1.一个线性回归的例子
假设你去了一些鲜为人知的地方旅游,然后带回了一个花哨的壁挂式模拟温度计。这个温度计看起来很棒,非常适合你的客厅。唯一的缺点是它不显示单位。不用担心,你有一个计划。你用自己喜欢的单位建立一个读数和相应温度值的数据集,然后选择一个模型,并迭代调整单位的权重,直到误差的测量值足够低为止,最后你就可以在新温度计上进行准确读数了。
首先记录能正常工作的旧摄氏温度计的数据和你刚带回来的新温度计对应的测量值。几周后,你得到了一些数据:
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0] #t_c是摄氏度数
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4] #t_u是未知单位度数
t_c = torch.tensor(t_c)
t_u = torch.tensor(t_u)
为了根据未知温度t_u获得以摄氏度为单位的温度值 t_c,先选择线性模型作为一个假设, t_c = w*t_u + b
为了用梯度下降算法更新参数w,b,核心问题就是如何求导。
简单的例子,我们可以自己实现算出偏导的表达式,或者和官方示例一样从导数的定义式出发
delta = 0.1
loss_rate_of_change_w = (loss_fn(model(t_u, w + delta, b), t_c) - loss_fn(model(t_u, w - delta, b), t_c)) / (2.0 * delta)
2.使用自动求导
如果你有一个具有数百万个参数的复杂模型,只要模型是可微的,损失函数相对于参数的梯度的计算就相当于编写导数的解析表达式并对其进行一次评估(evaluation)。当然,为由线性和非线性函数组成的复杂函数的导数编写解析表达式并不是一件很有趣的事情,也不是一件很容易的事情。
这个问题可以通过一个名为Autograd的PyTorch模块来解决。PyTorch张量可以记住它们来自什么运算以及其起源的父张量,并且提供相对于输入的导数链。你无需手动对模型求导:不管如何嵌套,只要你给出前向传播表达式,PyTorch都会自动提供该表达式相对于其输入参数的梯度。
1.首先,定义模型和损失函数
def model(t_u, w, b):
return w*t_u + b
def loss_fn(t_p, t_c):
squared_diffs = (t_p - t_c)**2
return squared_diffs.mean()
2.然后初始化参数张量
params = torch.tensor([1.0, 0.0], requires_grad=True)
3.require_grad = True这个参数告诉PyTorch需要追踪在params上进行运算而产生的所有张量,任何以params为祖先的张量都可以访问从params到该张量所调用的函数链。如果这些函数是可微的,则导数的值将自动存储在参数张量的grad属性中。然后调用模型,计算损失值,然后对损失张量loss调用backward
