Hello World程序
[root@mysql ~]# python3
Python 3.6.5 (default, Jul 8 2018, 11:41:23)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-18)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> print('Hello World!')
Hello World!
>>>
声明变量
变量名称定义的规则(即标识符):
做到变量名见名知意,普通变量名全部使用小写,“长量”变量名全部使用大写
- 变量名只能是字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- python中的关键字,即保留字,不能用作变量名。
Python中的保留关键字:全部是小写
|
and |
exec |
not |
|
assert |
finally |
or |
|
break |
for |
pass |
|
class |
from |
|
|
continue |
global |
raise |
|
def |
if |
return |
|
del |
import |
try |
|
elif |
in |
while |
|
else |
is |
with |
|
except |
lambda |
yield |
变量的赋值:
python是强类型语言,不需要对变量进行声明,第一次赋值时,变量的类型才会确定下来
>>> int_test = 123
>>> str_test = 'hello world!'
>>> print(int_test,str_test)
123 hello world!
注意:python中的字符串,无论何时都要使用引号引起来
python中的引用
python中有3种引用方式:单引号、双引号,三引号
单引号和双引号完全相同,没有任何区别,不像shell中不同
三引号:
示例:
>>> three_quo = '''
... hello world
... test for test
... am ok
... how are you?
... '''
>>> print(three_quo)
hello world
test for test
am ok
how are you?
>>>
可以看出,三引号中的内容在python中原样打印
预备知识
对象引用,python是面向对象的编程语言,python总一切皆对象,只有对象才有属性、方法、函数
将一个值赋给变量,称为变量对对象的引用,一旦进行了赋值,就可以通过变量来操作对象。
注意:变量是没有类型的概念的,类型是对象的一种属性,而不是变量,变量只是对对象的引用
del语句
del可以删除变量对对象的引用
del语句的语法是:
del var1[,var2[,var3[....,varN]]]
var1 = 1
var2 = 10
del var1,var2 #删除这两个引用
判断对象类型
函数:type(x), 返回x的类型,适用于所有类型的判断。
>>> type(int_test)
<class 'int'>
>>> type(str_test)
<class 'str'>
>>>
python核心数据类型
python中核心数据类型主要有5种:
Numbers(数字)、String(字符串)、List(列表)、Tuple(元组)、Dictionary(字典)
1、数字
数字属于不可变类型,不能够原位改变
python中有4种数字类型:
1)整型(python 3.x中已经将int和和long类型合并)
示例:
十进制:1010 , 99 , -217
十六进制:0x9a , 0X89 ( 0x , 0X 开头表示十六进制)
二进制:0b010,-0B101 ( 0b , 0B 开头表示二进制 )
八进制:0o123 , -0O456 ( 0o , 0O 开头是八进制 )
2)浮点型
python中的浮点数的数值范围和小数精度都存在限制,这种限制与在不同的计算机系统有关。
示例:
0.0 ,-77. ,-2.17
96e4 , 4.3e-3 , 9.6E5 ( 科学计数法 )
科学计数法使用 ‘e’ 或 ‘E’ 作为幂的符号,以10为基数
3)复数型
z = a + bj
a 是实数部分, b 是虚数部分,a和b都是浮点类型,虚数部分用 j 或 J 表示。
示例:
12.6 + 5j -7.4 - 8.3j
对于复数可以用 z.real来获得实部,z.imag来获得虚部。
上述3种数字类型存在一种逐渐“扩展”关系
整数 ——> 浮点数 ——> 复数
1.1 数字类型的转换
三种数字类型可以相互转换
函数:
int() : 把括号里的数转化为整型
float() : 把括号里的数转化为浮点型
complex() : 把括号里的数转化为复数
示例:
int(4.5) = 4 (直接去掉小数部分)
float(4) = 4.0 (直接增加小数部分)
complex(4) = 4 + 0j
complex(4.5) = 4.5 + 0j
1.2 数字类型的运算
即通过前面的运算符进行操作,数字最常用的操作符为数字运算操作符和比较运算操作符2种
>>> 1 + 5 * 6
31
>>> 1 <= 3 <= 5
True
>>>
2、字符串
字符串(String)是由数字、字母、下划线组成的一串字符
注意:
字符串是python中序列的一种
python中字符串无论何时都要位于引号中
字符串是编程语言中表示文本的数据类型(因此编程中操作文件时,如写入到文本中的都是字符串,从文本中读出来的也都是字符串)
一般记为:
s="a1a2···an"(n>=0)
python的字串序列有2种取值顺序:也就是后面要讲的分片操作
- 从左到右索引默认0(右侧第一个字符)开始的,最大范围是字符串长度减1
- 从右到左索引默认是从索引-1(左侧第一个字符)开始的,最大范围是字符串开头
- 如果头下表为空,表示从第一个字符开始,如果尾下标为空,表示最后一个字符的结尾
如果要实现从字符串中获取一段子字符串的话,可以使用变量[头下标:尾下标],就可以截取(分片)相应的字符串,其中下标可以是从0开始算起,可以是正数或负数,下标可以为空表示取到头或尾。
比如:
>>> s = 'ilovepython'
>>> s[0:3]
'ilo'
2.1 字符串的操作
2.1.1 索引、分片、连接、重复(这4个操作适用于python中所有的有序序列)

