- prefix 前缀
- wildcard 通配符查询 例:*商品*
- fuzzy 区间,分词模糊查询 结合max_expansions 和min_similarity,数值则表示在此数值的增加,减小数量在多少范围之内的数据;字符则为在此自负基础上增加/减少多少字符范围内的数据
- range 区间查询,如果type是时间类型,可用内置now表示当前,-1d/h/m/s来进行时间操作
- query_string 可以对int, long, string查询,对int,long只能本身查询,对string进行分词和本身查询
- missing 返回没有字段或值为null的文档