loss = loss_fn(model(t_u, *params), t_c)
loss.backward()
用一张图来形象地表示这个过程:
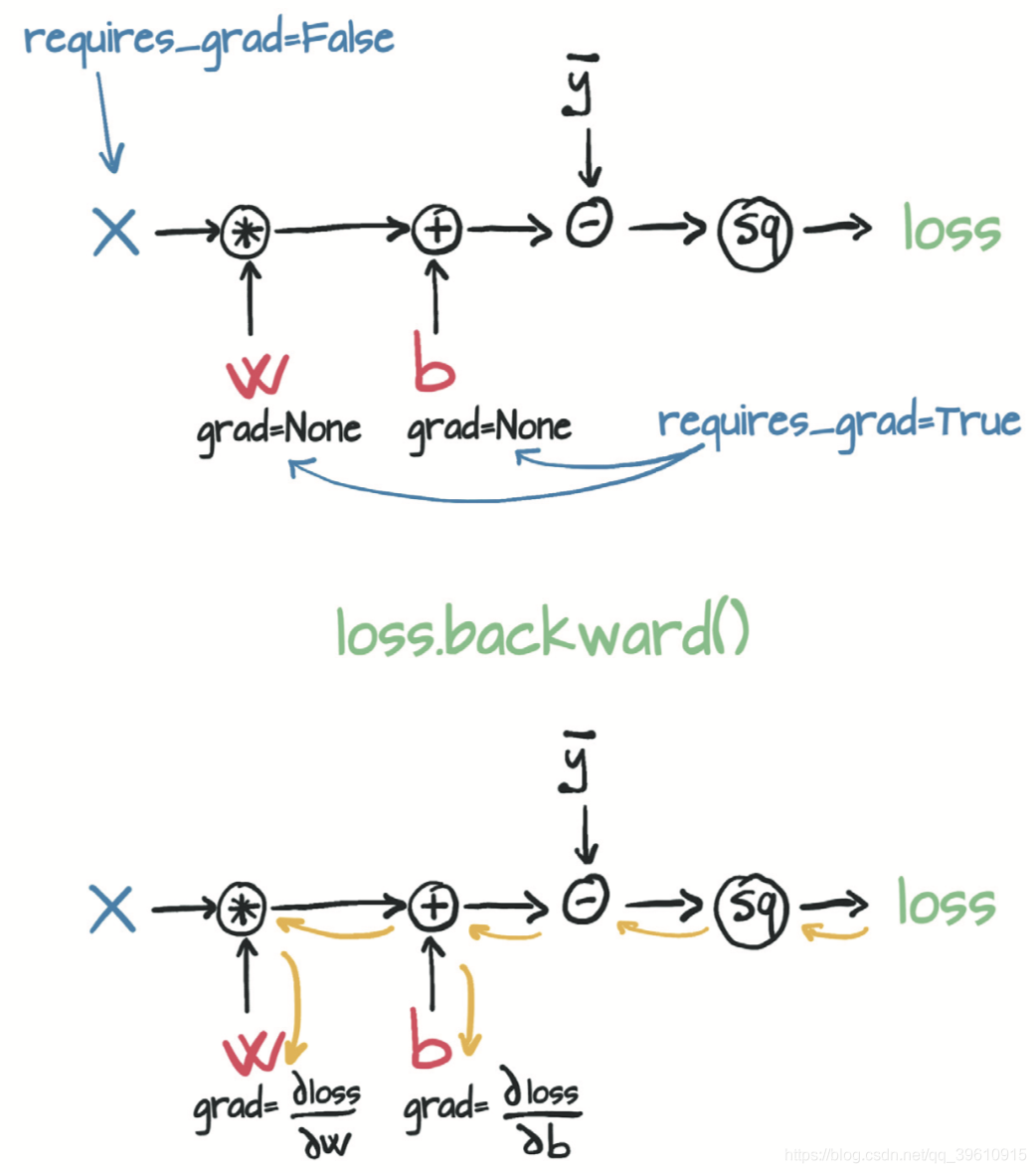
你可以将包含任意数量的张量的require_grad设置为True以及组合任何函数。在这种情况下,PyTorch会在沿着整个函数链(即计算图)计算损失的导数,并在这些张量(即计算图的叶节点)的grad属性中将这些导数值累积**(accumulate)** 起来。
重复调用backward会导致导数在叶节点处累积。因此,如果提前调用了backward,然后再次计算损失并再次调用backward(如在训练循环中一样),那么在每个叶节点上的梯度会被累积(即求和)在前一次迭代计算出的那个叶节点上,导致梯度值不正确。
为防止这种情况发生,你需要在每次迭代时将梯度显式清零。
if params.grad is not None:
params.grad.zero_()
现在来看使用了梯度下降并自动求导的完整代码:
def training_loop(n_epochs, learning_rate, params, t_u, t_c):
for epoch in range(1, n_epochs + 1):
if params.grad is not None:
params.grad.zero_grad() # 这可以在调用backward之前在循环中的任何时候完成
t_p = model(t_u, *params)
loss = loss_fn(t_p, t_c)
loss.backward()
params = (params - learning_rate * params.grad).detach().requires_grad_()
if epoch % 500 == 0:
print('Epoch %d, Loss %f' % (epoch, float(loss)))
return params
这里要说明下,detach()和requires_grad_()是干啥用的?detach()截断了反向传播的梯度流,官方文档描述为“ Returns a new Tensor, detached from the current graph.The result will never require gradient.”将某个node变成不需要梯度的Varibale。因此当反向传播经过这个node时,梯度就不会从这个node往前面传播。
为什么要调用detach呢?我们重构params参数更新行:p1 = (p0 - learning_rate * p0.grad)。这里p0是用于初始化模型的随机权重,p0.grad是通过损失函数根据p0和训练数据计算出来的。到目前为止,一切都很好。现在,你需要进行第二次迭代:p2 = (p1 - learning_rater * p1.grad)。如你所见,p1的计算图会追踪到p0,这是有问题的。因为(a)你需要将p0保留在内存中(直到训练完成),并且(b)在反向传播时不知道应该如何分配误差。应该通过调用.detatch()将新的params张量从与其更新表达式关联的计算图中分离出来。这样,params就会丢失关于生成它的相关运算的记忆。然后,你可以调用.requires_grad_(),这是一个就地(in place)操作(注意下标“_”),以重新启用张量的自动求导。现在,你可以释放旧版本params所占用的内存,并且只需通过当前权重进行反向传播。