2.1.2、成员运算


2.1.3、字符串的拼接
字符串的join属性
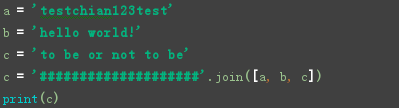

join()函数
语法:'sep'.join(seq)
参数说明
sep:分隔符可以为空
seq要连接的元素序列(对象):字符串、列表、元组、字典
上面的语法即:以sep作为分隔符,将对象中的每个元素使用seq分隔符连接
返回值:返回一个以分隔符sep连接各个元素后生成的字符串
注意:只能连接字符串,不能连接数值,因此操作元组或字典时,其元素不能含有数值,否则否则会失败,如果嵌套的是子列表或字典时也会失败(没有位于引号中,不是字符串)
示例:
seq1_str =
'hello world!'
seq2_list = ['chian', '123','for']
seq3_tup = ('chian', '123',
'for')
seq4_dict = {'name':'jack', 'sex':'male', 'color':'red'}
print('+'.join(seq1_str))
print('+'.join(seq2_list))
print('+'.join(seq3_tup))
print('+'.join(seq4_dict))

2.1.4、字符串的其他内置方法
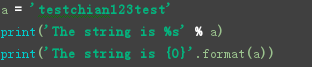
a = 'test chian123test{0},{name}-{age}'
print(a.count('t')) #统计字符串中t字符出现的次数
print(a.capitalize())
#字符串首字母大写
print(a.center(50,
'#')) #字符串两端各加50个#字符
print(a.ljust(50, '#')) #在字符串的右侧打印50个#字符
print(a.rjust(50, '#')) #在字符串的左侧打印50个#字符
print(a.endswith('st')) #判断字符串以什么结尾,返回Ture或false
print(a.startswith('t'))
#判断字符串以什么开头,返回Ture或false
print(a.expandtabs(tabsize=40)) #设定tab键为多长,即多少个空格
print(a.find('u')) #查找指定字符在字符串中第一次出现的索引,找不到返回-1
print(a.index('1'))
#类似find,如果找不到会报错
print(a.format('BOOL',name
= 'wang', age=31))
#格式化输出
c = 'test123test'
print(c.isalnum()) #判断字符串是不是字母数字混合,返回true或false
print('test'.isalpha())
#判断在字符串是不是字母,返回true或false
print('123'.isdecimal()) #判断字符串是不是十进制数字,返回true或false
print('1245'.isdigit()) #判断字符串是不是只含有数字字符,返回true或false
print('123.123'.isnumeric()) #同上,判断每个字符是否都是数字字符,返回true或false
print('2_test'.isidentifier())
#判断某个标识符是否合法,返回true或false
print('ABC'.islower())
#所有字母是否都是小写,返回true或false
print('ABC'.isupper())
#所有字母是否都是大写,返回true或false
print('abc'.upper()) #转换成大写字母
print('ABC'.lower())
#转换成小写字母
print('AbC'.swapcase())
#大小写互相转换
print('to be or not to be'.title()) #将字符串转换成标题形式(每个单词首字母大写)
print('abc'.isspace())
#是否是空格
print('abc'.isprintable())
#是否可打印
print('My Title'.istitle())
#是否是标题(标题即每个单词首字母大写)
print(' test
'.strip()) #将字符串开头和结尾的空白字符去除(空格、换行符等)
print(' test
'.lstrip()) #将字符串左侧的空白字符去除
print('
test '.rstrip()) #将字符串右侧的空白字符去除
print('abcb'.replace('b','T',1)) #将字符串中指定部分替换,默认全部替换,最后一个参数指定替换次数
print('to be or not to be'.rfind('b')) #从左向右侧开始查找指定字符的索引
print('to be or not to be'.split('or')) #将字符串已指定的分隔符分隔层层列表,将字符串转换为列表,列表转换为字符串使用join
print('to be or not to be'.rsplit('o'))
print('abc'.zfill(30)) #字符串左侧填充多少个0
b = 'testchian123test,{name}-{age}'
print(b.format_map({'name':'wang','age':31})) #类似format方法,指定参数时,必须以字典形式指定
2.2.5 格式化输出

