《Linux内核原理与分析》
视频学习及实验操作
Linux内核源代码
视频中提到了三个我们要重点专注的目录下的代码,一个是arch目录下的x86,支持不同cpu体系架构的源代码;第二个是init目录下的main.c,是整个linux内核启动的起点,不过这里面不是main()函数,而是start_kernel,start_kernel函数相当于普通c程序的main函数,linux内核的核心代码在kernel目录中;最后是kernel 下进程调度相关的代码。
构造一个简单的Linux系统MenuOS
使用实验楼的虚拟机打开shell,输入命令,启动MenuOS系统:
cd LinuxKernel/
qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img

内核启动完成后进入menu程序,在qemu窗口下输入help,发现这个系统支持三个命令:help、version、quit:

使用gdb跟踪调试Linux内核的方法
qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img -s -S
关于-S -s选项的说明:
-S freeze CPU at startup (use ’c’ to start execution)
表示CPU开始初始化之前将其冻结,目的是阻止cpu执行接下来的指令
-s shorthand for -gdb tcp::1234
在tcp1234窗口上创建一个gdbserver作为通讯;若不想使用1234端口,则可以使用-gdb tcp:xxxx来取代-s选项
使用-S 之后,系统开始启动,qemu显示stopped,表示cpu已被冻结。
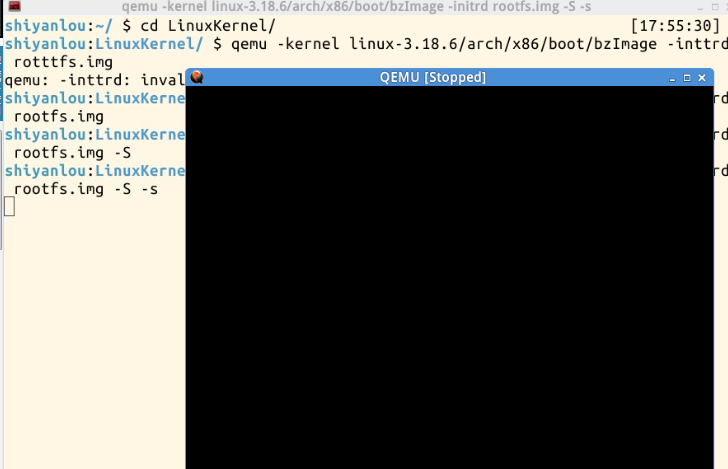
再打开另一个shell窗口,右键-水平分割,启动gdb来跟踪调试。输入:
file linux-3.18.6/vmlinux
target remote:1234
通过刚刚设置的端口号建立gdb和gdbserver之间的连接,我理解的是将下面这个窗口和上面冻结的窗口建立联系。接下来通过break设置断点,现在在内核启动的起点start_kernel函数处设置一个断点:
break start_kernel
我们可以通过按c,让冻结的qemu上的linux继续运行,此时发现,系统运行了一些命令在breakpoint1 start_kernel处停下了,说明断点设置有效。
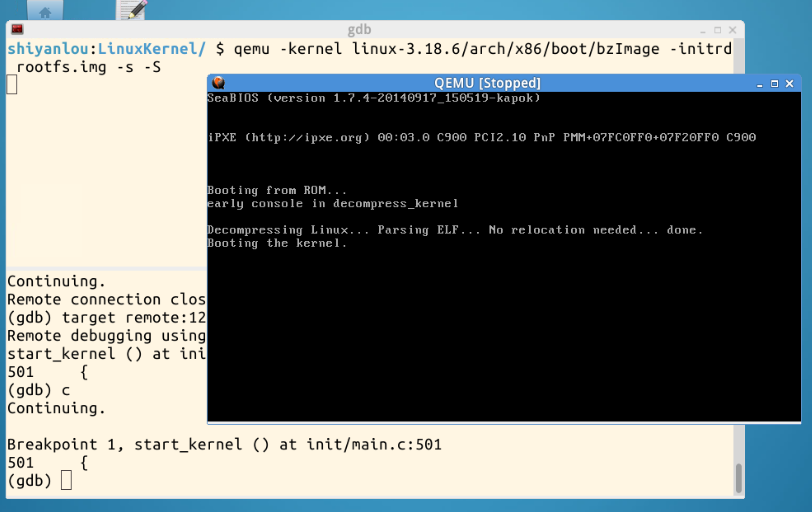
同理可以设置第二个第三个断点,按c继续执行。
简单分析start_kernel
start_kernel在init目录下的main.c,整个start_kernel,就完成调用一系列的初始化函数,完成内核本身的设置:设置与体系结构相关的环境、进程调度器初始化、内存初始化等各种初始化。在Start_kernel函数的最后调用了rest_init()函数,在rest_init中建立了init线程,并在最后调用cpu_idle()函数。
对于视频中讲述的道生一,一生二,二生三,三生万物,我不是特别理解。从网上查了一下PID 0(idle), 1(init), 2(kthreadd)3个进程,有了大概的认识:
(1)init_task(0号进程的前世)在创建了init进程后,就变成了idle进程(0号进程的今生),执行一次调度后,切换当前进程到init;
(2)kernel_init(1号内核线程)执行内核的部分初始化工作及进行系统配置,变成了init用户进程;
(3)init_task(0号进程)又创建了Kthreadd内核线程(2号进程),它的任务是管理和调度其他内核线程kernel_thread, 会循环执行一个kthread的函数
教材第四章 进程调度
进程调度程序,是确保进程能有效工作的内核子系统。本章介绍了调度程序设计的基础和完全公平调度程序如何运用、如何设计、如何实现以及与它相关的系统调用。
4.1 多任务
多任务操作系统就是能同时并发地交互执行多个进程的操作系统。无论单处理器或者多处理器及其上,多任务操作系统都能使多个进程处于堵塞或者睡眠状态。