3. 优化器
每个优化器构造函数都将参数(通常是将require_grad设置为True的PyTorch张量)作为第一个输入。传递给优化器的所有参数都保留在优化器对象内,以便优化器可以更新其值并访问其grad属性,如图所示。
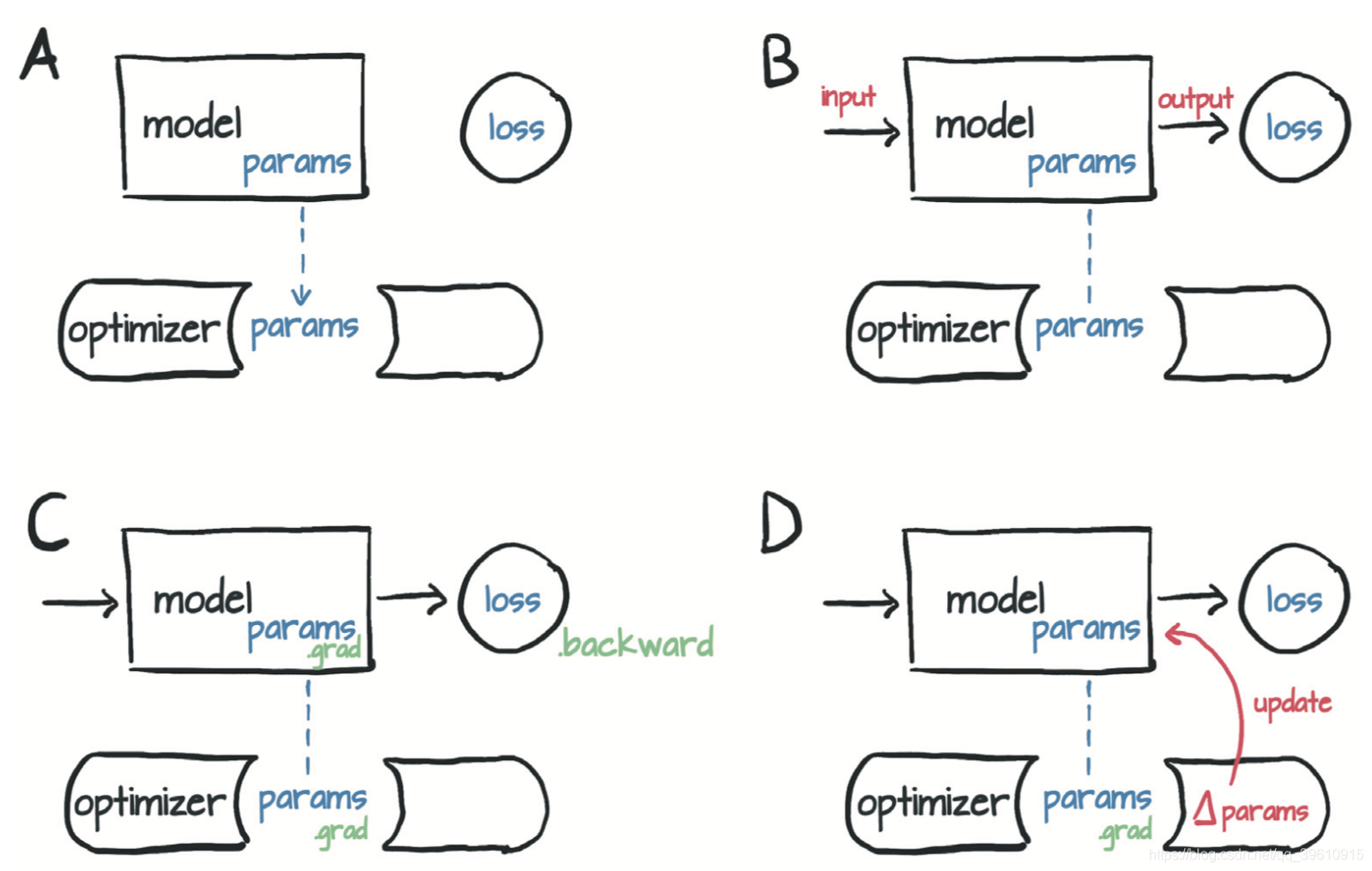
(A)优化器对参数的引用的概念表示,然后(B)根据输入计算损失,(C)对backward的调用会将grad填充到参数内。此时,(D)优化器可以访问grad并计算参数更新。
每个优化器都有两个方法:zero_grad和step。前者将构造时传递给优化器的所有参数的grad属性归零;后者根据特定优化器实施的优化策略更新这些参数的值。 现在创建参数并实例化一个梯度下降优化器:
params = torch.tensor([1.0, 0.0], requires_grad=True)
learning_rate = 1e-5
optimizer = optim.SGD([params], lr=learning_rate)
t_p = model(t_u, *params)
loss = loss_fn(t_p, t_c)
loss.backward()
optimizer.step()
调用step后params的值就会更新,无需亲自更新它!调用step发生的事情是:优化器通过将params减去learning_rate与grad的乘积来更新的params,这与之前手动编写的更新过程完全相同。
还需要注意一个大陷阱:不要忘了将梯度清零。如果你在循环中调用了前面的代码,则在每次调用backward时,梯度都会在叶节点中累积且会传播得到处都是!需要在正确的位置(在调用backward之前)插入额外的zero_grad。
完整代码如下:
import torch
import torch.optim as optim
def model(t_u, w, b):
return w*t_u + b
def loss_fn(t_p, t_c):
squared_diffs = (t_p - t_c)**2
return squared_diffs.mean()
def training_loop(n_epochs, optimizer, params, t_u, t_c):
for epoch in range(1, n_epochs + 1):
t_p = model(t_u, *params)
loss = loss_fn(t_p, t_c)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 500 == 0:
print('Epoch %d, Loss %f' % (epoch, float(loss)))