3、列表
List(列表)是Python中使用最频繁的数据类型。
列表可以完成大多数集合类的数据结构实现。它支持字符,数字,字符串,甚至可以包含列表(即嵌套),列表可以嵌套其它任何类型。
列表用[ ]标识,是python最通用的复合数据类型。
列表中值的切割也可以用到变量[头下标:尾下标],就可以截取相应的列表,从左到右索引默认0开始,从右到左索引默认-1开始,下标可以为空表示取到头或尾。
加号+是列表连接运算符,星号*是重复操作。
列表操作:
3.1、分片(查)


3.2、增加元素
append方法,在最后插入一个元素
insert方法,在任意指定的索引位置插入1个元素


3.3、修改
列表和字典可以原位修改,而数字、字符串、元组属于不可变对象,不能原位修改


3.4、删除
remove 指定元素删除
pop 指定索引删除,如果不指定索引值,默认删除最后一个元素
clear 清空列表,列表仍然存在
del 即可删除指定的元素,也可删除列表对象,一旦删除列表对象,该对象就不再存在

pop如果不指定索引,默认删除最后一个元素





3.5、其他方法
count 方法统计某个元素在列表中出现的次数
extend 方法连接两个列表
index 查找某个元素的第一次出现的索引
reverse 反转列表;
sort 排序
in运算符,可以进行成员运算


index查找某个元素的第一次出现的索引


reverse方法,反转列表;sort方法排序


成员运算,判断某个元素是否在列表中


4、元组
元组可以看作是不可变的列表
元组用"( )"标识。内部元素用逗号隔开,如果元祖中只有一个元素,该元素后也要跟一个逗号
元组的元素同样可以是字符、数字、字符串及元组(元组同样支持嵌套)
元组属于不可变对象的属性,因此元组是不可变的
元组的操作:
1)、分片


注意:原组元素输出时使用的是圆括号,而列表元素输出时使用的是方括号
以下是元组无效的,因为元组是不可变的,不允许更改或更新某元素的值


2)、其它操作
元组只有2个方法
count 计算某个元素在元组中出现的个数
index(self, value, start=None, stop=None) 计算某个元素在元组中的索引
start和stop指定在某个索引范围内(包含start,不包含stop)查找value元素
注意:如果在指定的范围内查找不到该元素,将会报错
示例:
test_tup = ('to','be','or','not','to','be')
print(test_tup.count(test_tup[0])) #第一个元素在元组中出现的次数
print(test_tup.index('be')) #be这个元素在元组中的第一次出现的索引
print(test_tup.index('be', 1, 3)) #包含第一个索引
print(test_tup.index('be', 2, 5)) #不包含第二个索引,将会报错

