1、state 数据 2、jsx模板 3、生成虚拟dom(虚拟DOM就是一个js对象,用它来描述真实DOM) ['div', {id:'abc'}, ['span', {}, 'hello world']] 通过这样的一个js对象,我们就可以表述上面的dom结构了 4、用虚拟dom的结构,生成真实的dom,来显示 <div id='abc'><span>hello world</span></div> 5、state发生变化 6、新的虚拟dom(极大的提升了性能) ['div', {id:'abc'}, ['span', {}, 'bye bye']] 7、比较原始虚拟DOM和新的虚拟DOM的区别,找到区别是span中的内容(极大的提升了性能) 8、直接操作DOM,改变span中的内容
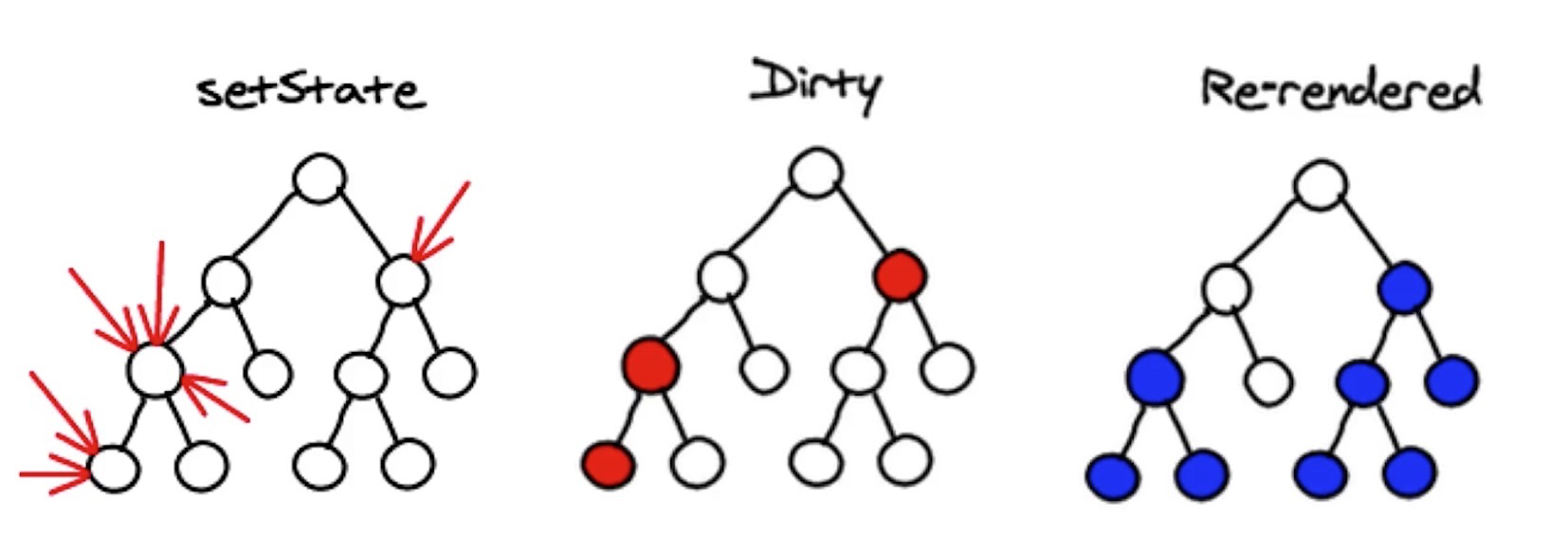
如图,diff算法有个很重要的概念,叫做同级比较,首先会比较最顶层的虚拟dom节点是否一致,假设一致,再去比较下一个节点。假设第一层虚拟dom不一致,这个时候怎么办呢?这个时候react就不会往下比了,他会原始的虚拟dom下面的节点全部删除掉,重新生成一遍节点下面的所有dom,然后用重新生成的dom,替换原始页面的dom,也就是只比对一层dom,大家可能会想,这不是性能很低吗?假设第一层节点不同,下面的节点都相同,岂不是下面的节点都没法复用了,确实是这样的,虽然会造成一些dom节点的渲染浪费,但是这种比对有什么好处呢?