return params
if __name__ == "__main__":
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0] #摄氏度数
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4] #未知单位读数
t_c = torch.tensor(t_c)
t_u = torch.tensor(t_u)
params = torch.tensor([1.0, 0.0], requires_grad=True)
# require_grad = True这个参数告诉PyTorch需要追踪在params上进行运算而产生的所有张量
# 创建参数并实例化一个梯度下降优化器
params = torch.tensor([1.0, 0.0], requires_grad = True)
learning_rate = 1e-2
optimizer = optim.SGD([params], lr = learning_rate)
t_un = 0.1 * t_u # 标准化操作的粗略替代
training_loop(
n_epochs = 5000,
optimizer = optimizer,
params = params,
t_u = t_un,
t_c = t_c)
和前文中手写的梯度更新比较,使用了optimizer.zero_grad()后就不需要params.grad.zero_grad()了,这是为何呢?
4. 关闭autograd
现在我们将上文中的数据划分出了训练集和测试集,分别验证模型在这两个数据集上的拟合程度。

显然,我们不需要通过测试集数据来对参数进行梯度下降更新。
为了解决这个问题,PyTorch允许你通过使用torch.no_grad上下文管理器在不需要时关闭autograd。虽然就小规模问题而言,在速度或内存消耗方面没有任何有意义的优势。但是对于较大的问题,差别可能会很明显。你可以通过检查val_loss张量上require_grad属性的值来确保此上下文管理器正常工作:
def training_loop(n_epochs, optimizer, params,
train_t_u, val_t_u, train_t_c, val_t_c):
for epoch in range(1, n_epochs + 1):
train_t_p = model(train_t_u, *params)
train_loss = loss_fn(train_t_p, train_t_c)
with torch.no_grad():
val_t_p = model(val_t_u, *params)
val_loss = loss_fn(val_t_p, val_t_c)
assert val_loss.requires_grad == False
optimizer.zero_grad()
train_loss.backward()
optimizer.step()