5、字典
字典(dictionary)是除列表以外python之中最灵活的内置数据结构类型,是python中唯一一种映射类型,采用key-value形式存储数据,字典中key必须唯一。
key必须是可hash的,可hash表示key必须不可变类型(不能原位修改),如数字,字符串,元组,
而value也可任意嵌套
列表是有序的对象集合;字典是无序的对象集合
二者相同点:都属于可变对象的属性,都能够原位改变
二者的不同点:字典中的元素是通过键key来存取的(因此不能分片),而列表通过索引存取(可分片)
字典用"{ }"标识,字典由索引(key)和它对应的值value组成。 key:value
字典相关的操作:
1)、增、改、查
values 打印字典中所有的值value,列表形式返回
keys 打印字典中所有的key列表形式返回
items 同时打印字典中所有的key和value,key和value组成元组,以列表形式返回
test_dic = {'name':'jack','age':'23'}
print(test_dic)
test_dic['hooby'] = 'footabll' #增加一个字典元素
print(test_dic)
test_dic['hooby'] = 'basketball' #修改一个字典元素
print(test_dic)

test_dic = {'name':'jack','age':'23'}
test_dic2 = {'work':'teacher','national':"China"}
test_dic.update(test_dic2)
#合并两个字典,如果test_dic2中含有和test_dic中相同的key,将会覆盖test_dic1中的key和对应的value
print(test_dic)

test_dic = {'name':'jack','age':'23'}
print(test_dic['age']) #打印出指定的key的对应的value
print(test_dic.get('age')) #根据给定key返回value
print(test_dic.get('age')) #根据给定key返回value
test_dic.setdefault('hobby','football') #查找字典中是否有hobby的key,如果没有,增加这个key,并指定value为footabll,不指定value默认为None,如果有这个key则什么也不做
print(test_dic)
test_dic.setdefault('hobby','basketbool') #字典中已经有hobby这个key,因此什么也不做
print(test_dic)

test_dic = {'name':'jack','age':'23'}
print(test_dic.keys()) #打印所有的key,返回列表
print(test_dic.values())
#打印所有的value,返回列表
print(test_dic.items()) #成对打印key和value,返回列表

2)、删除
clear 清空字典中的所有元素,字典成为空字典
pop 根据key值清除字典中的元素(必须指定key),并返回清除的key对应的value
del 即可清除字典中的某个元素,也可清除字典对象
popitem 随机清除一个字典元素
test_dic3 = {'work':'teacher','national':"China",'name':'jack'}
print(test_dic3.pop('national')) #清除这个national这个元素,并返回这个key对应的value
print(test_dic3)
print(test_dic3.popitem()) #随机清除一个元素,并以元组形式返回(‘k’, ’v’)
print(test_dic3)
# del test_dic3['name'] #清除name这个元素
# print(test_dic3)
# del test_dic3 #删除test_dic3这个字典对象,后面不能再操作这个对象,否则报错
#print(test_dic3)
#将会报错

3)、创建字典并为所有key赋予同一个初始值


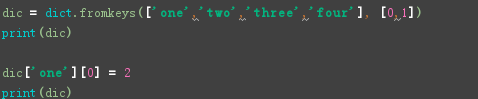

注意:修改后的效果,每个字典元素的第二个元素都被修改
4)、排序,字典的排序默认是按照key进行排序的
注意:字典没有专用于排序的方法,只能使用内建的sorted函数进行排序
sorted(dic) #默认按升序进行排序
sorted(dic, reverse=True) #按降序排序


5)、字典的遍历
test_dic = {'name':'jack','age':'23','color':'red','national':'China'}
for i in test_dic: #默认是根据key进行循环,并打印
print(i)
print()
for i in test_dic.keys(): #明确指定根据key循环,并打印
print(i)
print()
for i in test_dic.values(): #明确指定根据value循环,并打印
print(i)
print()
for i,v in test_dic.items():
#明确指定是根据key和value进行循环,并打印
print(i, ':',v)