我们说同层比对,带来的算法非常的简单,只要一层一层的做对比就行了,算法简单,带来的好处就是比对的速度会非常的快,所以可能会造成重新渲染的一些浪费,但大大减少了去比对的算法上的性能消耗。所以采用了同层比对的算法。

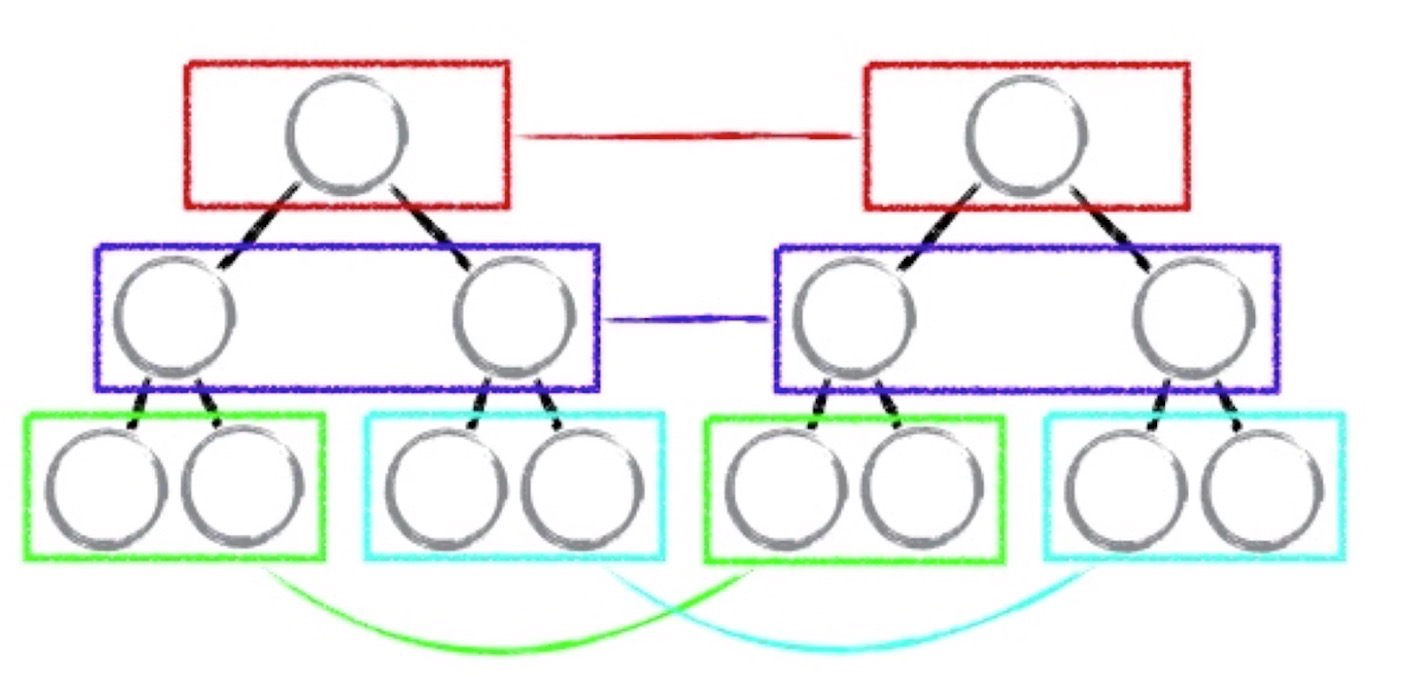
再如图,假设我有1个数组,数组里面有5个数据,然后在页面第一次渲染的时候,我会把这个5个数据映射成5个虚拟dom节点,生成一个小的虚拟dom树,接着我又往数组里面增加一些内容,于是数据发生变化,会生成一个新的虚拟dom树,然后会进行一个比对,就是图左上下进行比对,如果每个虚拟dom没有一个key值,就没有一个自己的名字,当作两个虚拟dom树比对的时候,节点和节点之间的关系就很难被确定,比如下面的第一个是跟上面的第一个是一个即诶单,还是跟第二个是一个节点,很难做判断,所以得做两层循环的一个比较,这样比较起来就很麻烦了,也比较耗性能,现在加入在给虚拟dom循环的时候,我们可以给每一个节点起一个名字多好,如图右,虚拟dom根据key值做关联,只要找到对应的名字一样的节点是否相同,极大的提高了react的性能。这里就是为什么不要用index,如果key值是index的话,就没法保证在原始的虚拟dom树上,他的key值和虚拟dom树上的key值一致了。举个例子,比如一个数组