多任务系统划分为两类:非抢占式多任务和抢占式多任务。由调度程序决定什么时候停止一个进程的运行,以便其他进程能得到执行机会,这个强制的挂起动作叫抢占;相反,在非抢占式多任务模式下,除非进程自己主动停止运行,否则会一直执行下去,这个主动的挂起动作叫让步。 进程在被抢占之前能够运行的时间是预先设置好的,叫进程的时间片。
4.2 Linux的进程调度
O(1)调度器:对于大服务器的工作负载很理想,但缺少交互进程。
完全公平调度算法(CFS):“RSDL”,吸取了队列理论,将公平调度的概念引入Linux调度程序。
4.3 策略
策略决定调度程序在何时让什么进程运行,负责优化使用处理器时间。
4.3.1 I/O消耗型和处理器消耗型的进程
I/O消耗型:进程的大部分时间用来提交I/O请求或者等待I/O请求,经常处于可运行状态但是运行时间很短,等待更多的请求时最后总会阻塞。
处理器消耗型:把时间大多用在执行代码上,除非被抢占,否则通常都会不停运行。对于这类处理器消耗型的进程,调度策略通常会降低它们的调度频率,而延长其运行时间。
调度策略通常要在两个矛盾的目标中间寻找平衡:
·进程响应迅速(响应时间短);
·最大系统利用率(高吞吐量)
4.3.2 进程优先级
调度算法最基本的是基于优先级的调度,根据进程的价值和其对处理器时间的需求来对进程分级。通常按照优先级高低来运行,相同优先级的进程按轮转方式进行调度。
·nice值:
范围[-20,19],默认值为0;
nice值越大,优先级越低;
Linux系统中nice值代表时间片的比例;
ps-el命令查看系统中进程列表,NI列为nice值。
·实时优先级:
默认范围[0,99],值可以配置,;
值越高,优先级越高;
任何实时进程的优先级都高于普通的进程。
通过命令:
ps-eo state,uid,pid,ppid,rtprio,time,comm
查看到你系统中的进程列表,进程列表“-”说明它不是实时进程。
4.3.3 时间片
时间片是一个数值,是进程在被抢占前所能持续运行的时间。I/O消耗型不需要很长的时间片,而处理器消耗型的进程则希望越长越好。
Linux系统是抢占式的,是否要抢占当前进程,是完全由进程优先级和是否有时间片决定的。
CFS调度器:其抢占时机取决于新的可运行程序消耗了多少处理器使用比。
Linux调度算法
4.4.1 调度器
Linux调度器以模块方式提供,允许多种不同的可动态添加的调度算法并存,调度属于自己范畴的进程。每个调度器有一个优先级,会按照优先级顺序遍历调度类,选择优先级最高的调度器类。
完全公平调度CFS是一个针对普通进程的调度类。
4.4.3 公平调度
CFS做法允许每个进程运行一段时间、循环轮转、选择运行最少的进程作为下一个运行进程,不再给每个进程分配时间片。在所有可运行进程总数基础上计算出一个进程应该运行多久。nice值作为进程获得的处理器运行比的权重。
4.5 Linux调度的实现
CFS调度算法实现的四个组成部分:
(一)时间记账
(二)进程选择
(三)调度器入口
(四)睡眠和唤醒
(一)时间记账
所有的调度器都必须对进程运行时间做记账。CFS不再有时间片的概念,但要使用调度器实体结构(定义在文件<linux/sched>的struct_sched_entity中)来追踪记账,进程描述符中的se变量。
CFS使用vruntime变量来记录一个程序到底运行了多长时间以及它还应该再运行多久,定义在kernel/sched_fair.c文件中的update_curr()函数实现了该记账功能,update_curr()计算了当前进程的执行时间,并且将其存放在变量delta_exec中。
_update_curr(cfs_rq, curr, delta_exec)
update_curr()是由系统定时器周期性调用的,根据这种方式,vruntime可以准确地测量给定进程的运行时间。
(二)进程选择
CFS调度算法的核心是选择具有最小vruntime的任务,CFS使用rbtree来组织可运行进程队列,并利用其迅速找到最小vruntime值的进程。rbtree是一个自平衡二叉搜索树,是一种以树节点形式存储的数据,这些数据会对应一个键值,可以通过这些键值来快速检索节点上的数据,而且检索速度与整个树的节点规模成指数比关系。
挑战下一个任务:CFS运行rbtree树中最左边叶子节点所代表的那个进程。实现这一函数是__pick_next_entity():
这个函数不会遍历树找到最左叶子节点,该值缓存在rb_leftmost字段中,
函数返回值就是CFS选择的下一个运行进程。