小结:
序列:字符串、列表、元组
非序列:数值、字典
可变对象:列表、字典
不可变对象:数值、字符串、元组
6、文件
文件操作模式:
|
模式 |
描述 |
|
r |
以只读方式打开文件。文件的指针放在文件的开头,默认模式。 |
|
rb |
以二进制格式打开一个文件用于只读。文件指针放在文件的开头。默认模式。 |
|
r+ |
打开一个文件用于读写,文件指针放在文件的开头。 |
|
rb+ |
以二进制格式打开一个文件用于读写。文件指针放在文件的开头。 |
|
小结:只要是与r相关的模式操作,打开文件后,文件指针总是放在文件的开头处 |
|
|
w |
打开一个文件只用于写入。如果该文件已存在,则清除文件中的内容。如果该文件不存在,创建新文件。 |
|
wb |
以二进制格式打开一个文件只用于写入。如果该文件已存在,则清除文件中的内容。如果该文件不存在,创建新文件。 |
|
w+ |
打开一个文件用于读写。如果该文件已存在,则清除文件中的内容。如果该文件不存在,创建新文件。 |
|
wb+ |
以二进制格式打开一个文件用于读写。如果该文件已存在,则清除文件中的内容。如果该文件不存在,创建新文件。 |
|
小结:只要是与w相关的操作,若文件事先存在,打开文件后总会先清空文件的内容,若文件不存在则创建文件 |
|
|
a |
打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。 也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
|
ab |
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。 也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
|
a+ |
打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。 文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
|
ab+ |
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。 如果该文件不存在,创建新文件用于读写。 |
|
小结:只要是与a相关的操作,如果文件事先存在,打开文件后不会清空文件,并将文件的指针放在文件的最后; 若文件不存在将会创建文件,因为是新建的空文件,指针在开头处 |
|
对数据文件的操作是Python的内置模块,只要使用open函数,根据文件的打开模式,获取到文件的句柄,就可以对文件进行读、写、追加操作。语法形式如下:
方式一:fp = open('文件名', '文件打开模式')
方式二:with open('文件名') as fp:
如果打开了文件之后就不再处理该文件了,那么使用with语句可以使程序编写得更为简洁,离开with之后,系统自动会关闭文件,就不需要使用fp.close()去手动关闭文件
testfile2测试文件内容:
fp:打开文件的句柄,对文件的操作就是对文件句柄的操作,有以下操作方法:
fp.read([size]) size字符串的索引值,不包括自身size,即打印索引值为0-(seze-1)个字符


fp.readline([size]) 同上,seize是字符串索引值,不包括自身
示例:
fp = open('testfile2','r',encoding='utf-8')
print(fp.readline(6)) #打印后文件指针将移动到第六个字符后
fp.seek(0)
#将文件指针移动到文件开头
print(fp.readline())

fp.readlines([size]) 把文件每一行作为一个list的一个成员,并返回这个list。其实它的内部是通过循环调用readline()来实现的。size同样为字符串索引值,不包括自身;只要size位于某一行字符的索引范围内,该行就会被打印出来
示例:
fp = open('testfile2','r',encoding='utf-8')
print(fp.readlines())
fp.seek(0)
print(fp.readlines(7))
fp.seek(0)
print(fp.readlines(8))

fp.write(str) 把str写到文件中并返回写入的字符个数,write()并不会在str后自动加上一个换行符
示例:
fp = open('testfile2','w',encoding='utf-8')
print(fp.write("hello world!")) #原文件将会被清空,然后写入这里的字符串


fp.writelines(seq) 把seq的内容全部写到文件中(多行一次性写入)。这个函数也只是忠实地写入,不会在每行后面加上任何东西。
示例:
fp = open('testfile2','w',encoding='utf-8')
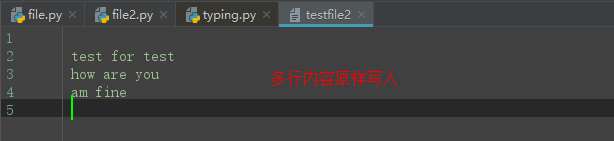
msg = '''
test for test
how are you
am fine
'''
print(fp.writelines(msg)) #将多行原样写入,返回None

fp.close() 关闭文件,使用open函数打开一个文件后不会自动关闭,因此如果使用open函数,书写时一定要同时写出close函数,然后再在二者之间书写文件操作语句。如果一个文件在关闭后还对其进行操作会产生ValueError
fp.flush() 有时向文件中写入字符串时,会暂时将内容存储在内存的缓冲区中,并不会立即写到磁盘文件上,使用该指令将会把缓冲区的内容写入硬盘
fp.fileno() 返回一个整型的文件描述符(file descriptor FD整型),可用于底层操作系统的 I/O 操作
fp.isatty() 文件是否是一个终端设备文件(unix系统中一切皆文件,终端设备也是文件)
fp.tell() 返回光标的当前位置(按字节计算),以文件的开头为原点
fp = open('testfile2','r',encoding='utf-8')
fp.seek(0)
print(fp.readline(2))
print(fp.tell())

fp.next() 返回下一行,并将光标移动到下一行,python 3.x中该函数更改为__next__
把一个file用于for … in file这样的语句时,就是调用next()函数来实现遍历的。
fp.seek(offset[,whence]) 将光标移到offset位置(和tell类似,也是按照字节计算)。这个offset一般是相对于文件的开头来计算的,一般为正数。但如果提供了whence参数就不一定了。
whence可以取值为:
0表示从头开始计算(默认)。
1表示以当前位置为原点计算。
2表示以文件末尾为原点进行计算。
注意:如果文件以a或a+的模式打开,每次进行写操作时,文件操作标记会自动返回到文件末尾。
fp.truncate([size]) 使用该函数,文件必须可写,返回当前光标所在索引位置。size是截取的文件大小,按字节截取,(无论光标再何处)总是从文件的开头开始截取。
如果size比文件的大小还要大,依据系统的不同可能是不改变文件,也可能是用0把文件补到相应的大小,也可能是以一些随机的内容加上去
with语句:
with open('testfile1','r+',encoding='utf-8')
as fp1, open('testfile2','r+') as fp2: #同时操作多个文件使用逗号间隔
print(fp1.readlines())
print(fp2.readlines())
#操作完成后,不需要手动关闭文件,会自动关闭

7、集合
把不能的元素组合在一起,无序,成员不可重复
组成集合的成员唯一不能重复
集合中的成员是一组无序排列的可哈希的值(即唯一):因此集合的成员可作为字典的key
集合的创建:
st = 'china'
li = [1, 2, 'a', 'b', 'c']
tu = (1, 2, 'a','b','c')
se1 = set(st)
#set()函数可用于将序列转换为集合,若序列中有重复,将会去重
se2 = set(li)
se3 = set(tu)
print(se1, se2, se3)
# dic = {se1:1, se2:2, se3:3}
#会报错,可变集合本身不能作为字典的key
# print(dic)

集合分类:可变集合、不可变集合
可变集合:可以添加和删除元素,不可hash,不能用作字典的key,也不能作为其它集合的元素,
注意:这里的可变指的是集合本身,而不是指集合中的成员,因此可变集合本身不能作为字典的key,因为其是不可hash的
不可变集合(frozenset):与上述相反
不可变集合的创建:
str2 = 'test for test'
li2 = ['a', 'b', 'c', 1, 2]
tu2 = ('a', 'b', 'c', 1, 2)
fse1 = frozenset(str2) #创建不可变集合
fse2 = frozenset(li2)
fse3 = frozenset(tu2)
print(fse1)
print(fse2)
print(fse3)
dic2 = {fse1:1, fse2:2, fse3:3} #不可变集合本身可作为字典的key
print(dic2)

1)、访问集合:
集合本身是无序的,不能通过索引取值,又没有字典的key,因此也不能通过类似字典的方式取值。
只能通过循环遍历或使用in、not in来访问或判断几何元素
li = [1, 2, 'a', 'b', 'c', 'c']
se1 = set(li)
print('a' in se1)
print('b' not in se1)
for i in se1:
print(i, end=' ')

2)、更新集合(针对可变集合)
li = ['t', 'n', 'a', 'b', 'c', 'c']
s = set(li)
print(s)
s.add('uuuID') #uuuID作为一个整体添加到集合s中
print(s)
s.update('uuuID') #将uuuID当作一个序列添加到集合s中,因此会将u、I、D添加到集合中
print(s)
s.update(['o','i','p', 'a',
'b']) #update的参数必须是一个可迭代的序列,可以是列表、字符串、元组
print(s)
s.remove('uuuID') #删除集合中的uuuID元素
print(s)
s2 = s.pop() #pop随机删除一个集合元素,并返回被删除的元素
print(s,
s2)
s.clear() #清空集合
print(s)
del s #删除集合
#print(s) #将会报错