如果返回NULL,表示树空,没有可运行进程,这时选择idle任务运行。
向树中加入进程:发生在进程被唤醒或者通过fork调用第一次创建进程时:
函数enqueue_entity():更新运行时间和其他一些统计数据,然后调用__enqueue_entity();
函数__enqueue_entity():进行繁重的插入工作,把数据项真正插入到rbtree中:
(把一个调度实体插入到rbrtree中)
static void _enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
从树中删除进程:删除动作发生在进程堵塞或终止时。和给红黑树添加进程一样,实际工作由辅助函数dequeue_entity()和__dequeue_entity()完成。
(三)调度器入口
进程调度的主要入口点函数是schedule():
schedule()函数会调用pick_next_task();
pick_next_task()会以优先级为序依次检查每一个调度类,并且选择最高优先级的进程;
pick_next_task()会返回指向下一个可运行进程的指针,没有时返回NULL;
pick_next_task()函数实现会调用pick_next_entity();
pick_next_entity()会调用__pick_next_entity()
(四)睡眠和唤醒
睡眠: 进程把自己标记成休眠状态,从可执行rbtree中移出,放入等待队列,然后调用schedule()选择和执行一个其他进程;
进程通过执行以下几个步骤将自己加入到一个等待队列中:
1)调用宏DEFINE_WAIT()创建一个等待队列的选项。
2)调用add _ wait _ queue()把自己加入队列中。
3)调用prepare _ to _ wait()方法将进程的状态变更为TASK _ INTERRUPTIBLE或TASK _ UNINTERRUPTIBLE(休眠)。
4)如果状态被设置成TASK_INTERRUPTIBLE,则信号唤醒进程。(伪唤醒:唤醒不是因为事件的发生。)
5)当进程被唤醒的时候,会再次检查条件是否为真,真则退出循环,否则再次调用schedule()并且一直重复这步动作。
6当条件满足后,进程将自己设置为TASK _ RUNNING并调用finish _ wait()方法把自己移出等待序列。函数inotify _ read():负责从通知文件描述符中读取信息。
唤醒:进程被设置为可执行状态,然后再从等待队列中移到可执行rbtree中。
4.6 抢占和上下文切换
上下文切换由context _ switch()函数负责,每当一个新进程被选出准备投入运行时,schedule()会调用context _ switch()。
它完成了两项基本工作:
·调用switch_mm(),该函数负责把虚拟内存从上一个进程映射到新进程中。
·调用switch _ to(),该函数负责从上一个进程的处理器状态切换到新进程的处理器状态。
这包括保存、恢复栈信息和寄存器信息,还有其他任何与体系结构相关的状态信息,都必须以每个进程为对象进行管理和保存。
抢占分为用户抢占和内核抢占。用户抢占都用到need_resched,会导致schedule()被调用,切换到新进程;而内核抢占,受Linux完整的支持,即调度程序没有办法在一个内核级的任务正在执行的时候重新调度。
内核的抢占:
1、为每个进程的thread _ info中引入preempt _ count计数器,初值为0,使用锁+1,释放锁-1,数值为0时,内核可执行抢占。
2、从中断返回内核空间时,先检查need_resched标志,如果被设置表示需要被调度,然后检查preempt_count计数器,如果为0,表示可以被抢占,这时调用调度程序。否则,内核直接从中断返回当前执行进程。
3、当前进程持有的锁全部被释放,这时preempt_count重新为0,释放锁的代码会检查need_resched是否被设置,如果是就调用调度程序。
4、如果内核中的进程被阻塞了,或它显式地调用了schedule(),内核抢占也会显式地发生。
4.7 实时调度策略
Linux提供了两种实时调度策略:SCHED _ FIFO和SCHED _ RR:
SCHED _ FIFO是一种先入先出的调度算法,不使用时间片,该进程一旦处于可执行状态,就会一直执行,直到受阻或显示释放处理器;