s.discard(x) 如果在set “s”中存在元素x, 则删除
集合相关的操作:
1、in、not in 成员运算
2、集合等价与不等价(==,!=)
3、子集、超集
4、并集、交集、差集、对称差集(反向差集)
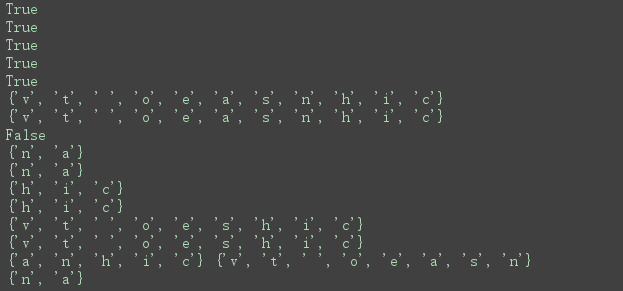
s = set('to be or not to be')
s1 = set('be')
print('t' in s) #成员关系
print(s1 < s) #子集运算
print(s1.issubset(s) ) #子集运算
print(s > s1) #超集运算
print(s.issuperset(s1)) #超集运算
s1 = set('china')
s2 = set('test nova')
print(s1 | s2) #并集运算
print(s1.union(s2)) #并集运算
print(s1.isdisjoint(s2)) #判断两个集合是否不相交,如果2个集合交集为空,返回True
print(s1 & s2) #交集运算
print(s1.intersection(s2)) #交集运算
print(s1 - s2) #差集,s1中有,s2中没有
print(s1.difference(s2)) #差集,s1中有,s2中没有
print(s1 ^ s2) #对称差集,s1、s2不重复的元素,s1&s2的补集
print(s1.symmetric_difference(s2)) #对称差集,s1、s2不重复的元素,s1&s2的补集
print(s1,s2)
#
s1.difference_update(s2) #s1对s2进行差集操作的结果更新s1,返回值为None
#
print(s1)
#
s1.symmetric_difference_update(s2) #s1对s2进行反向差集操作的结果更新s1,返回值为None
#
print(s1)
s1.intersection_update(s2) #s1对s2进行交集操作的结果更新s1,返回值为None
print(s1)
深浅copy
知识补充:
a = 2
b = a #a和b分别指向了同一块内存空间,
a = 1 #因此,修改a的值不会影响b的值
print(a,b) #结果是:1 2
a = [1, 3, 4]
b = a #b同样和a指向了同一块内存空间,但是这里指向的是整个列表的内存空间,如果修改
#a的值,b的也会跟着变,因为b仅指向整个列表的空间,并没有指向内部元素的内存空间
#此时,a和b共享同一块内存,b可看作是a的别名,
#这种情况同样适用于其它复杂数据类型,不仅仅是列表
a[1] = 'test'
#修改a[1]的值
print(a,b) #结果相同,都被修改

浅copy与上述类似
在Python中对象的赋值其实就是对象的引用。当创建一个对象,把它赋值给另一个变量的时候,python并没有拷贝这个对象,只是拷贝了这个对象的引用而已。
浅拷贝:拷贝了最外围的对象本身(即第一层),内部的元素都只是拷贝了一个引用而已。也就是,把对象复制一遍,但是该对象中引用的其他对象我不复制
深拷贝:外围和内部元素都进行了拷贝对象本身,而不是引用。也就是,把对象复制一遍,并且该对象中引用的其他对象我也复制
必要说明:
变量:是一个系统表的元素,拥有指向对象的连接空间
对象:被分配的一块内存,存储其所代表的值
引用:是自动形成的从变量到对象的指针
注意:类型(int类型,long类型(python3已去除long类型,只剩下int类型的数据))属于对象,不是变量
不可变对象:一旦创建就不可修改的对象,包括字符串、元组、数字,不能够原位修改
可变对象:可以修改的对象,包括列表、字典,可以原位修改
切片可以应用于:列表、元组、字符串,但不能应用于字典(因为切片是跟索引进行的,字典没有索引)。
深浅拷贝:既可应用序列(列表、元组、字符串),也可应用字典。
不可变类型,不管是深拷贝还是浅拷贝,地址值和拷贝后的值都是一样的
可变对象深浅拷贝:
=拷贝:值相等,地址相等,整个对象
copy浅拷贝:值相等,地址不相等,整个对象及对象内的第一层
deepcopy深拷贝:值相等,地址不相等,整个对象及对象内的所有层
深copy:
深拷贝需要调用copy模块中的deepcopy函数,另外,copy模块中含有个copy函数(实际就是浅copy)