SCHED _ RR是带有时间片的实时轮流调度算法,该进程在耗尽实现分配给它的时间后就不再继续执行。
优先级范围
实时:0~[MAX _ RT _ PRIO-1]
默认MAX _ RT _ PRIO=100,所以默认实时优先级范围为[0,99]
SCHED _ NORMAL:[MAX _ RT _ PRIO]~[MAX _ RT _ PRIO+40]。
默认情况下,nice值从-20到+19对应的是从100到139的实时优先级范围。
4.8与调度相关的系统应用
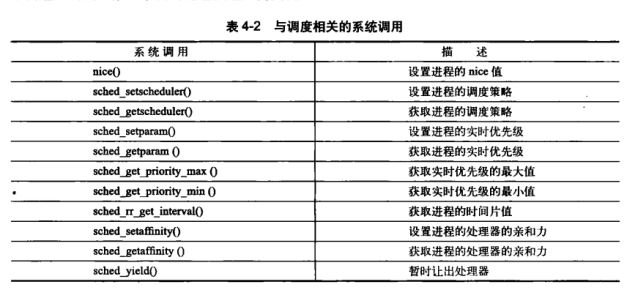
放弃处理器时间:
sched_yield() 让进程显式地将处理器时间让给其他等待执行进程。普通进程移到过期队列中,实时进程移到优先级队列最后。
内核先调用yield,确定给定进程确实处于可执行状态,然后调用sched _ yield()。
用户空间可以直接调用sched _ yield()。
教材第六章 内核数据结构
对于数据结构的知识,之前大学本科没有接触过,结合教材和网上资料,谈谈自己的认识。内核数据结构贯穿于整个内核代码中,利用这4个基本的数据结构,可以在编写内核代码时节约大量时间。
本章主要讲述了数据结构中最有用的四个:
*链表
*队列
*映射
*二叉树
链表
通过对比内核链表和传统链表,可以发现,内核链表更好的解决了传统链表不好共通化的问题:
(1)在传统双向链表中,每个节点(node)除了包含2个指针(pre,next),还包含必要的数据,这些数据存在每个节点中,最大的缺点就是不好共通化;
(2)linux的链表不是将用户数据保存在链表节点中,而是将链表节点保存在用户数据中。
linux的链表节点只有2个指针(pre和next),这样的话,链表的节点将独立于用户数据之外,便于实现链表的共同操作。


队列
内核中的队列是以字节形式保存数据的,所以获取数据的时候,需要知道数据的大小。Linux内核通用队列实现成为kfifo,它实现在kernel/kfifo.c中,内核中关于队列定义的头文件位于:<linux/kfifo.h> include/linux/kfifo.h。kfifo提供两个主要操作:enqueue(入队列)和dequeue(出队列),kfifo对象维护了两个偏移量:入口偏移和出口偏移两个偏移量。
内核队列编程需要注意的是:
1、队列在初始化时,size始终设定为2的n次幂
2、使用队列之前将队列结构体中的锁(spinlock)释放
映射
Linux内核提供了简单、有效的映射数据结构,有点想像他语言(C#或者python)中的字典类型,每个唯一的UID对应到一个指针。映射的使用需要注意的是,给自定义的数据结构申请一个id的时候,不能直接申请id,先要分配id(函数idr_pre_get),分配成功后,在获取一个id(函数idr_get_new)。
红黑树
红黑树或许遵循起来比较简单,但一系列规则看起来比较复杂,其插入,删除性能也还不错。红黑树中最长的路径就是红黑交替的路径,最短的路径是全黑节点的路径,再加上根节点和叶子节点都是黑色,
从而可以保证红黑树中最长路径的长度不会超过最短路径的2倍。内核中关于红黑树定义的头文件位于:<linux/rbtree.h> include/linux/rbtree.h
头文件中定义的函数的实现位于:
lib/rbtree.c
之前没有学过数据结构,教材中的代码我不是很看得懂,网上搜到一些资料,对于红黑树的定义和宏定义,有了一定的认识。
参考博客:内核数据结构(红黑树)
总结:
本章学习内核数据结构第一次接触,速度有点慢,尤其红黑树,宏定义这些理解起来比较慢,花费时间比较长,要加强数据结构的学习。
问题与反思:
1、在另一个shell中输入命令
target_remote:1234
为什么会出现连接超时?因为在上一个gdb中,生成的冻结窗口被自己关闭了,要重新-s -S打开 qemu(stopped)冻结窗口,重新输入命令,设置断点,继续执行。
2、TASK_INTERRUPTIBLE接受到一个信号,会被提前唤醒并响应该信号,和TASK_RUNNING的关系区别?
TASK_INTERRUPTIBLE接受信号,提前唤醒但并不执行,其任务是不可行的;而TASK_RUNNING接收到信号,任务是可行的,再调用active_task()把任务加到运行队列。